溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Go如何實現安全的雙檢鎖”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Go如何實現安全的雙檢鎖”文章吧。
從其他語言轉入Go語言的同學經常會陷入一個思考:如何創建一個單例?
有些同學可能會把其它語言中的雙檢鎖模式移植過來,雙檢鎖模式也稱為懶漢模式,首次用到的時候才創建實例。大部分人首次用Golang寫出來的實例大概是這樣的:
type Conn struct {
Addr string
State int
}
var c *Conn
var mu sync.Mutex
func GetInstance() *Conn {
if c == nil {
mu.Lock()
defer mu.Unlock()
if c == nil {
c = &Conn{"127.0.0.1:8080", 1}
}
}
return c
}這里先解釋下這段代碼的執行邏輯(已經清楚的同學可以直接跳過):
GetInstance用于獲取結構體Conn的一個實例,其中:先判斷c是否為空,如果為空則加鎖,加鎖之后再判斷一次c是否為空,如果還為空,則創建Conn的一個實例,并賦值給c。這里有兩次判空,所以稱為雙檢,需要第二次判空的原因是:加鎖之前可能有多個線程/協程都判斷為空,這些線程/協程都會在這里等著加鎖,它們最終也都會執行加鎖操作,不過加鎖之后的代碼在多個線程/協程之間是串行執行的,一個線程/協程判空之后創建了實例,其它線程/協程在判斷c是否為空時必然得出false的結果,這樣就能保證c僅創建一次。而且后續調用GetInstance時都會僅執行第一次判空,得出false的結果,然后直接返回c。這樣每個線程/協程最多只執行一次加鎖操作,后續都只是簡單的判斷下就能返回結果,其性能必然不錯。
了解Java的同學可能知道Java中的雙檢鎖是非線程安全的,這是因為賦值操作中的兩個步驟可能會出現亂序執行問題。這兩個步驟是:對象內存空間的初始化和將內存地址設置給變量。因為編譯器或者CPU優化,它們的執行順序可能不確定,先執行第2步的話,鎖外邊的線程很有可能訪問到沒有初始化完畢的變量,從而引發某些異常。針對這個問題,Java以及其它一些語言中可以使用volatile來修飾變量,實際執行時會通過插入內存柵欄阻止指令重排,強制按照編碼的指令順序執行。
那么Go語言中的雙檢鎖是安全的嗎?
答案是也不安全。
先來看看指令重排問題:
在Go語言規范中,賦值操作分為兩個階段:第一階段對賦值操作左右兩側的表達式進行求值,第二階段賦值按照從左至右的順序執行。
說的有點抽象,但沒有提到賦值存在指令重排的問題,隱約感覺不會有這個問題。為了驗證,讓我們看一下上邊那段代碼中賦值操作的偽匯編代碼:
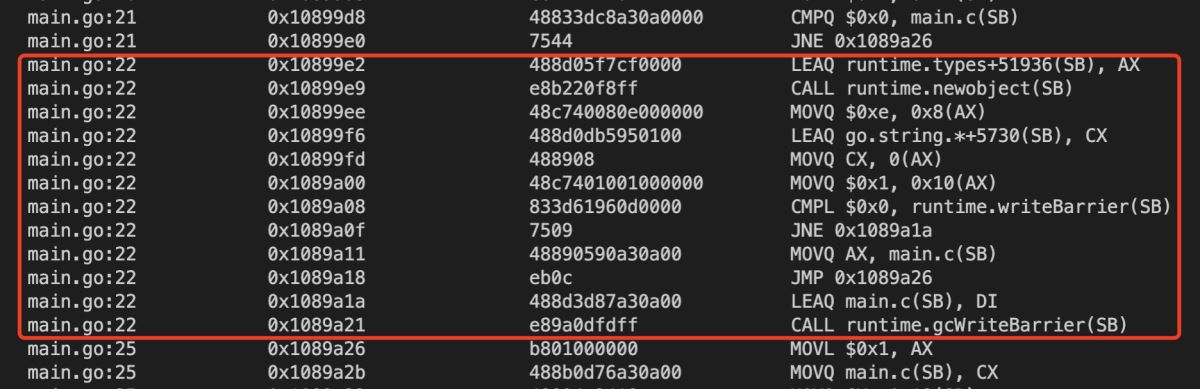
紅框圈出來的部分對應的代碼是: c = &Conn{"127.0.0.1:8080", 1}
其中有一行:CMPL $0x0, runtime.writeBarrier(SB) ,這個指令就是插入一個內存柵欄。前邊是要賦值數據的初始化,后邊是賦值操作。如此看,賦值操作不存在指令重排的問題。
既然賦值操作沒有指令重排的問題,那這個雙檢鎖怎么還是不安全的呢?
在Golang中,對于大于單個機器字的值,讀寫它的時候是以一種不確定的順序多次執行單機器字的操作來完成的。機器字大小就是我們通常說的32位、64位,即CPU完成一次無定點整數運算可以處理的二進制位數,也可以認為是CPU數據通道的大小。比如在32位的機器上讀寫一個int64類型的值就需要兩次操作。
因為Golang中對變量的讀和寫都沒有原子性的保證,所以很可能出現這種情況:鎖里邊變量賦值只處理了一半,鎖外邊的另一個goroutine就讀到了未完全賦值的變量。所以這個雙檢鎖的實現是不安全的。
Golang中將這種問題稱為data race,說的是對某個數據產生了并發讀寫,讀到的數據不可預測,可能產生問題,甚至導致程序崩潰。可以在構建或者運行時檢查是否會發生這種情況:
$ go test -race mypkg // to test the package $ go run -race mysrc.go // to run the source file $ go build -race mycmd // to build the command $ go install -race mypkg // to install the package
另外上邊說單條賦值操作沒有重排序的問題,但是重排序問題在Golang中還是存在的,稍不注意就可能寫出BUG來。比如下邊這段代碼:
a=1 b=1 c=a+b
在執行這段程序的goroutine中并不會出現問題,但是另一個goroutine讀取到b1時并不代表此時a1,因為a=1和b=1的執行順序可能會被改變。針對重排序問題,Golang并沒有暴露類似volatile的關鍵字,因為理解和正確使用這類能力進行并發編程的門檻比較高,所以Golang只是在一些自己認為比較適合的地方插入了內存柵欄,盡量保持語言的簡單。對于goroutine之間的數據同步,Go提供了更好的方式,那就是Channel,不過這不是本文的重點,這里就不介紹了。
還是回到最開始的問題,如何在Golang中創建一個單例?
很多人應該會被推薦使用 sync.Once ,這里看下如何使用:
type Conn struct {
Addr string
State int
}
var c *Conn
var once sync.Once
func setInstance() {
fmt.Println("setup")
c = &Conn{"127.0.0.1:8080", 1}
}
func doPrint() {
once.Do(setInstance)
fmt.Println(c)
}
func loopPrint() {
for i := 0; i < 10; i++ {
go doprint()
}
}這里重用上文的結構體Conn,設置Conn單例的方法是setInstance,這個方法在doPrint中被once.Do調用,這里的once就是sync.Once的一個實例,然后我們在loopPrint方法中創建10個goroutine來調用doPrint方法。
按照sync.Once的語義,setInstance應該近執行一次。可以實際執行下看看,我這里直接貼出結果:
setup
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
無論執行多少遍,都是這個結果。那么sync.Once是怎么做到的呢?源碼很短很清楚:
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Once是一個結構體,其中第一個字段標識是否執行過,第二個字段是一個互斥量。Once僅公開了一個Do方法,用于執行目標函數f。
這里重點看下目標函數f是怎么被執行的?
Do方法中第一行是判斷字段done是否為0,為0則代表沒執行過,為1則代表執行過。這里用了原子讀,寫的時候也要原子寫,這樣可以保證讀寫不會同時發生,能夠讀到當前最新的值。
如果done為0,則調用doSLow方法,從名字我們就可以體會到這個方法比較慢。
doSlow中首先會加鎖,使用的是Once結構體的第二個字段。
然后再判斷done是否為0,注意這里沒有使用原子讀,為什么呢?因為鎖中的方法是串行執行的,不會發生并發讀寫。
如果done為0,則調用目標函數f,執行相關的業務邏輯。
在執行目標函數f前,這里還聲明了一個defer:defer atomic.StoreUint32(&o.done, 1) ,使用原子寫改變done的值為1,代表目標函數已經執行過。它會在目標函數f執行完畢,doSlow方法返回之前執行。這個設計很精妙,精確控制了改寫done值的時機。
可以看出,這里用的也是雙檢鎖的模式,只不過做了兩個增強:一是使用原子讀寫,避免了并發讀寫的內存數據不一致問題;二是在defer中更改完成標識,保證了代碼執行順序,不會出現完成標識更改邏輯被編譯器或者CPU優化提前執行。
需要注意,如果目標函數f中發生了panic,目標函數也僅執行一次,不會執行多次直到成功。
有了對sync.Once的理解,我們可以改造之前寫的雙檢鎖邏輯,讓它也能安全起來。
type Conn struct {
Addr string
State int
}
var c *Conn
var mu sync.Mutex
var done uint32
func getInstance() *Conn {
if atomic.LoadUint32(&done) == 0 {
mu.Lock()
defer mu.Unlock()
if done == 0 {
defer atomic.StoreUint32(&done, 1)
c = &Conn{"127.0.0.1:8080", 1}
}
}
return c
}改變的地方就是sync.Once做的兩個增強;原子讀寫和defer中更改完成標識。
當然如果要做的工作僅限于此,還不如直接使用sync.Once。
有時候我們需要的單例不是一成不變的,比如在ylog中需要每小時創建一個日志文件的實例,再比如需要為每一個用戶創建不同的單例;再比如創建實例的過程中發生了錯誤,可能我們還會期望再執行實例的創建過程,直到成功。這兩個需求是sync.Once無法做到的。
這里在創建Conn的時候模擬一個panic。
i:=0
func newConn() *Conn {
fmt.Println("newConn")
div := i
i++
k := 10 / div
return &Conn{"127.0.0.1:8080", k}
}第1次執行newConn時會發生一個除零錯誤,并引發 panic。再執行時則可以正常創建。
panic可以通過recover進行處理,因此可以在捕捉到panic時不更改完成標識,之前的getInstance方法可以修改為:
func getInstance() *Conn {
if atomic.LoadUint32(&done) == 0 {
mu.Lock()
defer mu.Unlock()
if done == 0 {
defer func() {
if r := recover(); r == nil {
defer atomic.StoreUint32(&done, 1)
}
}()
c = newConn()
}
}
return c
}可以看到這里只是改了下defer函數,捕捉不到panic時才去更改完成標識。注意此時c并沒有創建成功,會返回零值,或許你還需要增加其它的錯誤處理。
如果業務代碼不是拋出panic,而是返回error,這時候怎么處理?
可以將error轉為panic,比如newConn是這樣實現的:
func newConn() (*Conn, error) {
fmt.Println("newConn")
div := i
i++
if div == 0 {
return nil, errors.New("the divisor is zero")
}
k := 1 / div
return &Conn{"127.0.0.1:8080", k}, nil
}我們可以再把它包裝一層:
func mustNewConn() *Conn {
conn, err := newConn()
if err != nil {
panic(err)
}
return conn
}如果不使用panic,還可以再引入一個變量,有error時對它賦值,在defer函數中增加對這個變量的判斷,如果有錯誤值,則不更新完成標識位。代碼也比較容易實現,不過還要增加變量,感覺復雜了,這里就不測試這種方法了。
前文提到過有時單例不是一成不變的,我這里將這種單例稱為有范圍的單例。
這里還是復用前文的Conn結構體,不過需求修改為要為每個用戶創建一個Conn實例。
看一下User的定義:
type User struct {
done uint32
Id int64
mu sync.Mutex
c *Conn
}其中包括一個用戶Id,其它三個字段還是用于獲取當前用戶的Conn單例的。
再看看getInstance函數怎么改:
func getInstance(user *User) *Conn {
if atomic.LoadUint32(&user.done) == 0 {
user.mu.Lock()
defer user.mu.Unlock()
if user.done == 0 {
defer func() {
if r := recover(); r == nil {
defer atomic.StoreUint32(&user.done, 1)
}
}()
user.c = newConn()
}
}
return user.c
}這里增加了一個參數 user,方法內的邏輯基本沒變,只不過操作的東西都變成user的字段。這樣就可以為每個用戶創建一個Conn單例。
這個方法有點泛型的意思了,當然不是泛型。
有范圍單例的另一個示例:在ylog中需要每小時創建一個日志文件用于記錄當前小時的日志,在每個小時只需創建并打開這個文件一次。
先看看Logger的定義(這里省略和創建單例無關的內容。):
type FileLogger struct {
lastHour int64
file *os.File
mu sync.Mutex
...
}lastHour是記錄的小時數,如果當前小時數不等于記錄的小時數,則說明應該創建新的文件,這個變量類似于sync.Once中的done字段。
file是打開的文件實例。
mu是創建文件實例時需要加的鎖。
下邊看一下打開文件的方法:
func (l *FileLogger) ensureFile() (err error) {
curTime := time.Now()
curHour := getTimeHour(curTime)
if atomic.LoadInt64(&l.lastHour) != curHour {
return l.ensureFileSlow(curTime, curHour)
}
return
}
func (l *FileLogger) ensureFileSlow(curTime time.Time, curHour int64) (err error) {
l.mu.Lock()
defer l.mu.Unlock()
if l.lastHour != curHour {
defer func() {
if r := recover(); r == nil {
atomic.StoreInt64(&l.lastHour, curHour)
}
}()
l.createFile(curTime, curHour)
}
return
}這里模仿sync.Once中的處理方法,有兩點主要的不同:數值比較不再是0和1,而是每個小時都會變化的數字;增加了對panic的處理。如果打開文件失敗,則還會再次嘗試打開文件。
要查看完整的代碼請訪問Github:https://github.com/bosima/ylog/tree/1.0
從原理上分析,雙檢鎖的性能要好過互斥鎖,因為互斥鎖每次都要加鎖;不使用原子操作的雙檢鎖要比使用原子操作的雙檢鎖好一些,畢竟原子操作也是有些成本的。那么實際差距是多少呢?
這里做一個Benchmark Test,還是處理上文的Conn結構體,為了方便測試,定義一個上下文:
type Context struct {
done uint32
c *Conn
mu sync.Mutex
}編寫三個用于測試的方法:
func ensure_unsafe_dcl(context *Context) {
if context.done == 0 {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer func() { context.done = 1 }()
context.c = newConn()
}
}
}
func ensure_dcl(context *Context) {
if atomic.LoadUint32(&context.done) == 0 {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer atomic.StoreUint32(&context.done, 1)
context.c = newConn()
}
}
}
func ensure_mutex(context *Context) {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer func() { context.done = 1 }()
context.c = newConn()
}
}這三個方法分別對應不安全的雙檢鎖、使用原子操作的安全雙檢鎖和每次都加互斥鎖。它們的作用都是確保Conn結構體的實例存在,如果不存在則創建。
使用的測試方法都是下面這種寫法,按照計算機邏輯處理器的數量并行運行測試方法:
func BenchmarkInfo_DCL(b *testing.B) {
context := &Context{}
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
ensure_dcl(context)
processConn(context.c)
}
})
}先看一下Benchmark Test的結果:

可以看到使用雙檢鎖相比每次加鎖的提升是兩個數量級,這是正常的。
而不安全的雙檢鎖和使用原子操作的安全雙檢鎖時間消耗相差無幾,為什么呢?
主要原因是這里寫只有1次,剩下的全是讀。即使使用了原子操作,絕大部分情況下CPU讀數據的時候也不用在多個核心之間同步(鎖總線、鎖緩存等),只需要讀緩存就可以了。這也從一個方面證明了雙檢鎖模式的意義。
另外上文提到過Go讀寫超過一個機器字的變量時是非原子的,那如果讀寫只有1個機器字呢?在64位機器上讀寫int64本身就是原子操作,也就是說讀寫應該都只需1次操作,不管用不用atomic方法。這可以在編譯器文檔或者CPU手冊中驗證。
不過這兩個分析不是說我們使用原子操作沒有意義,不安全雙檢鎖的執行結果是沒有Go語言規范保證的,上邊的結果只是在特定編譯器、特定平臺下的基準測試結果,不同的編譯器、CPU,甚至不同版本的Go都不知道會出什么幺蛾子,運行的效果也就無法保證。我們不得不考慮程序的可移植性。
以上就是關于“Go如何實現安全的雙檢鎖”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





