溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Tree組件搜索過濾功能如何實現”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Tree組件搜索過濾功能如何實現”文章能幫助大家解決問題。
樹節點的搜索功能主要是為了方便用戶能夠快速查找到自己需要的節點。過濾功能不僅要滿足搜索的特性,同時還需要隱藏掉與匹配節點同層級的其它未能匹配的節點。
搜索功能主要包括以下功能:
與搜索過濾字段匹配的節點需要進行標識,和普通節點進行區分
子節點匹配時,其所有父節點需要展開,方便用戶查看層級關系
對于大數據量,采用虛擬滾動時,搜索過濾完成后滾動條需滾動至第一個匹配節點的位置
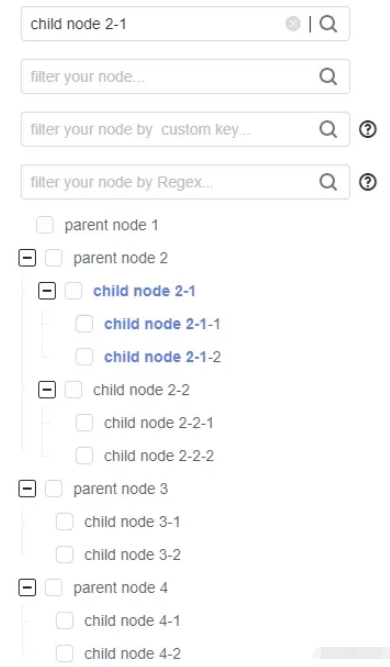
搜索會將匹配到的節點高亮:
過濾除了將匹配到的節點高亮之外,還會將不匹配的節點篩除掉:
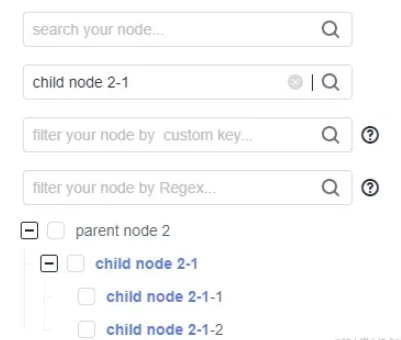
通過將節點與搜索字段相匹配的 label 部分文字進行高亮加粗的方式進行標記。易于用戶一眼就能夠找到搜索到的節點。
通過添加searchTree方法,用戶通過ref的方式進行調用。并通過option參數配置區分搜索、過濾。
對于節點的獲取及處理是搜索過濾功能的核心。尤其在大數據量的情況下,帶來的性能消耗如何優化,將在實現原理中詳情闡述。
tree組件的文件結構:
tree ├── index.ts ├── src | ├── components | | ├── tree-node.tsx | | ├── ... | ├── composables | | ├── use-check.ts | | ├── use-core.ts | | ├── use-disable.ts | | ├── use-merge-nodes.ts | | ├── use-operate.ts | | ├── use-select.ts | | ├── use-toggle.ts | | ├── ... | ├── tree.scss | ├── tree.tsx └── __tests__ └── tree.spec.ts
可以看出,vue3.0中 composition-api 帶來的便利。邏輯層之間的分離,方便代碼組織及后續問題的定位。能夠讓開發者只專心于自己的特性,非常有利于后期維護。
添加文件use-search-filter.ts, 文件中定義searchTree方法。
import { Ref, ref } from 'vue';
import { trim } from 'lodash';
import { IInnerTreeNode, IUseCore, IUseSearchFilter, SearchFilterOption } from './use-tree-types';
export default function () {
return function useSearchFilter(data: Ref<IInnerTreeNode[]>, core: IUseCore): IUseSearchFilter {
const searchTree = (target: string, option: SearchFilterOption): void => {
// 搜索主邏輯
};
return {
virtualListRef,
searchTree,
};
}
}SearchFilterOption的接口定義,matchKey 與 pattern的配置增添了搜索的匹配方式多樣性。
export interface SearchFilterOption {
isFilter: boolean; // 是否是過濾節點
matchKey?: string; // node節點中匹配搜索過濾的字段名
pattern?: RegExp; // 搜索過濾時匹配的正則表達式
}在tree.tsx主文件中添加文件use-search-fliter.ts的引用, 并將searchTree方法暴露給第三方調用者。
import useSearchFilter from './composables/use-search-filter';
setup(props: TreeProps, context: SetupContext) {
const userPlugins = [useSelect(), useOperate(), useMergeNodes(), useSearchFilter()];
const treeFactory = useTree(data.value, userPlugins, context);
expose({
treeFactory,
});
}nodes數據結構直接決定如何訪問及處理匹配節點的父節點及兄弟節點
在use-core.ts文件中可以看出, 整個數據結構采用的是扁平結構,并不是傳統的樹結構,所有的節點包含在一個一維的數組中。
const treeData = ref<IInnerTreeNode[]>(generateInnerTree(tree));
// 內部數據結構使用扁平結構
export interface IInnerTreeNode extends ITreeNode {
level: number;
idType?: 'random';
parentId?: string;
isLeaf?: boolean;
parentChildNodeCount?: number;
currentIndex?: number;
loading?: boolean; // 節點是否顯示加載中
childNodeCount?: number; // 該節點的子節點的數量
// 搜索過濾
isMatched?: boolean; // 搜索過濾時是否匹配該節點
childrenMatched?: boolean; // 搜索過濾時是否有子節點存在匹配
isHide?: boolean; // 過濾后是否不顯示該節點
matchedText?: string; // 節點匹配的文字(需要高亮顯示)
}節點中添加以下屬性,用于標識匹配關系
isMatched?: boolean; // 搜索過濾時是否匹配該節點 childrenMatched?: boolean; // 搜索過濾時是否有子節點存在匹配 matchedText?: string; // 節點匹配的文字(需要高亮顯示)
通過 dealMatchedData 方法來處理所有節點關于搜索屬性的設置。
它主要做了以下事情:
將用戶傳入的搜索字段進行大小寫轉換
循環所有節點,先處理自身節點是否與搜索字段匹配,匹配就設置 selfMatched = true。首先判斷用戶是否通過自定義字段進行搜索 ( matchKey 參數),如果有,設置匹配屬性為node中自定義屬性,否則為默認 label 屬性;然后判斷是否進行正則匹配 ( pattern 參數),如果有,就進行正則匹配,否則為默認的忽略大小寫的模糊匹配。
如果自身節點匹配時, 設置節點 matchedText 屬性值,用于高亮標識。
判斷自身節點有無 parentId,無此屬性值時,為根節點,無須處理父節點。有此屬性時,需要進行內層循環處理父節點的搜索屬性。利用set保存節點的 parentId , 依次向前查找,找到parent節點,判讀是否該parent節點被處理過,如果沒有,設置父節點的 childrenMatched 和 expanded 屬性為true,再將parent節點的 parentId 屬性加入set中,while循環重復這個操作,直到遇到第一個已經處理過的父節點或者直到根節點停止循環。
整個雙層循環將所有節點處理完畢。
dealMatchedData核心代碼如下:
const dealMatchedData = (target: string, matchKey: string | undefined, pattern: RegExp | undefined) => {
const trimmedTarget = trim(target).toLocaleLowerCase();
for (let i = 0; i < data.value.length; i++) {
const key = matchKey ? data.value[i][matchKey] : data.value[i].label;
const selfMatched = pattern ? pattern.test(key) : key.toLocaleLowerCase().includes(trimmedTarget);
data.value[i].isMatched = selfMatched;
// 需要向前找父節點,處理父節點的childrenMatched、expand參數(子節點匹配到時,父節點需要展開)
if (selfMatched) {
data.value[i].matchedText = matchKey ? data.value[i].label : trimmedTarget;
if (!data.value[i].parentId) {
// 沒有parentId表示時根節點,不需要再向前遍歷
continue;
}
let L = i - 1;
const set = new Set();
set.add(data.value[i].parentId);
// 沒有parentId時,表示此節點的縱向parent已訪問完畢
// 沒有父節點被處理過,表示時第一次向上處理當前縱向父節點
while (L >= 0 && data.value[L].parentId && !hasDealParentNode(L, i, set)) {
if (set.has(data.value[L].id)) {
data.value[L].childrenMatched = true;
data.value[L].expanded = true;
set.add(data.value[L].parentId);
}
L--;
}
// 循環結束時需要額外處理根節點一層
if (L >= 0 && !data.value[L].parentId && set.has(data.value[L].id)) {
data.value[L].childrenMatched = true;
data.value[L].expanded = true;
}
}
}
};
const hasDealParentNode = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
// 當訪問到同一層級前已經有匹配時前一個已經處理過父節點了,不需要繼續訪問
// 當訪問到第一父節點的childrenMatched為true的時,不再需要向上尋找,防止重復訪問
return (
(data.value[pre].parentId === data.value[cur].parentId && data.value[pre].isMatched) ||
(parentIdSet.has(data.value[pre].id) && data.value[pre].childrenMatched)
);
};節點中添加以下屬性,用于標識節點是否隱藏。
isHide?: boolean; // 過濾后是否不顯示該節點
同3.3中核心處理邏輯大同小異,通過雙層循環, 節點的 isMatched 和 childrenMatched 以及父節點的 isMatched 設置自身節點是否顯示。
核心代碼如下:
const dealNodeHideProperty = () => {
data.value.forEach((item, index) => {
if (item.isMatched || item.childrenMatched) {
item.isHide = false;
} else {
// 需要判斷是否有父節點有匹配
if (!item.parentId) {
item.isHide = true;
return;
}
let L = index - 1;
const set = new Set();
set.add(data.value[index].parentId);
while (L >= 0 && data.value[L].parentId && !hasParentNodeMatched(L, index, set)) {
if (set.has(data.value[L].id)) {
set.add(data.value[L].parentId);
}
L--;
}
if (!data.value[L].parentId && !data.value[L].isMatched) {
// 沒有parentId, 說明已經訪問到當前節點所在的根節點
item.isHide = true;
} else {
item.isHide = false;
}
}
});
};
const hasParentNodeMatched = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
return parentIdSet.has(data.value[pre].id) && data.value[pre].isMatched;
};如果該節點被匹配,將節點的label處理成[preMatchedText, matchedText, postMatchedText]格式的數組。 matchedText添加 span標簽包裹,通過CSS樣式顯示高亮效果。
const matchedContents = computed(() => {
const matchItem = data.value?.matchedText || '';
const label = data.value?.label || '';
const reg = (str: string) => str.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
const regExp = new RegExp('(' + reg(matchItem) + ')', 'gi');
return label.split(regExp);
});<span class={nodeTitleClass.value}>
{ !data.value?.matchedText && data.value?.label }
{
data.value?.matchedText
&& matchedContents.value.map((item: string, index: number) => (
index % 2 === 0
? item
: <span class={highlightCls}>{item}</span>
))
}
</span>tree組件采用虛擬列表時,需將滾動條滾動至第一個匹配的節點,方便用戶查看
先得到目前整個樹顯示出來的節點,找到第一個匹配的節點下標。調用虛擬列表組件的 scrollTo 方法滾動至該匹配節點。
const getFirstMatchIndex = (): number => {
let index = 0;
const showTreeData = getExpendedTree().value;
while (index <= showTreeData.length - 1 && !showTreeData[index].isMatched) {
index++;
}
return index >= showTreeData.length ? 0 : index;
};
const scrollIndex = getFirstMatchIndex();
virtualListRef.value.scrollTo(scrollIndex);通過 scrollTo 方法定位至第一個匹配項效果圖:
原始樹結構顯示圖:
過濾功能:

到這里 Tree 組件的搜索過濾功能就開發完了,我們來使用下吧。
<script setup lang="ts">
import { ref } from 'vue';
const treeRef = ref();
const data = ref([
{
label: 'parent node 1',
},
{
label: 'parent node 2',
children: [
{
label: 'child node 2-1',
children: [
{
label: 'child node 2-1-1',
},
{
label: 'child node 2-1-2',
},
],
},
{
label: 'child node 2-2',
children: [
{
label: 'child node 2-2-1',
},
{
label: 'child node 2-2-2',
},
],
},
],
},
]);
const onSearch = (keyword) => {
// 只需要調用 Tree 組件實例的 searchTree 方法即可實現搜索過濾
treeRef.value.treeFactory.searchTree(keyword);
};
</script>
<template>
<d-search @search="onSearch"></d-search>
<d-tree ref="treeRef" :data="data"></d-tree>
</template>是不是非常簡單?
searchTree 方法一共有兩個參數:
keyword 搜索關鍵字
options 配置選項
isFilter 是否需要過濾
matchKey node節點中匹配搜索過濾的字段名
pattern 搜索過濾時匹配的正則表達式
整棵樹數據結構就是一個一維數組,向上需要將匹配節點所有的父節點全部展開, 向下需要知道有沒有子節點存在匹配。傳統tree組件的數據結構是樹形結構,通過遞歸的方式完成節點的訪問及處理。對于扁平的數據結構應該如何處理?
方案一:扁平數據結構 --> 樹形結構 --> 遞歸處理 --> 扁平數據結構 (NO)
方案二: node添加parent屬性,保存該節點父級節點內容 --> 遍歷節點處理自身節點及parent節點 (No)
方案三: 同過雙層循環,第一層循環處理當前節點,第二層循環處理父節點 (Yes)
方案一:通過數據結構的轉換處理,不僅丟掉了扁平數據結構的優勢,還增加了數據格式轉換的成本,并帶來了更多的性能消耗。
方案二:parent屬性添加其實就是一種樹形結構的模仿,增加內存消耗,保存很多無用重復數據。循環訪問節點時也存在節點的重復訪問。節點越靠后,重復訪問越嚴重,無用的性能消耗。
方案三: 利用扁平數據結構的優勢,節點是有順序的。即:樹節點的顯示順序就是節點在數組中的順序,父節點一定是在子節點之前。父節點訪問處理只需要遍歷該節點之前的節點,通過 childrenMatched屬性標識該父節點有子節點存在匹配。 不用添加parent字段存取所有的父節點信息,不用通過數據轉換,再遞歸尋找處理節點。
外層循環,如果該節點沒有匹配搜索字段,將不進行內層循環,直接跳過。 詳見3.3中的代碼
通過對內層循環終止條件的優化,防止重復訪問同一個父節點
let L = index - 1;
const set = new Set();
set.add(data.value[index].parentId);
while (L >= 0 && data.value[L].parentId && !hasParentNodeMatched(L, index, set)) {
if (set.has(data.value[L].id)) {
set.add(data.value[L].parentId);
}
L--;
}const hasDealParentNode = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
// 當訪問到同一層級前已經有匹配時前一個已經處理過父節點了,不需要繼續訪問
// 當訪問到第一父節點的childrenMatched為true的時,不再需要向上尋找,防止重復訪問
return (
(data.value[pre].parentId === data.value[cur].parentId && data.value[pre].isMatched) ||
(parentIdSet.has(data.value[pre].id) && data.value[pre].childrenMatched)
);
};同樣通過雙層循環、以及處理匹配數據時增加的isMatched 、 childrenMatched屬性來共同決定節點的isHide屬性,詳見3.4中的代碼、
通過對內層循環終止條件的優化,與設置 childrenMatched時的判斷有所區別。
const hasParentNodeMatched = (pre: number, cur: number, parentIdSet: Set<unknown>) => {
return parentIdSet.has(data.value[pre].id) && data.value[pre].isMatched;
};關于“Tree組件搜索過濾功能如何實現”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





