溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python數據預處理常用的技巧有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
這是一個包含臟數據的示例數據框
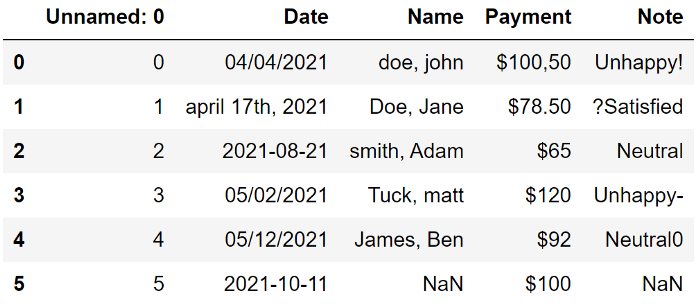
讓我們看看可以做些什么來使這個數據集變得干凈。
第一列是多余的,應該刪除;
Date 沒有標準;
Name 寫成姓氏、名字,并有大寫和小寫字母;
Payment 代表一個數量,但它們顯示為字符串,需要處理;
在 Note 中,有一些非字母數字應該被刪除;
刪除列是使用 drop 函數的簡單操作。除了寫列名外,我們還需要指定軸參數的值,因為 drop 函數用于刪除行和列。 最后,我們可以使用 inplace 參數來保存更改。
import pandas as pd
df.drop("Unnamed: 0", axis=1, inplace=True)我們有多種選擇將日期值轉換為適當的格式。一種更簡單的方法是使用 astype 函數來更改列的數據類型。
它能夠處理范圍廣泛的值并將它們轉換為整潔、標準的日期格式。
df["Date"] = df["Date"].astype("datetime64[ns]")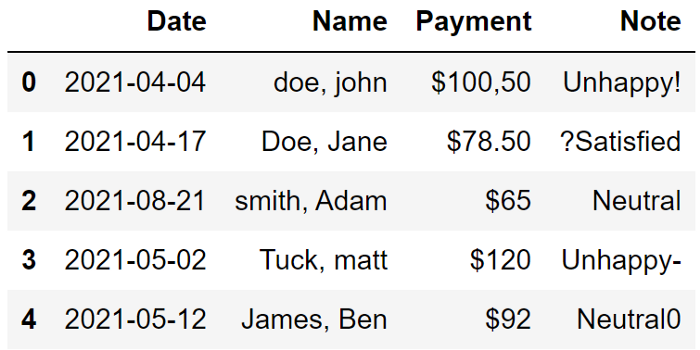
關于名稱列,我們首先需要解決如下問題:
首先我們應該用所有大寫或小寫字母來表示它們。另一種選擇是將它們大寫(即只有首字母是大寫的);
切換姓氏和名字的順序;
df["Name"].str.split(",", expand=True)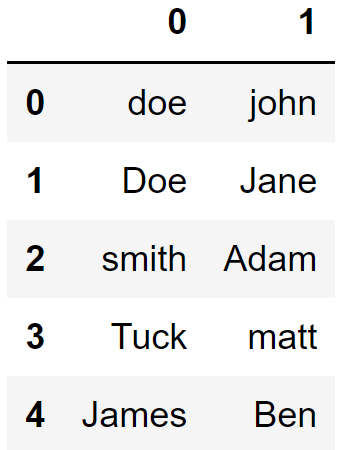
然后,我將取第二列與第一列結合起來,中間有一個空格。最后一步是使用 lower 函數將字母轉換為小寫。
df["Name"] = (df["Name"].str.split(",", expand=True)[1] + " " + df["Name"].str.split(",", expand=True)[0]).str.lower()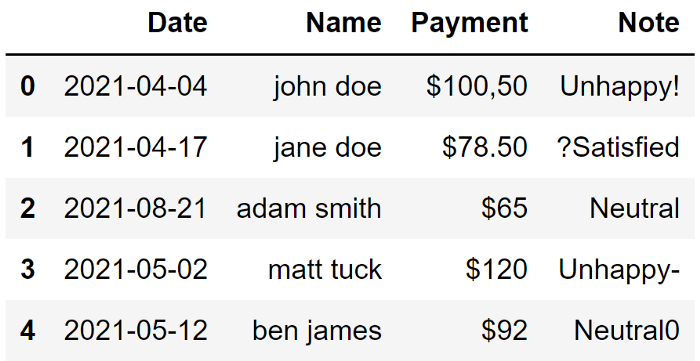
支付Payment的數據類型是不能用于數值分析的。在將其轉換為數字數據類型(即整數或浮點數)之前,我們需要刪除美元符號并將第一行中的逗號替換為點。
我們可以使用 Pandas 在一行代碼中完成所有這些操作
df["Payment"] = df["Payment"].str[1:].str.replace(",", ".").astype("float")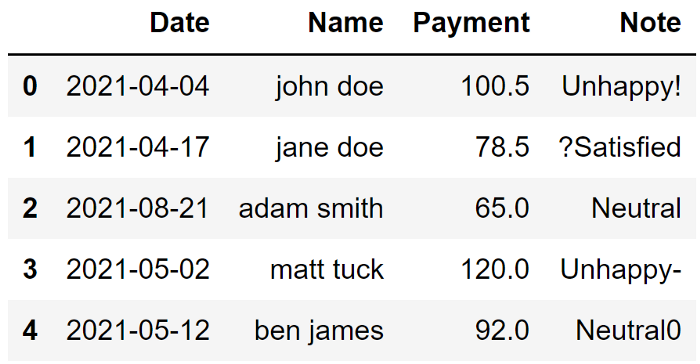
Note 列中的一些字符也需要刪除。在處理大型數據集時,可能很難手動替換它們。
我們可以做的是刪除非字母數字字符(例如?、!、-、. 等)。在這種情況下也可以使用 replace 函數,因為它接受正則表達式。
如果我們只想要字母字符,下面是我們如何使用替換函數:
df["Note"].str.replace('[^a-zA-Z]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral
Name: Note, dtype: object如果我們想要字母和數字(即字母數字),我們需要在我們的正則表達式中添加數字:
df["Note"].str.replace('[^a-zA-Z0-9]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral0
Name: Note, dtype: object請注意,這次沒有刪除最后一行中的 0,我只需選擇第一個選項。如果我還想在刪除非字母數字字符后將字母轉換為小寫
df["Note"] = df["Note"].str.replace('[^a-zA-Z]', '').str.lower()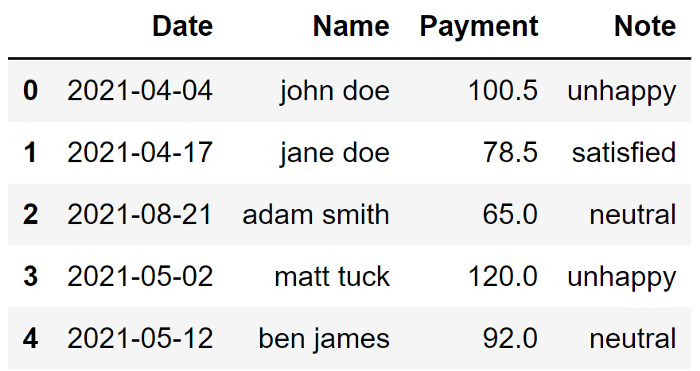
與初始形式相比,數據集看起來要好得多。當然,它是一個簡單的數據集,但這些清理操作在處理大型數據集時肯定會對你有所幫助。
“Python數據預處理常用的技巧有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





