溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python中常用探索性數據分析方法有哪些,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
常用探索性數據分析方法很多,比如常用的 Pandas DataFrame 方法有 .head()、.tail()、.info()、.describe()、.plot() 和 .value_counts()。
import pandas as pd
import numpy as np
df = pd.DataFrame( {
"Student" : ["Mike", "Jack", "Diana", "Charles", "Philipp", "Charles", "Kale", "Jack"] ,
"City" : ["London", "London", "Berlin", "London", "London", "Berlin", "London", "Berlin"] ,
"Age" : [20, 40, 18, 24, 37, 40, 44, 20 ],
"Maths_Score" : [84, 80, 50, 36, 44, 24, 41, 35],
"Science_Score" : [66, 83, 51, 35, 43, 58, 71, 65]} )
df在許多情況下,我們希望將數據集拆分為多個組并對這些組進行處理。 Pandas 方法 groupby() 用于將 DataFrame 中的數據分組。
與其一起使用 groupby() 和聚合方法,不如創建一個 groupby() 對象。 理想的情況是,我們可以在需要時直接使用此對象。
讓我們根據列“City”將給定的 DataFrame 分組
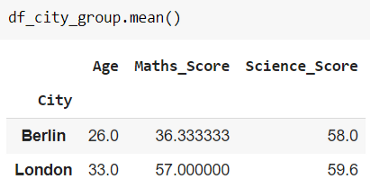
df_city_group = df.groupby("City")我們創建一個對象 df_city_group,該對象可以與不同的聚合相結合,例如 min()、max()、mean()、describe() 和 count()。 一個例子如下所示。
要獲取“City”是Berlin的 DataFrame 子集,只需使用方法 .get_group()
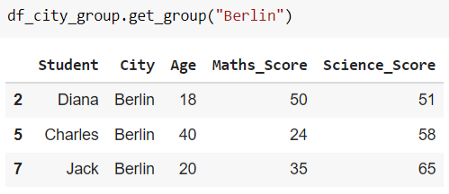
這不需要為每個組創建每個子 DataFrame 的副本,比較節省內存。
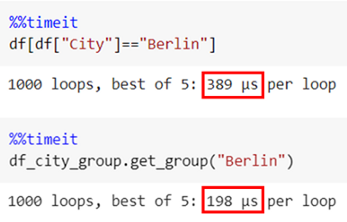
另外,使用 .groupby() 進行切片比常規方法快 2 倍!!
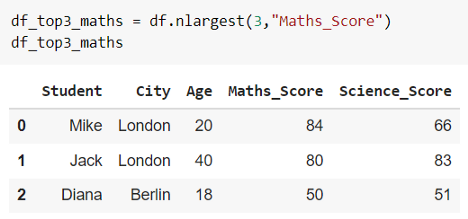
通常,我們根據特定列的值了解 DataFrame 的 Top 3 或 Top 5 數據。例如,從考試中獲得前 3 名得分者或從數據集中獲得前 5 名觀看次數最多的電影。使用 Pandas .nlargest() 是最簡單的方式。
df.nlargest(N, column_name, keep = ‘first' )
使用 .nlargest() 方法,可以檢索包含指定列的 Top ‘N' 值的 DataFrame 行。
在上面的示例中,讓我們獲取前 3 個“Maths_Score”的 DataFrame 的行。
如果兩個值之間存在聯系,則可以修改附加參數和可選參數。 它需要值“first”、“last”和“all”來檢索領帶中的第一個、最后一個和所有值。這種方法的優點是,你不需要專門對 DataFrame 進行排序。
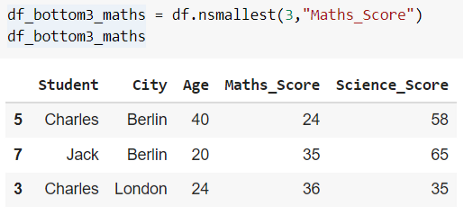
與Top 3 或5 類似,有時我們也需要DataFrame 中的Last 5 條記錄。例如,獲得評分最低的 5 部電影或考試中得分最低的 5 名學生。使用 Pandas .nsmallest() 是最簡單的方式
df.nsmallestst(N, column_name, keep = ‘first' )
使用 .nsmallest() 方法,可以檢索包含指定列的底部“N”個值的 DataFrame 行。
在同一個示例中,讓我們獲取 DataFrame“df”中“Maths_Score”最低的 3 行。
比較運算符 <、>、<=、>=、==、!= 及其包裝器 .lt()、.gt()、.le()、.ge()、.eq() 和 .ne() 分別在以下情況下非常方便將 DataFrame 與基值進行比較,這種比較會產生一系列布爾值,這些值可用作以后的指標。
基于比較對 DataFrame 進行切片
可以基于與值的比較從 DataFrame 中提取子集。
根據兩列的比較在現有 DataFrame 中創建一個新列。
所有這些場景都在下面的示例中進行了解釋
# 1. Comparing the DataFrame to a base value # Selecting the columns with numerical values only df.iloc[:,2:5].gt(50) df.iloc[:,2:5].lt(50) # 2. Slicing the DataFrame based on comparison # df1 is subset of df when values in "Maths_Score" column are not equal or equal to '35' df1 = df[df["Maths_Score"].ne(35)] df2 = df[df["Maths_Score"].eq(35)] # 3. Creating new column of True-False values by comparing two columns df["Maths_Student"] = df["Maths_Score"].ge(df["Science_Score"]) df["Maths_Student_1"] = df["Science_Score"].le(df["Maths_Score"])
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Python中常用探索性數據分析方法有哪些”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





