溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用pandas_profiling完成探索性數據分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
筆者最近發現一款將pandas數據框快速轉化為描述性數據分析報告的package——pandas_profiling。一行代碼即可生成內容豐富的EDA內容,兩行代碼即可將報告以.html格式保存。筆者當初也是從數據分析做起的,所以深知這個工具對于數據分析的朋友而言極為方便,在此特地分享給大家。
我們以uci機器學習庫中的人口調查數據集adult.data為例進行說明。
數據集地址:
https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data
常規情況下我們拿到數據做EDA的時候這幾種函數是必用的:
看一下數據長啥樣:
import numpy as npimport pandas as pdadult = pd.read_csv('../adult.data')adult.head()
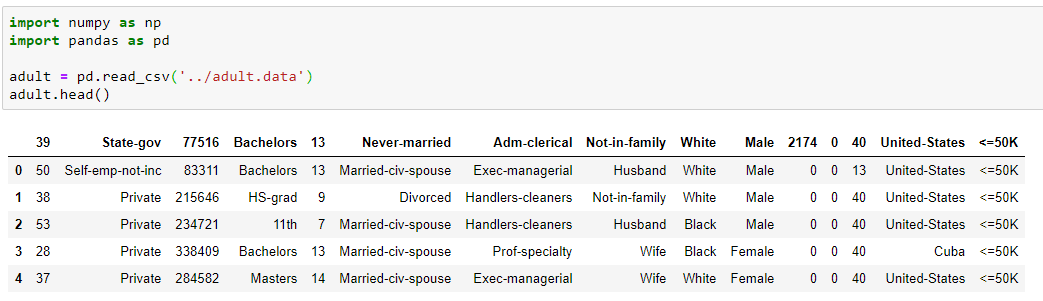
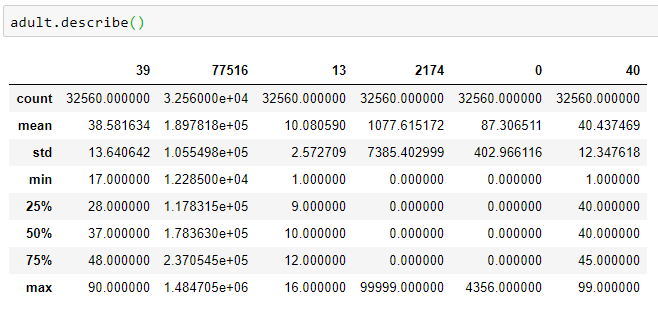
對數據進行統計描述:
adult.describe()
查看變量信息和缺失情況:
adult.info()
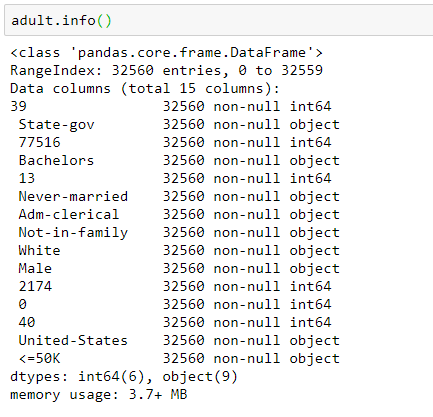
這是最簡單最快速了解一個數據集的方法。當然,更深層次的EDA一定是要借助統計圖形來展示的。基于scipy、matplotlib和seaborn等工具的展示這里權且略過。
現在我們有了pandas_profiling。上述過程以及各種統計相關性計算、統計繪圖全部由pandas_profiling打包搞定了。pandas_profiling安裝,包括pip、conda和源碼三種安裝方式。
pip:
pip install pandas-profilingpip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
conda:
conda install -c conda-forge pandas-profiling
source:
先下載源碼文件,然后解壓到setup.py所在的文件目錄下:
python setup.py install
再來看pandas_profiling基本用法,用pandas將數據讀入之后,對數據框直接調用profile_report方法生成EDA分析報告,然后使用to_file方法另存為.html文件。
profile = df.profile_report(title="Census Dataset")profile.to_file(output_file=Path("./census_report.html"))
看看報告效果如何。pandas-profiling EDA報告包括數據整體概覽、變量探索、相關性計算、缺失值情況和抽樣展示等5個方面。
數據整體概覽:
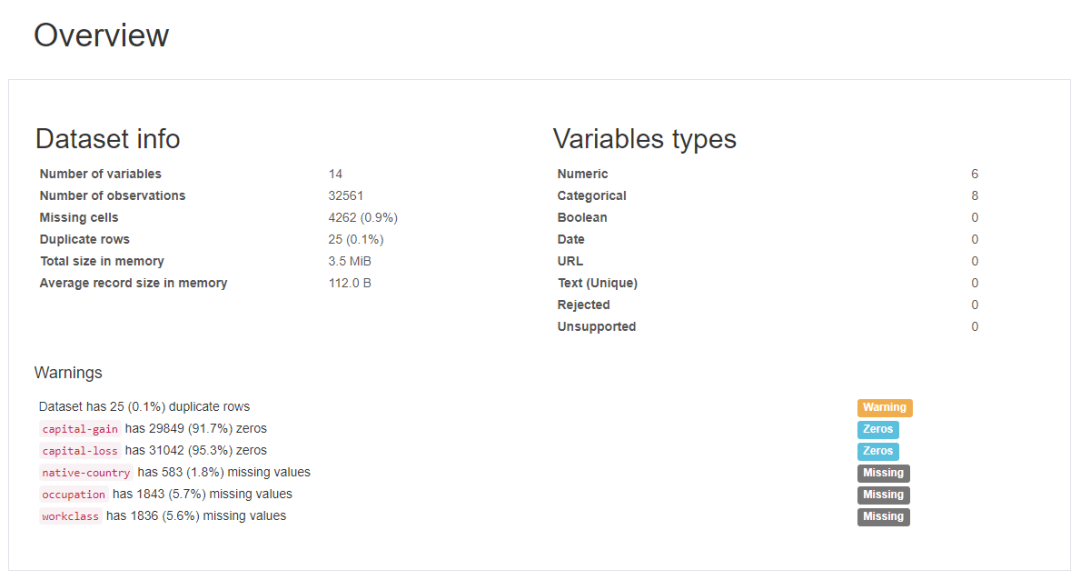
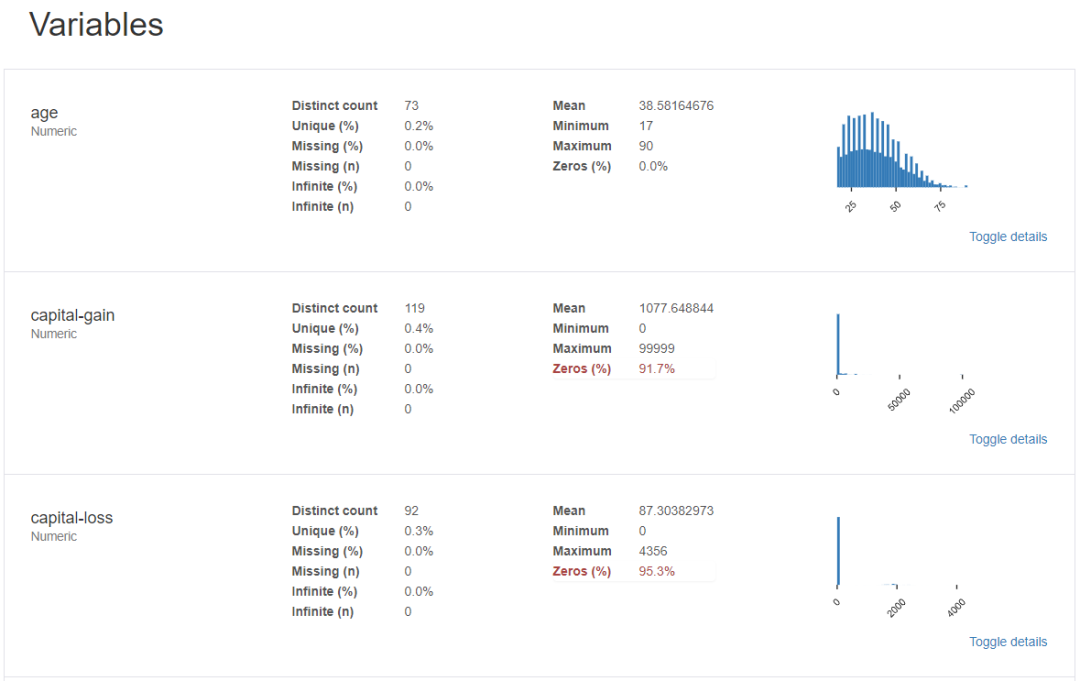
變量探索:
相關性計算:
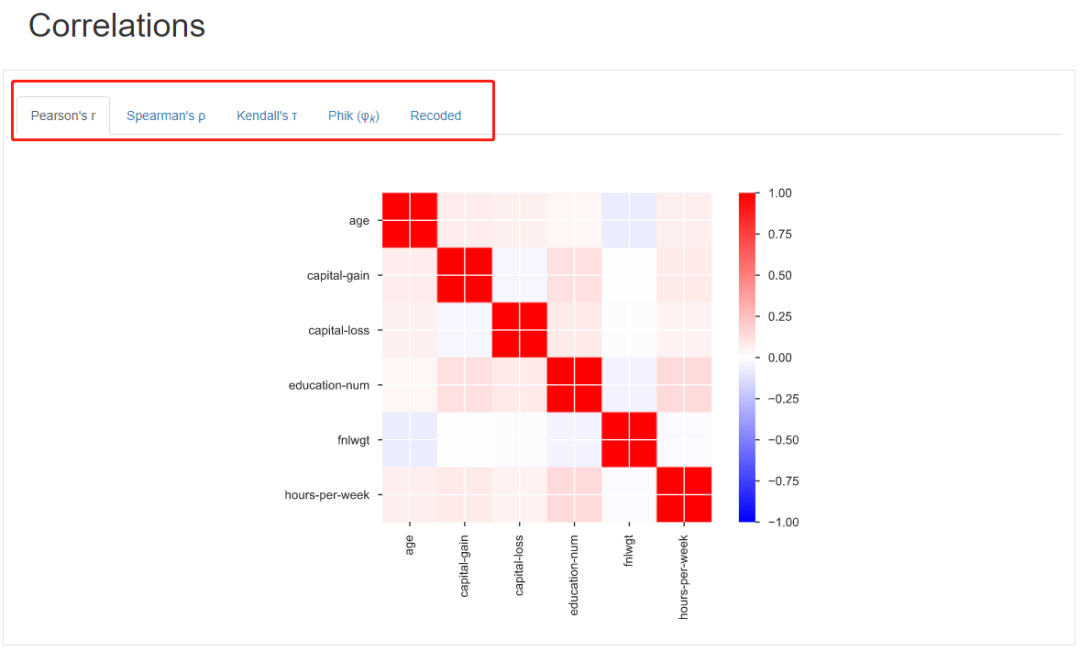
這里為大家提供5種相關性系數。
缺失值情況:
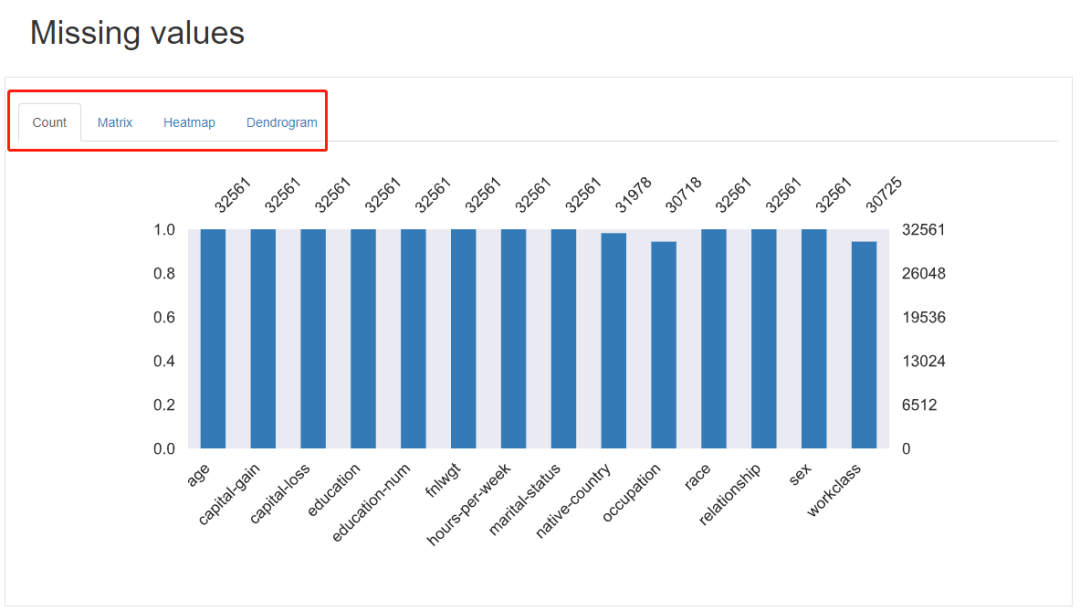
pandas-profiling為我們提供了四種缺失值展現形式。
數據樣本展示:
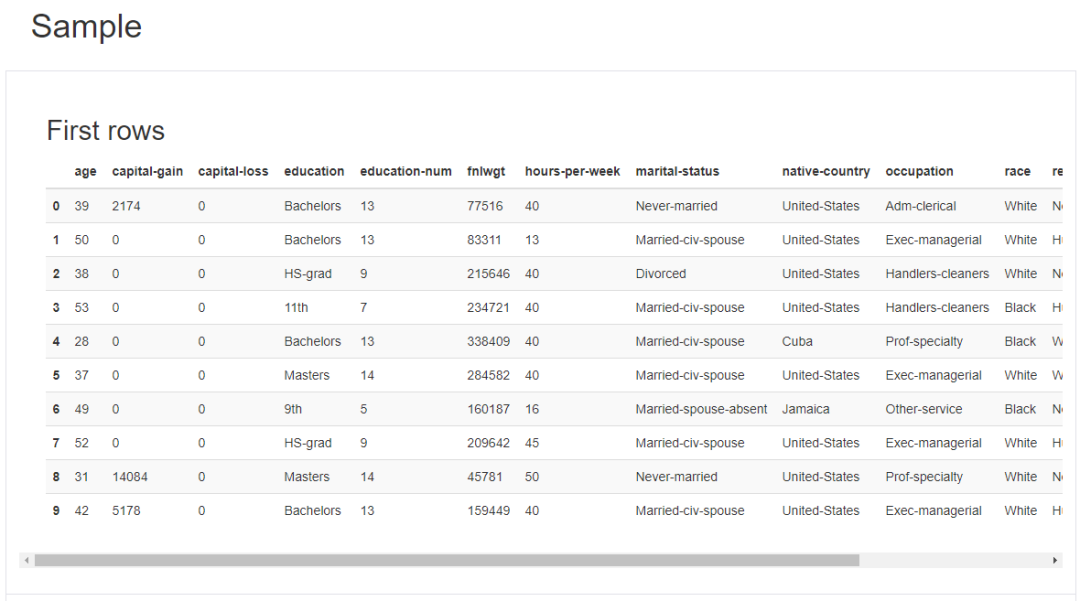
就是pandas里面的df.head()和df.tail()兩個函數。
上述示例參考代碼:
from pathlib import Pathimport pandas as pdimport numpy as npimport requestsimport pandas_profilingif __name__ == "__main__":file_name = Path("census_train.csv")if not file_name.exists():data = requests.get("https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data")file_name.write_bytes(data.content)# Names based on https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.namesdf = pd.read_csv(file_name,header=None,index_col=False,names=["age","workclass","fnlwgt","education","education-num","marital-status","occupation","relationship","race","sex","capital-gain","capital-loss","hours-per-week","native-country",],)# Prepare missing valuesdf = df.replace("\\?", np.nan, regex=True)profile = df.profile_report(title="Census Dataset")profile.to_file(output_file=Path("./census_report.html"))
除此之外,pandas_profiling還提供了pycharm配置方法:
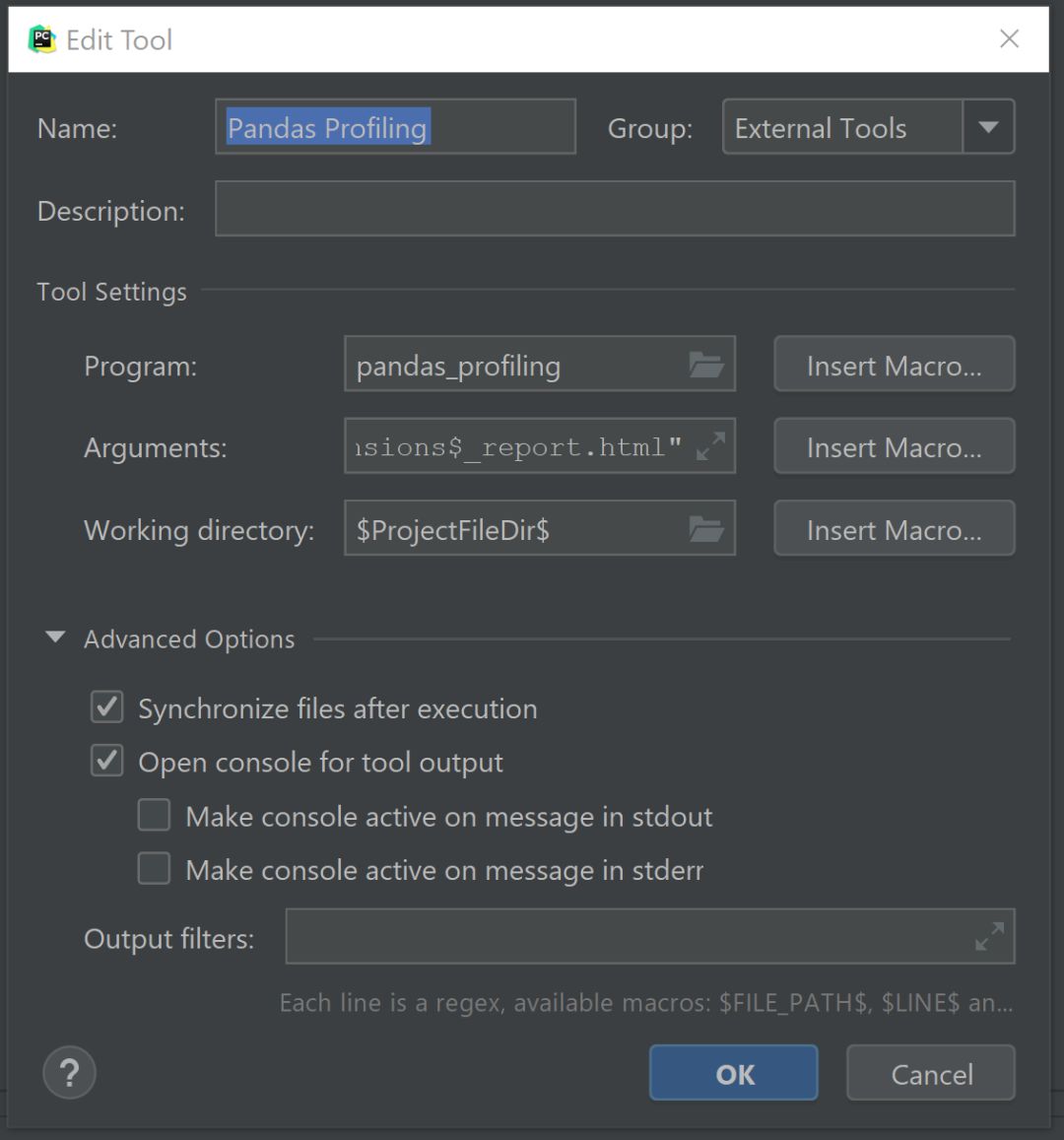
配置完成后在pycharm左邊項目欄目直接右鍵external_tool下的pandas_profiling即可直接生成EDA報告。更多內容大家可以到該項目GitHub地址查看:
關于如何使用pandas_profiling完成探索性數據分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





