溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關KEGG數據庫病毒基因組的下載是怎樣的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
KEGG數據庫蛋白序列數據的下載方法中存在兩個問題:
1. 在KEGG數據庫中病毒物種的命名并非像細胞生物一樣為小寫字母的縮寫,因此在批量下載時遇到病毒會報錯而無法下載,如下所示:
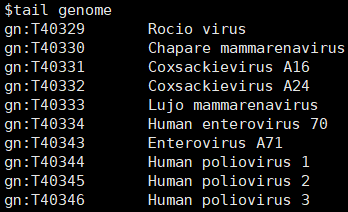
2. 在根據蛋白序列id下載序列時會出現下載不完整的情況,這樣在最終的合并時就會出現錯誤。
現針對以上兩個問題提供解決方案。首先針對第一個問題,在KEGG數據庫中病毒物種的名稱的確沒有標準縮寫,但是所有病毒可以用縮寫“vg”來表示(也即viral genome的縮寫),下載方法如下所示:
wget -c http://rest.kegg.jp/list/vg
這樣我們就獲得了所有病毒的蛋白列表,如下所示:
vg:23892186 CP, DU23_s2gp1; Arhar cryptic virus-II; Coat Proteinvg:24271495 LAT, HHV2s01; Human alphaherpesvirus 2; LATvg:1487286 RL1, HHV2p77; Human alphaherpesvirus 2; neurovirulence protein ICP34.5vg:1487288 RL2, HHV2p76; Human alphaherpesvirus 2; ubiquitin E3 ligase ICP0vg:1487292 UL1, HHV2p75; Human alphaherpesvirus 2; envelope glycoprotein Lvg:1487303 UL2, HHV2p74; Human alphaherpesvirus 2; uracil-DNA glycosylasevg:24271453 UL3, HHV2p73; Human alphaherpesvirus 2; nuclear protein UL3vg:1487326 UL4, HHV2p71; Human alphaherpesvirus 2; nuclear protein UL4vg:1487338 UL5, HHV2p72; Human alphaherpesvirus 2; helicase-primase helicase subunitvg:1487346 UL6, HHV2p70; Human alphaherpesvirus 2; capsid portal protein
其中左邊第一列即為病毒蛋白序列的id,可以遍歷id來獲得序列。
針對第二個問題,這是wget命令的一個缺陷,我們可以通過判斷每個文件的最后是否為換行符\n來判斷文件是否下載完整,如下所示:
tail -n1 <download_file> |wc -l
如果文件下載完整,最后一個字符為換行符,那么結果為1,否則為0,如下所示:
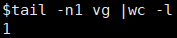
看完上述內容,你們對KEGG數據庫病毒基因組的下載是怎樣的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





