溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Oncomine腫瘤芯片數據庫的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Oncomine腫瘤芯片數據庫的示例分析”這篇文章吧。
腫瘤作為人類健康的頭號殺手,其研究的重要性不言而喻。隨著芯片和NGS技術的發展,發表了很多的腫瘤相關數據。然而這些數據來自不同的組織和團隊,由于缺乏統一的數據管理和組織,這些數據在發表之后就沒有再利用了,為了提高數據利用率,促進腫瘤研究的發展,Oncomine的開發團隊收集了各種來源的腫瘤相關的芯片數據,用標準化的分析流程處理這些數據,數據分析的結果通過web服務查詢和可視化,對應的文章鏈接如下
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1635162/
數據庫的網址如下
https://www.oncomine.org/resource/main.html
該網站只對科研工作者免費開放,需要學術郵箱注冊對應的賬號。該數據庫中主要收錄了以下兩種類型的腫瘤芯片數據
mRNA expression
DNA copy number
每批芯片數據用dataset表示,所有芯片數據對應的腫瘤類型和樣本數示意如下
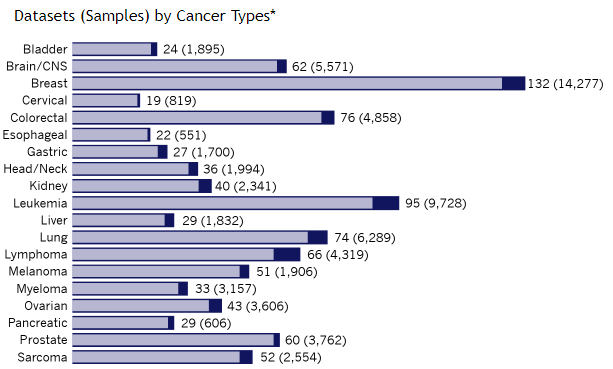
對于芯片數據,主要進行了以下幾種類型的分析
coexpression analyses
differential expression analyses
outlier analyses
首頁的面板分成了3個部分,示意如下
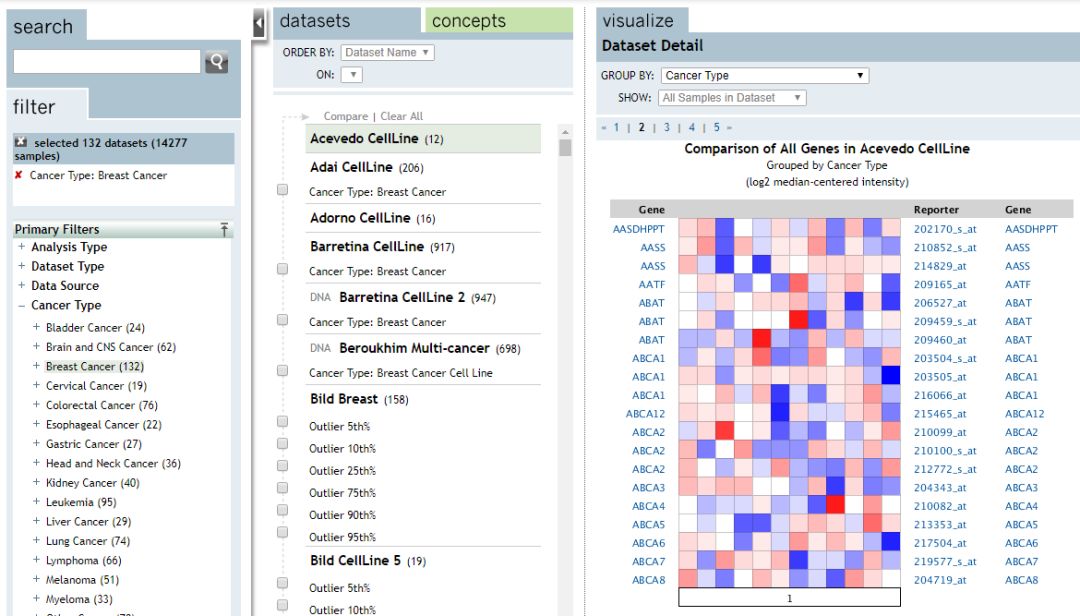
最左側的部分用于對數據進行檢索或者篩選,中間的面板用于展示所有的數據集,最右側的面板用于顯示數據集的詳細結果。最基本的展現形式是熱圖,示意如下
在search框中指定一個感興趣的基因,然后可以查看在特定數據集中與該基因存在共表達的基因結果,示意如下
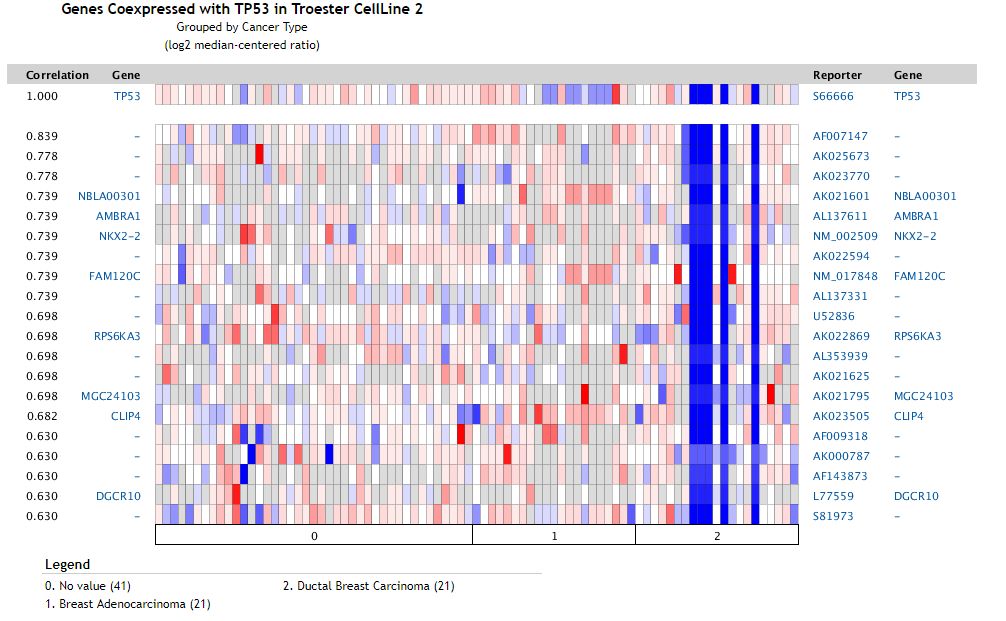
correlation從0到1,越接近于0, 說明相關性越高。
有以下兩種差異分析
cancer_vs_cancer
cancer_vs_normal
差異分析的熱圖示意如下
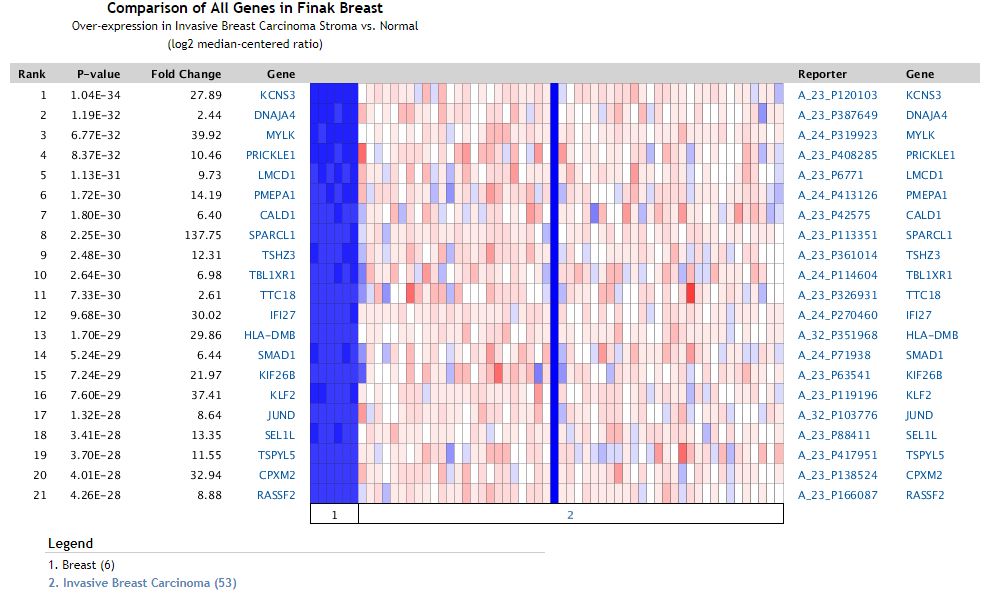
給出了差異的pvalue, fold change等統計學指標,對于多個基因的差異分析,用上述的熱圖形式展現,對于單個基因的差異分析結果,展現形式如下
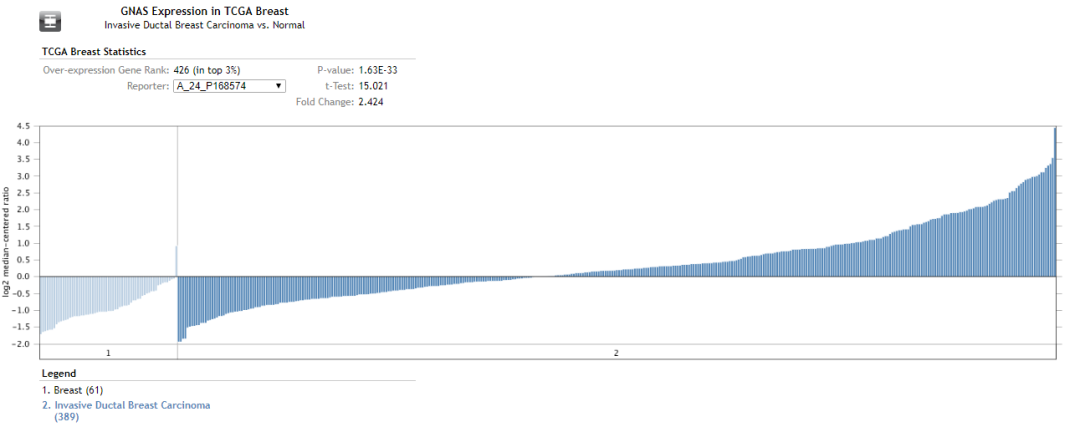
用柱狀圖的形式展示基因在每個樣本中的表達量,每個柱子代表一個樣本。
由于腫瘤樣本的異質性,會出現原癌基因只在部分樣本中過表達的例子,當用所有樣本進行差異分析時,這部分基因的差異分析結果并不顯著,為此專門開發了一種離群值分析的算法,全稱如下
cancer outlier profile analysis
簡稱COPA, 來識別只在部分腫瘤樣本中高表達的潛在的原癌基因。結果示意如下
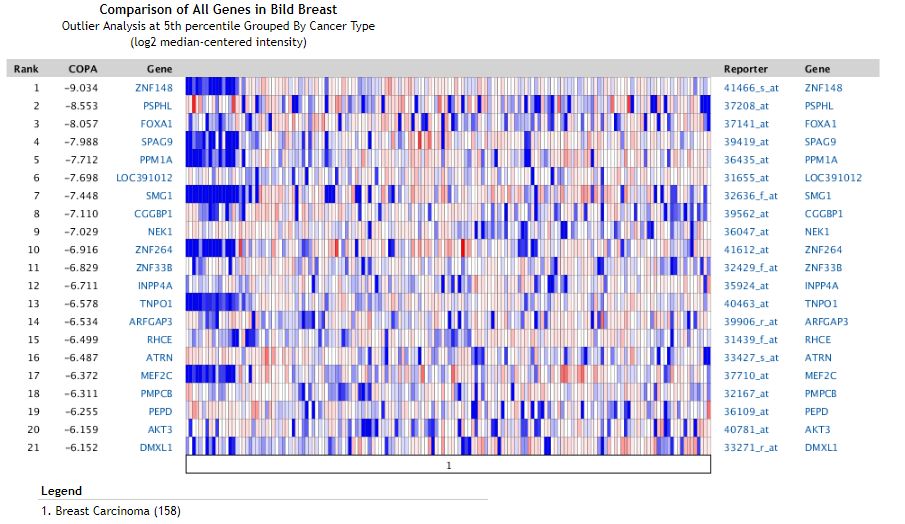
COPA值越高,說明該基因越可能是一個真實的離群基因。通過Oncomine數據庫,可以方便的探究腫瘤相關的DNA拷貝數和基因表達譜數據。
以上是“Oncomine腫瘤芯片數據庫的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





