溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解Spark Streaming的數據可靠性和一致性,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
眼下大數據領域最熱門的詞匯之一便是流計算了,其中最耀眼的項目無疑是來自Spark社區的Spark Streaming項目,其從一誕生就受到廣泛關注并迅速發展,目前已有追趕并超越Storm的架勢。
對于流計算而言,毫無疑問最核心的特點是它的低時延能力,這主要是來自對數據不落磁盤就進行計算的內部機制,但這也帶來了數據可靠性的問題,即有節點失效或者網絡異常時,如何在節點間進行合適的協商來進行重傳。更進一步的,若發生計劃外的數據重傳,怎么能保證沒有產生重復的數據,所有數據都是精確一次的(Exact Once)?如果不解決這些問題,大數據的流計算將無法滿足大多數企業級可靠性要求而流于徒有虛名。
下面將重點分析Spark Streaming是如何設計可靠性機制并實現數據一致性的。
由于流計算系統是長期運行、數據不斷流入的,因此其Spark守護進程(Driver)的可靠性是至關重要的,它決定了Streaming程序能否一直正確地運行下去。
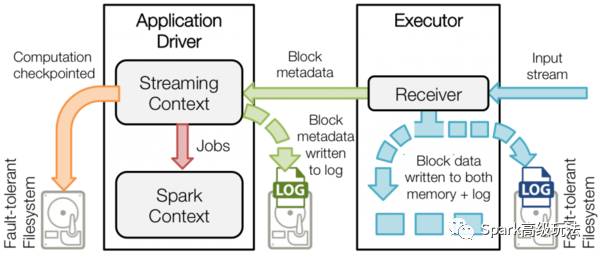
圖一 Driver數據持久化
Driver實現HA的解決方案就是將元數據持久化,以便重啟后的狀態恢復。如圖一所示,Driver持久化的元數據包括:
Block元數據(圖一中的綠色箭頭):Receiver從網絡上接收到的數據,組裝成Block后產生的Block元數據;
Checkpoint數據(圖一中的橙色箭頭):包括配置項、DStream操作、未完成的Batch狀態、和生成的RDD數據等;
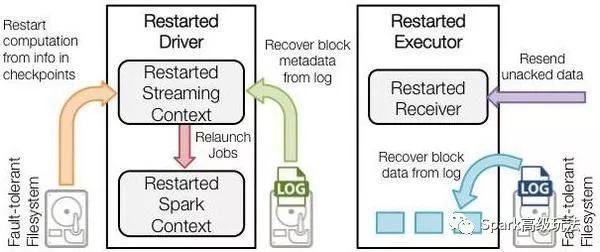
圖二 Driver故障恢復
Driver失敗重啟后:
恢復計算(圖二中的橙色箭頭):使用Checkpoint數據重啟driver,重新構造上下文并重啟接收器。
恢復元數據塊(圖二中的綠色箭頭):恢復Block元數據。
恢復未完成的作業(圖二中的紅色箭頭):使用恢復出來的元數據,再次產生RDD和對應的job,然后提交到Spark集群執行。
通過如上的數據備份和恢復機制,Driver實現了故障后重啟、依然能恢復Streaming任務而不丟失數據,因此提供了系統級的數據高可靠。
流計算主要通過網絡socket通信來實現與外部IO系統的數據交互。由于網絡通信的不可靠特點,發送端與接收端需要通過一定的協議來保證數據包的接收確認、和失敗重發機制。
不是所有的IO系統都支持重發,這至少需要實現數據流的持久化,同時還要實現高吞吐和低時延。在Spark Streaming官方支持的data source里面,能同時滿足這些要求的只有Kafka,因此在最近的Spark Streaming release里面,也是把Kafka當成推薦的外部數據系統。
除了把Kafka當成輸入數據源(inbound data source)之外,通常也將其作為輸出數據源(outbound data source)。所有的實時系統都通過Kafka這個MQ來做數據的訂閱和分發,從而實現流數據生產者和消費者的解耦。
一個典型的企業大數據中心數據流向視圖如下所示:
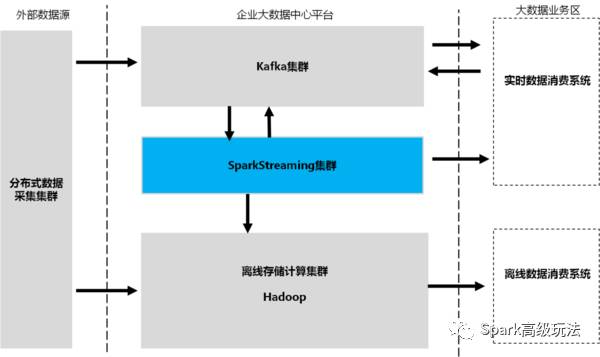
圖三 企業大數據中心數據流向視圖
除了從源頭保證數據可重發之外,Kafka更是流數據Exact Once語義的重要保障。Kafka提供了一套低級API,使得client可以訪問topic數據流的同時也能訪問其元數據。Spark Streaming的每個接收任務可以從指定的Kafka topic、partition和offset去獲取數據流,各個任務的數據邊界很清晰,任務失敗后可以重新去接收這部分數據而不會產生“重疊的”數據,因而保證了流數據“有且僅處理一次”。
在Spark 1.3版本之前,Spark Streaming是通過啟動專用的Receiver任務來完成從Kafka集群的數據流拉取。
Receiver任務啟動后,會使用Kafka的高級API來創建topicMessageStreams對象,并逐條讀取數據流緩存,每個batchInerval時刻到來時由JobGenerator提交生成一個spark計算任務。
由于Receiver任務存在宕機風險,因此Spark提供了一個高級的可靠接收器-ReliableKafkaReceiver類型來實現可靠的數據收取,它利用了Spark 1.2提供的WAL(Write Ahead Log)功能,把接收到的每一批數據持久化到磁盤后,更新topic-partition的offset信息,再去接收下一批Kafka數據。萬一Receiver失敗,重啟后還能從WAL里面恢復出已接收的數據,從而避免了Receiver節點宕機造成的數據丟失(以下代碼刪除了細枝末節的邏輯):
class ReliableKafkaReceiver{ private var topicPartitionOffsetMap: mutable.HashMap[TopicAndPartition, Long] = null private var blockOffsetMap: ConcurrentHashMap[StreamBlockId, Map[TopicAndPartition, Long]] = null override def onStart(): Unit = { // Initialize the topic-partition / offset hash map. topicPartitionOffsetMap = new mutable.HashMap[TopicAndPartition, Long] // Initialize the block generator for storing Kafka message. blockGenerator = new BlockGenerator(new GeneratedBlockHandler, streamId, conf) messageHandlerThreadPool = Utils.newDaemonFixedThreadPool( topics.values.sum, "KafkaMessageHandler") blockGenerator.start() val topicMessageStreams = consumerConnector.createMessageStreams( topics, keyDecoder, valueDecoder) topicMessageStreams.values.foreach { streams => streams.foreach { stream => messageHandlerThreadPool.submit(new MessageHandler(stream)) } } }啟用WAL后雖然Receiver的數據可靠性風險降低了,但卻由于磁盤持久化帶來的開銷,系統整體吞吐率會有明顯的下降。因此,在最新發布的Spark 1.3版本里,Spark Streaming增加了使用Direct API的方式來實現Kafka數據源的訪問。
引入了Direct API后,Spark Streaming不再啟動常駐的Receiver接收任務,而是直接分配給每個Batch及RDD最新的topic partition offset。job啟動運行后Executor使用Kafka的simple consumer API去獲取那一段offset的數據。
這樣做的好處不僅避免了Receiver宕機帶來的數據可靠性風險,同時也由于避免使用ZooKeeper做offset跟蹤,而實現了數據的精確一次性(以下代碼刪除了細枝末節的邏輯):
class DirectKafkaInputDStream{ protected val kc = new KafkaCluster(kafkaParams) protected var currentOffsets = fromOffsets override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = { val untilOffsets = clamp(latestLeaderOffsets(maxRetries)) val rdd = KafkaRDD[K, V, U, T, R]( context.sparkContext, kafkaParams, currentOffsets, untilOffsets, messageHandler) currentOffsets = untilOffsets.map(kv => kv._1 -> kv._2.offset) Some(rdd) }Spark 1.2開始提供了預寫日志能力,用于Receiver數據及Driver元數據的持久化和故障恢復。WAL之所以能提供持久化能力,是因為它利用了可靠的HDFS做數據存儲。
Spark Streaming預寫日志機制的核心API包括:
管理WAL文件的WriteAheadLogManager
讀/寫WAL的WriteAheadLogWriter和WriteAheadLogReader
基于WAL的RDD:WriteAheadLogBackedBlockRDD
基于WAL的Partition:WriteAheadLogBackedBlockRDDPartition
以上核心API在數據接收和恢復階段的交互示意圖如圖四所示。
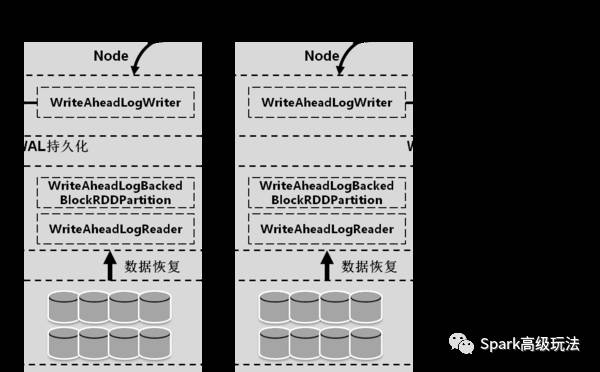
圖四 基于WAL的數據接收和恢復示意圖
從WriteAheadLogWriter的源碼里可以清楚地看到,每次寫入一塊數據buffer到HDFS后都會調用flush方法去強制刷入磁盤,然后才去取下一塊數據。因此receiver接收的數據是可以保證持久化到磁盤了,因而做到了較好的數據可靠性。
private[streaming] class WriteAheadLogWriter{ private lazy val stream = HdfsUtils.getOutputStream(path, hadoopConf) def write(data: ByteBuffer): WriteAheadLogFileSegment = synchronized { data.rewind() // Rewind to ensure all data in the buffer is retrieved val lengthToWrite = data.remaining() val segment = new WriteAheadLogFileSegment(path, nextOffset, lengthToWrite) stream.writeInt(lengthToWrite) if (data.hasArray) { stream.write(data.array()) } else { while (data.hasRemaining) { val array = new Array[Byte](data.remaining) data.get(array) stream.write(array) } } flush() nextOffset = stream.getPos() segment }看完上述內容,你們掌握如何理解Spark Streaming的數據可靠性和一致性的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





