溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Spark Streaming計算模型及監控,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
摘要
Spark Streaming是一套優秀的實時計算框架。其良好的可擴展性、高吞吐量以及容錯機制能夠滿足我們很多的場景應用。下面結合我們的應用場景,介結我們在使用Spark Streaming方面的技術架構,并著重講解Spark Streaming兩種計算模型,無狀態和狀態計算模型以及該兩種模型的注意事項;接著介紹了Spark Streaming在監控方面所做的一些事情,最后總結了Spark Streaming的優缺點。
一、概述
數據是非常寶貴的資源,對各級企事業單均有非常高的價值。但是數據的爆炸,導致原先單機的數據處理已經無法滿足業務的場景需求。因此在此基礎上出現了一些優秀的分布式計算框架,諸如Hadoop、Spark等。離線分布式處理框架雖然能夠處理非常大量的數據,但是其遲滯性很難滿足一些特定的需求場景,比如push反饋、實時推薦、實時用戶行為等。為了滿足這些場景,使數據處理能夠達到實時的響應和反饋,又隨之出現了實時計算框架。目前的實時處理框架有Apache Storm、Apache Flink以及Spark Streaming等。其中Spark Streaming由于其本身的擴展性、高吞吐量以及容錯能力等特性,并且能夠和離線各種框架有效結合起來,因而是當下是比較受歡迎的一種流式處理框架。
根據其官方文檔介紹,Spark Streaming 有高擴展性、高吞吐量和容錯能力強的特點。Spark Streaming 支持的數據輸入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和簡單的 TCP 套接字等等。數據輸入后可以用 Spark 的高度抽象原語如:map、reduce、join、window 等進行運算。而結果也能保存在很多地方,如 HDFS,數據庫等。另外 Spark Streaming 也能和 MLlib(機器學習)以及 Graphx ***融合。其架構見下圖:

Spark Streaming 其優秀的特點給我們帶來很多的應用場景,如網站監控和網絡監控、異常監測、網頁點擊、用戶行為、用戶遷移等。我們將為大家詳細介紹,我們的應用場景中,Spark Streaming的技術架構、兩種狀態模型以及Spark Streaming監控等。
二、應用場景
在 Spark Streaming 中,處理數據的單位是一批而不是單條,而數據采集卻是逐條進行的,因此 Spark Streaming 系統需要設置間隔使得數據匯總到一定的量后再一并操作,這個間隔就是批處理間隔。批處理間隔是 Spark Streaming 的核心概念和關鍵參數,它決定了 Spark Streaming 提交作業的頻率和數據處理的延遲,同時也影響著數據處理的吞吐量和性能。
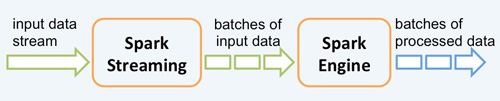
2.1 框架
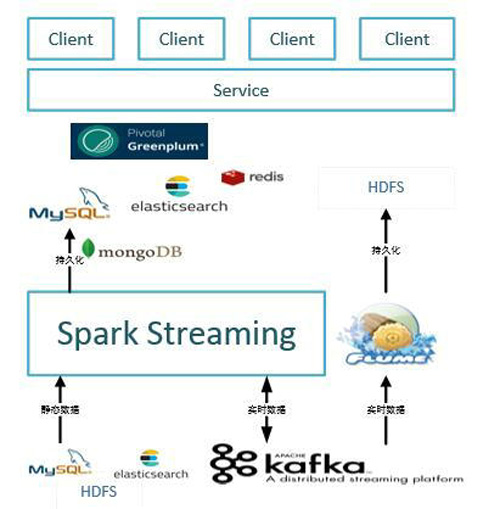
目前我們Spark Streaming的業務應用場景包括異常監測、網頁點擊、用戶行為以及用戶地圖遷徙等場景。按計算模型來看大體可分為無狀態的計算模型以及狀態計算模型兩種。在實際的應用場景中,我們采用Kafka作為實時輸入源,Spark Streaming作為計算引擎處理完數據之后,再持久化到存儲中,包括MySQL、HDFS、ElasticSearch以及MongoDB等;同時Spark Streaming 數據清洗后也會寫入Kafka,然后經由Flume持久化到HDFS;接著基于持久化的內容做一些UI的展現。架構見下圖:
2.2 無狀態模型
無狀態模型只關注當前新生成的DStream數據,所以的計算邏輯均基于該批次的數據進行處理。無狀態模型能夠很好地適應一些應用場景,比如網站點擊實時排行榜、指定batch時間段的用戶訪問以及點擊情況等。該模型由于沒有狀態,并不需要考慮有狀態的情況,只需要根據業務場景保證數據不丟就行。此種情況一般采用Direct方式讀取Kafka數據,并采用監聽器方式持久化Offsets即可。具體流程如下:
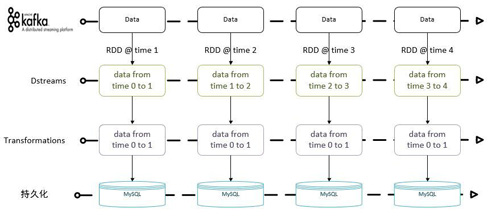
其上模型框架包含以下幾個處理步驟:
讀取Kafka實時數據;
Spark Streaming Transformations以及actions操作;
將數據結果持久化到存儲中,跳轉到步驟一。
受網絡、集群等一些因素的影響,實時程序出現長時失敗,導致數據出現堆積。此種情況下是丟掉堆積的數據從Kafka largest處消費還是從之前的Kafka offsets處消費,這個取決具體的業務場景。
2.3 狀態模型
有狀態模型是指DStreams在指定的時間范圍內有依賴關系,具體的時間范圍由業務場景來指定,可以是2個及以上的多個batch time RDD組成。Spark Streaming提供了updateStateByKey方法來滿足此類的業務場景。因涉及狀態的問題,所以在實際的計算過程中需要保存計算的狀態,Spark Streaming中通過checkpoint來保存計算的元數據以及計算的進度。該狀態模型的應用場景有網站具體模塊的累計訪問統計、最近N batch time 的網站訪問情況以及app新增累計統計等等。具體流程如下:

上述流程中,每batch time計算時,需要依賴最近2個batch time內的數據,經過轉換及相關統計,最終持久化到MySQL中去。不過為了確保每個計算僅計算2個batch time內的數據,需要維護數據的狀態,清除過期的數據。我們先來看下updateStateByKey的實現,其代碼如下:
暴露了全局狀態數據中的key類型的方法。
def updateStateByKey[S: ClassTag]( updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)], partitioner: Partitioner, rememberPartitioner: Boolean ): DStream[(K, S)] = ssc.withScope { new StateDStream(self, ssc.sc.clean(updateFunc), partitioner, rememberPartitioner, None) }隱藏了全局狀態數據中的key類型,僅對Value提供自定義的方法。
def updateStateByKey[S: ClassTag]( updateFunc: (Seq[V], Option[S]) => Option[S], partitioner: Partitioner, initialRDD: RDD[(K, S)] ): DStream[(K, S)] = ssc.withScope { val cleanedUpdateF = sparkContext.clean(updateFunc) val newUpdateFunc = (iterator: Iterator[(K, Seq[V], Option[S])]) => { iterator.flatMap(t => cleanedUpdateF(t._2, t._3).map(s => (t._1, s))) } updateStateByKey(newUpdateFunc, partitioner, true, initialRDD) }以上兩種方法分別給我們提供清理過期數據的思路:
泛型K進行過濾。K表示全局狀態數據中對應的key,如若K不滿足指定條件則反回false;
返回值過濾。第二個方法中自定義函數指定了Option[S]返回值,若過期數據返回None,那么該數據將從全局狀態中清除。
三、Spark Streaming監控
同Spark一樣,Spark Streaming也提供了Jobs、Stages、Storage、Enviorment、Executors以及Streaming的監控,其中Streaming監控頁的內容如下圖:
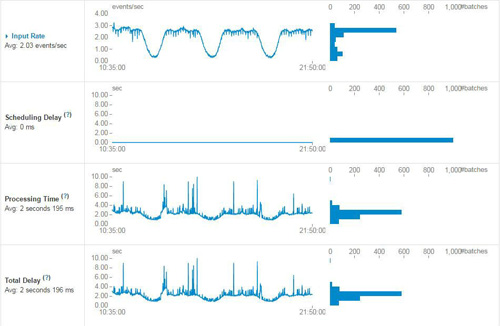
上圖是Spark UI中提供一些數據監控,包括實時輸入數據、Scheduling Delay、處理時間以及總延遲的相關監控數據的趨勢展現。另外除了提供上述數據監控外,Spark UI還提供了Active Batches以及Completed Batches相關信息。Active Batches包含當前正在處理的batch信息以及堆積的batch相關信息,而Completed Batches剛提供每個batch處理的明細數據,具體包括batch time、input size、scheduling delay、processing Time、Total Delay等,具體信息見下圖:
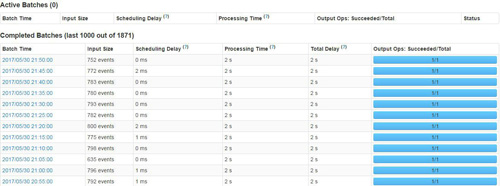
Spark Streaming能夠提供如此優雅的數據監控,是因在對監聽器設計模式的使用。如若Spark UI無法滿足你所需的監控需要,用戶可以定制個性化監控信息。Spark Streaming提供了StreamingListener特質,通過繼承此方法,就可以定制所需的監控,其代碼如下:
@DeveloperApi trait StreamingListener { /** Called when a receiver has been started */ def onReceiverStarted(receiverStarted: StreamingListenerReceiverStarted) { } /** Called when a receiver has reported an error */ def onReceiverError(receiverError: StreamingListenerReceiverError) { } /** Called when a receiver has been stopped */ def onReceiverStopped(receiverStopped: StreamingListenerReceiverStopped) { } /** Called when a batch of jobs has been submitted for processing. */ def onBatchSubmitted(batchSubmitted: StreamingListenerBatchSubmitted) { } /** Called when processing of a batch of jobs has started. */ def onBatchStarted(batchStarted: StreamingListenerBatchStarted) { } /** Called when processing of a batch of jobs has completed. */ def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) { } /** Called when processing of a job of a batch has started. */ def onOutputOperationStarted( outputOperationStarted: StreamingListenerOutputOperationStarted) { } /** Called when processing of a job of a batch has completed. */ def onOutputOperationCompleted( outputOperationCompleted: StreamingListenerOutputOperationCompleted) { } }目前,我們保存Offsets時,采用繼承StreamingListener方式,此是一種應用場景。當然也可以監控實時計算程序的堆積情況,并在達到一閾值后發送報警郵件。具體監聽器的定制還得依據應用場景而定。
四、Spark Streaming優缺點
Spark Streaming并非是Storm那樣,其并非是真正的流式處理框架,而是一次處理一批次數據。也正是這種方式,能夠較好地集成Spark 其他計算模塊,包括MLlib(機器學習)、Graphx以及Spark SQL。這給實時計算帶來很大的便利,與此帶來便利的同時,也犧牲作為流式的實時性等性能。
4.1 優點
Spark Streaming基于Spark Core API,因此其能夠與Spark中的其他模塊保持良好的兼容性,為編程提供了良好的可擴展性;
Spark Streaming 是粗粒度的準實時處理框架,一次讀取完或異步讀完之后處理數據,且其計算可基于大內存進行,因而具有較高的吞吐量;
Spark Streaming采用統一的DAG調度以及RDD,因此能夠利用其lineage機制,對實時計算有很好的容錯支持;
Spark Streaming的DStream是基于RDD的在流式數據處理方面的抽象,其transformations 以及actions有較大的相似性,這在一定程度上降低了用戶的使用門檻,在熟悉Spark之后,能夠快速上手Spark Streaming。
4.2 缺點
Spark Streaming是準實時的數據處理框架,采用粗粒度的處理方式,當batch time到時才會觸發計算,這并非像Storm那樣是純流式的數據處理方式。此種方式不可避免會出現相應的計算延遲 。
目前來看,Spark Streaming穩定性方面還是會存在一些問題。有時會因一些莫名的異常導致退出,這種情況下得需要自己來保證數據一致性以及失敗重啟功能等。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





