溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解Spark Streaming實現,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
要說流式微批處理類似Spark Streaming,就不得不說一下TCP流。典型的tcp IO流模型有,bio,偽異步IO,NIO,AIO,Rector模型等。我們這里主要是說偽異步IO。
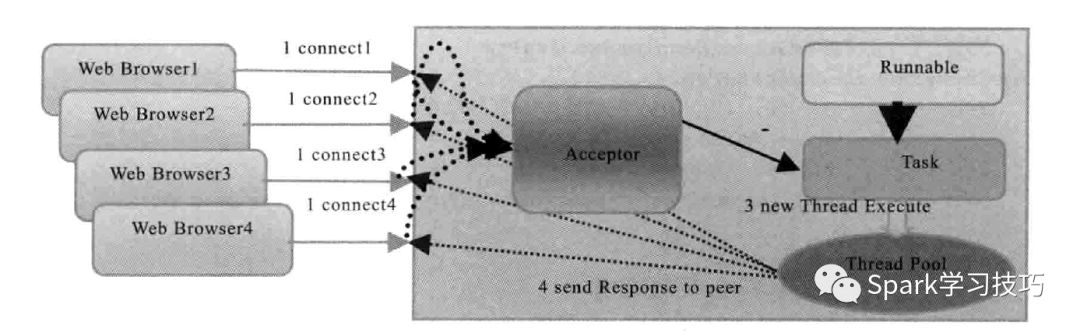
下面浪尖帶領一步步將其改造成spark Streaming的 SocketStream。
在偽異步模式,我們是客戶端通過TCP鏈接到服務端。這種在分布式模式下不可行,對于Spark Streaming的微批處理,我們根本不知道Receiver運行在何處。所以,客戶端鏈接都不知道請求到何處,當然,我們也可以做一個復雜的操作來報告我們Receiver的位置。所以,第一步要修改的是將我們的后端改為TCP的client端,然后是client主動鏈接于外部數據中心也即server端,去拉去或者被push數據。
然后,在上一步改裝之后,我們的模型就可能變成如下模式:
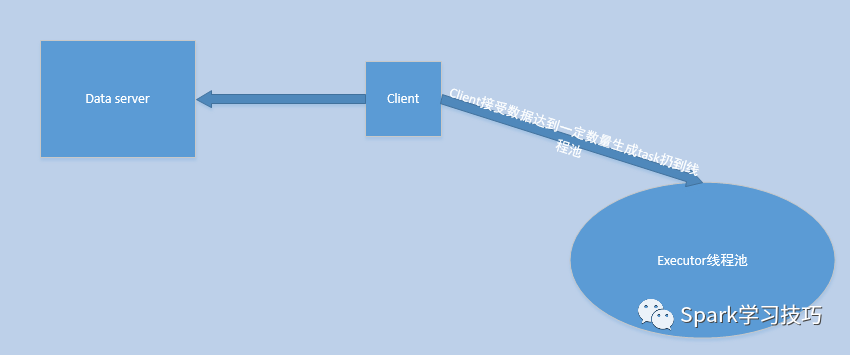
也即,client主動去data server建立連接請求,然后開始接收數據,接收數據達到一定的數目,比如1000條(也要有超時機制),然后封裝成task扔到線程池中執行。
當然,我們可以對他進行進一步完善,比如,一個線程專門負責接收數據,然后將數據緩存到map或者 Array里,我們在啟動一個RecurringTimer也即一個定時線程,每隔一定毫秒,比如200ms,將map或者Array里面的數據封裝成一個數據塊叫做block,存儲于一個內存的Array,然后用一個后臺線程阻塞的消費Array中的block并將block存儲于一個數據管理器里,比如叫做blockmanager。此時我們再用一個RecurringTimer用來每隔一定時間,如batch=5s,生成一個task,task中有task自身要處理的數據的描述信息,然后放入線程池中去執行,在執行的時候根據數據的描述信息去取0-n個block然后處理。
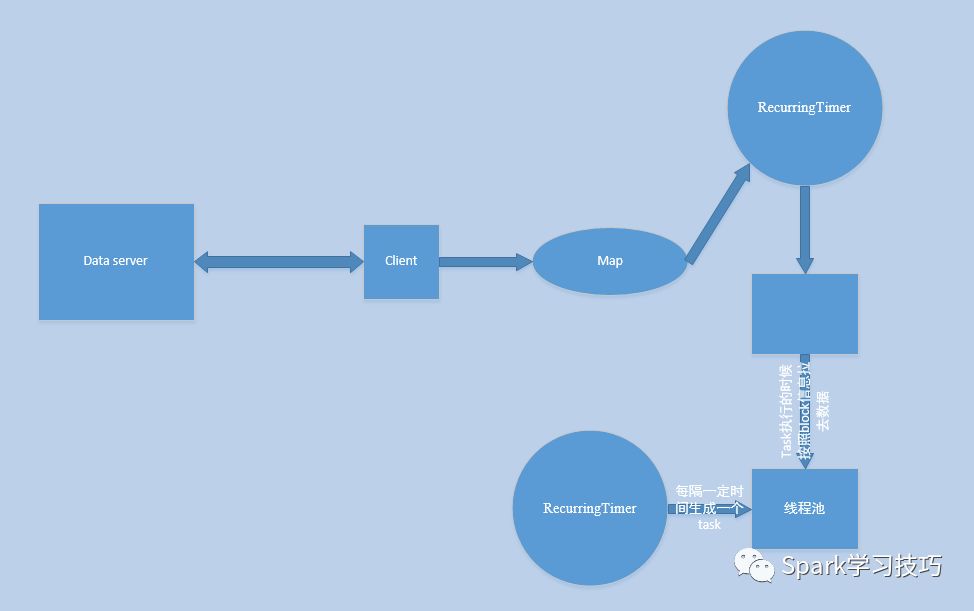
其實,上述步驟和spark Streaming基于Receiver這種模式很類似。
Spark Streaming在執行任務之前必須要先完成receiver的調度啟動,過程類似spark core的job調度執行。所以在receiver模式下,給executor分配core的時候,也要考慮receiver會占用一個cpu的。
receiver啟動后,其功能就像前面的說的偽異步IO模型一樣。由Receiver來完成數據收集緩存,然后定時器線程完成block生成并存儲于blockmanager的過程。
除了block數據生成,Spark Streaming還有一個spark core任務生成的過程。spark Streaming來說在生成job的時候,實際上是根據當前批次的數據block信息(由于窗口的存在也可能是批次的若干倍),封裝成了一個叫做BlockRDD的對象,blockrdd的分區數就是block數,然后就可以根據我們的Spark core的計算方式執行計算操作了,在每個分區生成的task根據其對應的blockid去取對應的block,實際上對于BlockRDD每個block對應與一個partition。
當然了,有些人該問了,spark Streaming不是還可以不基于Receiver么,另一種方式是什么情況呢?
在討論這個問題之前,我們先談另一個問題,那就是:有些數據源,比如kafka,數據本身是有分區的概念,而且可以使用offset靈活的獲取數據,也即是我們可以通過控制請求偏移,隨便去請求我們想要的數據。對于這種數據源,我們完全沒必要先把數據取回來存儲于blockmanager,然后再從blockmanager里面取出來再去處理(請注意這里先暫時忽略預寫日志),這明顯很浪費性能。網絡IO流這種,由于數據不能像kafka那樣存儲與本地,然后隨意取數據,只能先存下來再處理了。其實基于receiver的形式,才是Spark streaming的最多場景。
針對kafka這種消息隊列出現了一個模式那就是direct模式。也即是我們不用Receiver,生成block,然后構建blockRDD,每個Block當成一個partition;而是在生成job的時候,根據offset信息構建一個叫做KafkaRDD的對象,kafkaRDD里面分區的概念是與kafka內部topic分區一一對應的。然后,再執行spark core的job,計算每個分區生成的task時候,根據KafkaRDD內部的信息去kafka里面具體取數據。
可以看出direct這里面少了,Receiver相關的內容,不需要預寫日志,不需要數據來回落地等。提升了很大的性能。
關于如何理解Spark Streaming實現問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





