溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Hyperledger Fabric推薦Kafa用于生產環境。Kafa是一個分布式、具有水平伸縮能力、崩潰容錯能力的日志系統。在Hyperledger Fabric區塊鏈中可以有多個Kafka節點,使用zookeeper進行同步管理。本文將介紹Kfaka的基本工作原理,以及在HyperledgerFabric中使用Kafka和zookeeper實現共識的原理,并通過一個實例剖析Hyperledger Farbic中Kafka共識的達成過程。
如果希望快速掌握Fabric區塊鏈的鏈碼及應用開發,建議訪問匯智網的在線互動課程:
- Fabric區塊鏈Java開發詳解
- Fabric區塊鏈NodeJs開發詳解
Kafka本質上是一個消息處理系統,它使用的是經典的發布-訂閱模型。消息的消費者訂閱特定的主題,以便收到新消息的通知,生產者則負責消息的發布。
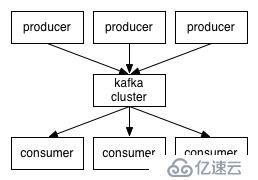
當主題的數據規模變得越來越大時,可以拆分為多個分區,Kafka保障在一個分區內的消息是按順序排列的。
Kafka并不跟蹤消費者讀取了哪些消息,也不會自動刪除已經讀取的消息。Kafka會保存消息一段時間,例如一天,或者直到數據規模超過一定的閾值。消費者需要輪詢新的消息,這是的他們可以根據自己的需求來定位消息,因此可以重放或重新處理事件。消費者處于不同的消費者分組,對應一個或多個消費者進程。每個分區被分貝給單一的消費者進程,因此同樣的消息不會被多次讀取。
崩潰容錯機制是通過在多個Kafka代理之間復制分區來實現的。因此如果一個代理由于軟件或硬件故障掛掉,數據也不會丟失。當然接下來還需要一個領導-跟隨機制,領導者持有分區,跟隨者則進行分區的復制。當領導者掛掉后,會有某個跟隨者轉變為新的領導者。
如果一個消費者訂閱了某個主體,那么它怎么知道從哪個分區領導者來讀取訂閱的消息?
答案在于zookeeper服務。
zookeeper是一個分布式key-value存儲庫,通常用于存儲元數據及集群機制的實現。zookeeper允許服務(Kafka代理)的客戶端訂閱變化并獲得實時通知。這就是代理如何確定應當使用哪個分區領導者的原因。zookeeper有超強的故障容錯能力,因此Kafka的運行嚴重依賴于它。
在zookeeper中存儲的元數據包括:
要理解在超級賬本Hyperledger Fabric中的Kafka是如何工作的,首先需要理解幾個重要的術語:
注意,雖然在Hyperledger Fabric中Kafka被稱為共識(Consensus),但是其核心是交易排序服務以及額外的崩潰容錯能力。
在Hyperledger Fabric中的Kafka實際運行邏輯如下:
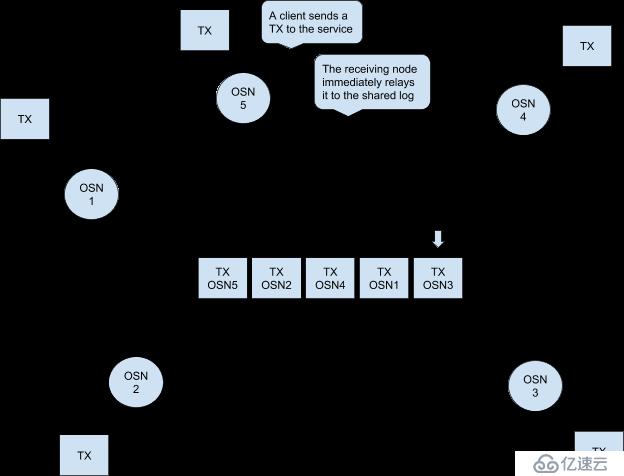
考慮下圖,假設排序節點OSN0和OSN2時連接到廣播客戶端,OSN1連接到分發客戶端。
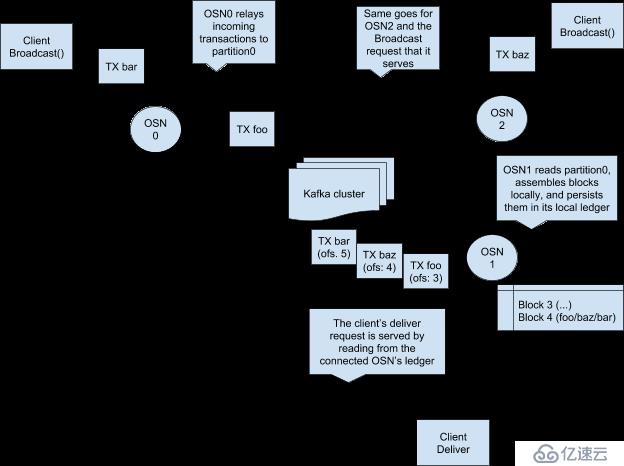
Kakfa的高性能對于Hyperledger Fabric有很大的幫助,多個排序節點通過Kafka實現同步,而Kafka本身并不是排序節點,它只是將排序節點通過流連接起來。雖然Kafka支持崩潰容錯,它并不能提供對網絡中惡意***的保護。需要一種拜占庭容錯方案(BFT)才可以對抗惡意的***,但是目前在Farbic框架中還有待實現這一機制。
總而言之,在Hyperledger Farbic中,Kafka共識模塊是可以用于生產環境的,它可以支持崩潰容錯,但無法對抗惡意***。
原文:The ABCs of Kafka in Hyperledger Fabric
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





