溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關HyperLedger中Fabric如何使用kafka進行區塊排序的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Kafka is a distributed streaming platform,也就是我們通常將的“消息隊列”。
生產者可以通過kafka將消息傳遞給消費者,kafka保證消息的順序以及不丟失:
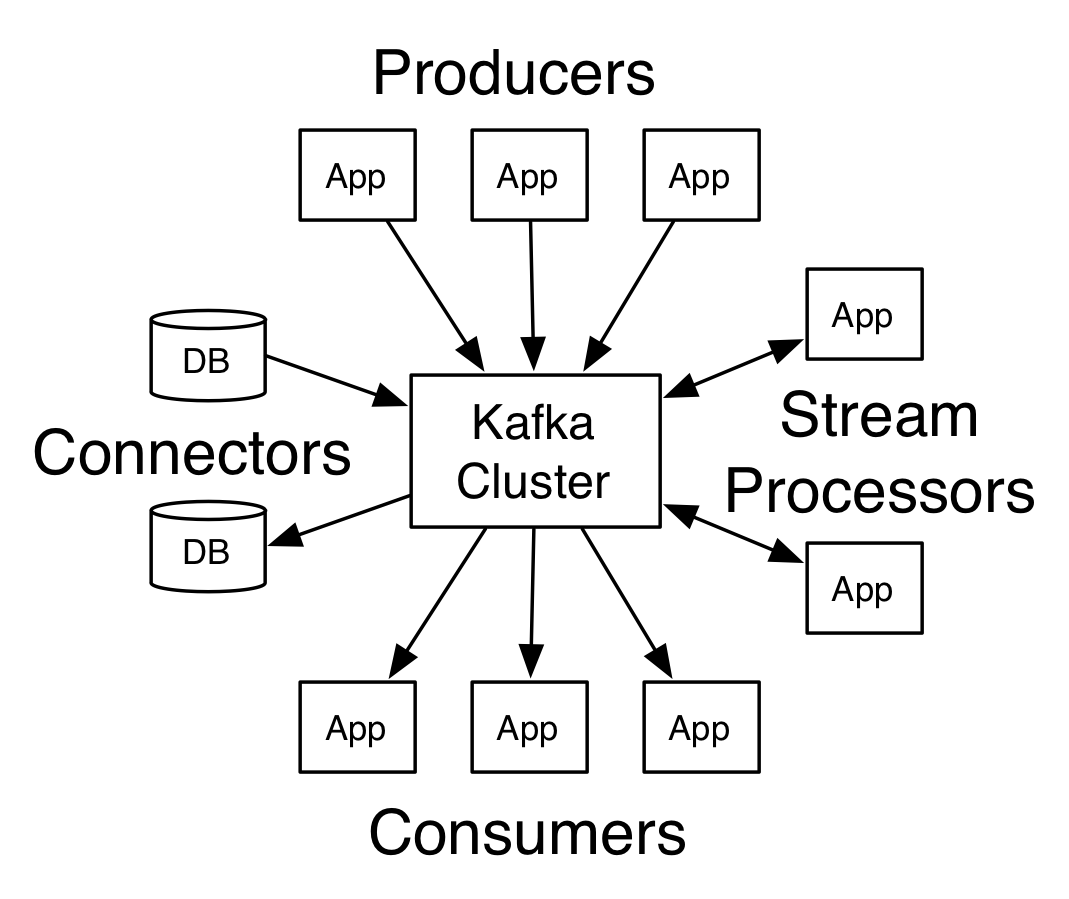
需要注意的是,kafka雖然是一個分布式系統,但它本身是被中心化管理,并且依賴zookeeper。
Fabric使用kafka的時候,為了安全,應當配置tls加密和認證,特別是經過公網的時候。為了演示不過于繁瑣,下面 沒有配置認證和tls加密,可以仔細研讀Generate SSL key and certificate for each Kafka broker,進行嘗試。
首先要有一個kafka集群,kafka本身是一個分布式系統,部署配置略復雜。
這里的重點是Fabric,因此只部署了單節點的kafk,參考kafka quick start。
下載kafka,下載地址:
wget http://mirror.bit.edu.cn/apache/kafka/1.1.1/kafka_2.12-1.1.1.tgz tar -xvf kafka_2.12-1.1.1.tgz cd kafka_2.12-1.1.1/
安裝java,運行kafka需要java:
$ yum install -y java-1.8.0-openjdk $ java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
啟動kafka自帶的zookeeper:
./bin/zookeeper-server-start.sh config/zookeeper.properties
根據HyperLedger Fabric對kafka的需求修改kafka的配置文件,可以到這里查看kafka的所有配置項):
# 默認為false unclean.leader.election.enable = false # 根據kafka的節點數設置,需要小于備份數 # 意思完成了“指定數量”的備份后,寫入才返回成功 min.insync.replicas = 1 # 數據備份數 default.replication.factor = 1 # 需要大于創世塊中設置的 Orderer.AbsoluteMaxBytes # 注意不要超過 socket.request.max.bytes(100M) # 這里設置的是10M message.max.bytes = 10000120 # 需要大于創世塊中設置的 Orderer.AbsoluteMaxBytes # 注意不要超過 socket.request.max.bytes(100M) # 這里設置的是10M replica.fetch.max.bytes = 10485760 # 當前orderer不支持kafka log,需要關閉這個功能 # @2018-07-29 08:19:32 log.retention.ms = -1
將上面的配置添加到config/server.properties中,然后啟動kafka:
bin/kafka-server-start.sh config/server.properties
注意,你可能需要根據自己的實際情況配置advertised.listeners,使用kafka的機器需要能夠通過 下面配置的hostname訪問對應的節點,默認獲取當前hostname,如果不配置hostname,可以修改為主機的對外IP。
#advertised.listeners=PLAINTEXT://your.host.name:9092
如果要進行多節點部署,在另一臺機器上用同樣方式部署:
注意更改server.properties中的zk地址,所有節點要使用同一個zk 其它節點不需要再啟動zookeeper
zookeeper也可以進行多節點部署,這里就不展開了,參考zookeeper的資料。
部署啟動后,測試一下kafka:
# 創建名為`test`的topic $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test # 查看topic $ bin/kafka-topics.sh --list --zookeeper localhost:2181 test # 啟動生產者,并輸入任意字符 $ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test >This is a message >This is another message # 啟動消費者,接收到生產者的輸入 $ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning This is a message This is another message
需要注意現在(@2018-07-29 08:20:48)Fabric不支持切換共識機制!一旦選定了共識機制后,無法修改,除非清空所有數據,重新部署。
修改configtx.yaml中Orderer部分的內容,將共識機制修改為kafka,并填入kafka節點的地址:
101 Orderer: &OrdererDefaults 102 OrdererType: kafka 103 Addresses: 104 - orderer0.member1.example.com:7050 105 BatchTimeout: 2s 106 BatchSize: 107 MaxMessageCount: 10 108 AbsoluteMaxBytes: 8 MB # 注意要小于kafka中設置的10M 109 PreferredMaxBytes: 512 KB 110 MaxChannels: 0 111 Kafka: 112 Brokers: 113 - 192.168.88.11:9092 # 可以填入多個kafka節點的地址
如果kafka配置了tls加密,還要修改修改每個orderer的配置文件orderer.yaml中的Kakfa部分的內容,并上傳證書。
重新生成創世塊,重新部署Fabric,即可。
./prepare.sh example ansible-playbook -i inventories/example.com/hosts -u root playbooks/manage_destroy.yml ansible-playbook -i inventories/example.com/hosts -u root deploy_nodes.yml ansible-playbook -i inventories/example.com/hosts -u root deploy_cli.yml ansible-playbook -i inventories/example.com/hosts -u root deploy_cli_local.yml
Fabric重新部署啟動后,可以看到kafka中多了一個名為genesis的topic,genesis是我們這里使用的創世區塊的channel的名稱:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181 __consumer_offsets genesis test
創建了名為mychannel的channel之后,kafka中多出了一個同名的topic:
$bin/kafka-topics.sh --list --zookeeper localhost:2181 __consumer_offsets genesis mychannel test
如果要重新部署,清空zk和kafka的數據:
rm -rf /tmp/zookeeper/ rm -rf /tmp/kafka-logs/
感謝各位的閱讀!關于“HyperLedger中Fabric如何使用kafka進行區塊排序”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





