溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python如何使用RegEx模塊處理正則表達式?針對這個問題,今天小編總結這篇有關RegEx模塊的文章,希望能幫助更多想解決這個問題的朋友找到更加簡單易行的辦法。
RegEx或正則表達式是形成搜索模式的字符序列
RegEx可用于檢查字符串是否包含指定的搜索模式
RegEx模塊
python提供名為 re 的內置包,可用于處理正則表達式。
導入re模塊
import re
導入RegEx模塊后,就可以使用正則表達式了:
實例
檢索字符串以查看它是否以“China”開頭并以“county”結尾:
import re
txt = "China is a great country"
x = re.search("^China.*country$", txt)
if(x):
print("YES! We have a match")
else:
print("No match");
RegEx函數
re模塊提供了一組函數,允許我們檢索字符串以進行匹配:
findall()
返回包含所有匹配項的列表
實例:
打印所有匹配的列表:
import re
str = "China is a great country"
x = re.findall("a", str)
print(x)

這個列表以被找到的順序包含匹配項。
如果未找到匹配項,返回空列表:
import re
str = "I want to go to school"
x = re.findall("KK", str)
print(x)
search()
如果字符串中的任意位置存在匹配,則返回Match對象
如果有多個匹配,則返回首個匹配項
search()函數搜索
import re
str = "I want to go to school"
x = re.search("\s", str)#返回字符串包含空白字符的匹配項
print("The first white-space character is located in position:", x.start())

如果未找到匹配,返回值None:
import re
str = "China is a great country"
x = re.search("English", str)
print(x)
finditer()
和findall類似,在字符串中找到正則表達式所匹配的所有子串,并把它們作為一個迭代器返回
import re
str = re.finditer(r"\d+","I18 want15 to13 go15 to school")#\d返回的是數字
for match in str:
print(match.group())
split()
返回一個列表,其中字符串在每次匹配時被拆分
實例:在每個空白字符處進行拆分
import re
str = "I want to go to school"
x = re.split("\s", str)
print(x)
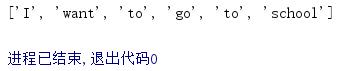
可以通過指定maxsplit參數來控制出現次數:
實例
僅在首次出現時拆分字符串:
import re
str = "I want to go to school"
x = re.split("\s", str, 1)
print(x)

sub()
re.sub(pattern, repl, string, count=0, flags=0)
用字符串替換一個或多個匹配項,就是把匹配替換為所選文本
實例
用數字8替換每個空白字符
import re
str = "I want to go to school"
x = re.sub("\s", "8", str)
print(x)

通過count 參數來控制替換次數
import re
str = "I want to go to school"
x = re.sub("\s", "8", str, 2)#只將兩個空白符換為8
print(x)
Match對象
Match 對象是包含有關搜索和結果信息的對象
注釋:如果沒有匹配,返回值None,而不是Match對象
import re
str = "I want to go to school"
x = re.search("a", str)
print(x)#打印一個對象
Match()對象提供了用于取回有關搜索及結果信息的屬性和方法:
span()返回的元組包含了匹配的開始和結束位置
string()返回傳入函數的字符串
group()返回匹配的字符串部分,group也包含三個部分
start()返回匹配開始的位置
end()返回匹配結束的位置
span()返回一個元組包含匹配(開始,結束)的位置
實例
打印首個匹配出現的位置(start, end)
正則表達式查找以大寫“W”開頭的任何單詞:
import re
str = "I Want to go to school"
x = re.search(r"\bW\w+", str)#\b是返回指定字符位于單詞的開頭或末尾的匹配項
print(x.span())鄭州婦科醫院哪家好 https://yiyuan.120ask.com/zzfck/
實例
打印傳入函數的字符串:
import re
str = ""I Want to go to school"
x = re.search(r"\bW\w+", str)
print(x.string)
實例
打印匹配的字符串部分
正則表達式查找以寫“W”開頭的任何單詞
import re
str = "I Want to go to school, the World is so quite"
x = re.search(r"\bW\w+", str)
print(x.group)

如果沒有匹配項,則返回值None,而不是Match對象
compile函數
compile函數用于編譯正則表達式,生成一個正則表達式(pattern)對象,供match()和search()這兩個函數使用。
import re
pattern = re.compile(r'\d+')
str = pattern.match("24Kobe Jodan23")#match查找頭部
print(str)
str1 = pattern.search("Jodan23")
print(str1)

re.match 與 re.search的區別
re.match只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回None;而re.search匹配整個字符串,知道找到一個匹配。
import re
str = "I want to go to school"
matchobj = re.match(r"to", str)
if matchobj:
print ("match --> matchobj.group() : ", matchobj.group())
else:
print ("No match!!")
matchobj = re.search(r"to", str)
if matchobj:
print ("search--> matchobj.group() : ", matchobj.group())
else:
print ("No match!!")

正則表達式模式及實例
模式字符串使用特殊的語法來表示一個正則表達式:
反斜杠+字母/數字擁有不同含義
因為正則表達式通常都包含反斜杠,所以最好使用原始字符串來表示它們,模式元素(如r’\b’ 等價于\ \b)匹配相應的特殊字符
元字符
特殊序列
是指在\后跟下表中的某個字符,擁有特殊含義
集合(set)
集合是一對方括號[]內的一組字符,具有特殊含義
以上就是RegEx模塊處理正則表達式的詳細內容,代碼示例簡單明了,如果在日常工作遇到此問題。通過這篇文章,希望你能有所收獲,更多詳情敬請關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





