溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“有哪些支撐StackOverflow運營的網站硬件配置”,在日常操作中,相信很多人在有哪些支撐StackOverflow運營的網站硬件配置問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”有哪些支撐StackOverflow運營的網站硬件配置”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
問答社區網絡 StackExchange 由 100 多個網站構成,其中包括了 Alexa 排名第 54 的 StackOverflow。StackExchang 有 400 萬用戶,每月 5.6 億 PV,但只用 25 臺服務器,并且 CPU 負荷并不高。
它沒有使用云計算,因為云計算可能會拖慢速度,更難優化和更難排除系統故障。
StackOverflow 仍然使用微軟的架構,它非常實際,微軟的基礎設施能有效工作,又足夠廉價,沒有令人信服的理由需要做出改變。但這并不表示它不使用 Linux,它將 Linux 用在有意義的地方。
它的 Windows 服務器運行的操作系統版本是 Windows 2012 R2,Linux 服務器運行 Centos 6.4。
網站數據庫 MS SQL 大小 2TB,全都儲存在 SSD 上,它有 11 臺運行 IIS 的 Web 服務器,2 臺運行 HAProxy 的負載均衡服務器,2 臺運行 Redis 的緩存服務器。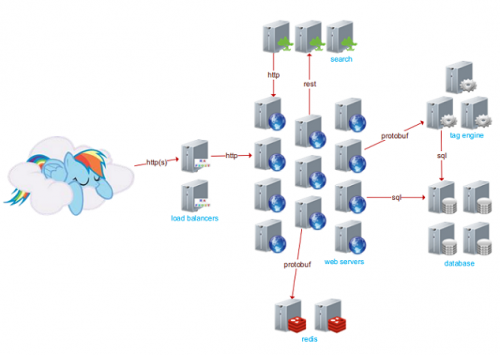
StackOverflow 是一個 IT 技術問答網站,用戶可以在網站上提交和回答問題。當下的 StackOverflow 已擁有 400 萬個用戶,4000 萬個回答,月 PV5.6 億,世界排行第 54。然而值得關注的是,支撐他們網站的全部服務器只有 25 臺,并且都保持著非常低的資源使用率,這是一場高有效性、負載均衡、緩存、數據庫、搜索及高效代碼上的較量。近日,High Scalability 創始人 Todd Hoff 根據 Marco Cecconi 的演講視頻“ The architecture of StackOverflow”以及 Nick Craver 的博文“ What it takes to run Stack Overflow”總結了 StackOverflow 的成功原因。
意料之中,也是意料之外,Stack Overflow 仍然重度使用著微軟的產品。他們認為既然微軟的基礎設施可以滿足需求,又足夠便宜,那么沒有什么理由去做根本上的改變。而在需要的地方,他們同樣使用了 Linux。究其根本,一切都是為了性能。
另一個值得關注的地方是,Stack Overflow 仍然使用著縱向擴展策略,沒有使用云。他們使用了 384GB 的內存和 2TB 的 SSD 來支撐 SQL Servers,如果使用 AWS 的話,花費可想而知。沒有使用云的另一個原因是 Stack Overflow 認為云會一定程度上的降低性能,同時也會給優化和排查系統問題增加難度。此外,他們的架構也并不需要橫向擴展。峰值期間是橫向擴展的殺手級應用場景,然而他們有著豐富的系統調整經驗去應對。該公司仍然堅持著 Jeff Atwood 的名言——硬件永遠比程序員便宜。
Marco Ceccon 曾提到,在談及系統時,有一件事情必須首先弄明白——需要解決問題的類型。首先,從簡單方面著手,StackExchange 究竟是用來做什么的——首先是一些主題,然后圍繞這些主題建立社區,最后就形成了這個令人敬佩的問答網站。
其次則是規模相關。StackExchange 在飛速增長,需要處理大量的數據傳輸,那么這些都是如何完成的,特別是只使用了 25 臺服務器,下面一起追根揭底:
狀態
StackExchange 擁有 110 個站點,以每個月 3 到 4 個的速度增長。
400 萬用戶
800 萬問題
4000 萬答案
世界排名 54 位
每年增長 100%
月 PV 5.6 億萬
大多數工作日期間峰值為 2600 到 3000 請求每秒,作為一個編程相關網站,一般情況下工作日的請求都會高于周末
25 臺服務器
SSD 中儲存了 2TB 的 SQL 數據
每個 web server 都配置了 2 個 320G 的 SSD,使用 RAID 1
每個 ElasticSearch 主機都配備了 300GB 的機械硬盤,同時也使用了 SSD
Stack Overflow 的讀寫比是 40:60
DB Server 的平均 CPU 利用率是 10%
11 個 web server,使用 IIS
2 個負載均衡器,1 個活躍,使用 HAProxy
4 個活躍的數據庫節點,使用 MS SQL
3 臺實現了 tag engine 的應用程序服務器,所有搜索都通過 tag
3 臺服務器通過 ElasticSearch 做搜索
2 臺使用了 Redis 的服務器支撐分布式緩存和消息
2 臺 Networks(Nexus 5596 + Fabric Extenders)
2 Cisco 5525-X ASAs
2 Cisco 3945 Routers
主要服務 Stack Exchange API 的 2 個只讀 SQL Servers
VM 用于部署、域控制器、監控、運維數據庫等場合
平臺
ElasticSearch
Redis
HAProxy
MS SQL
Opserver
TeamCity
Jil——Fast .NET JSON Serializer,建立在 Sigil 之上
Dapper——微型的 ORM
UI
UI 擁有一個信息收件箱,用于新徽章獲得、用戶發送信息、重大事件發生時的信息收取,使用 WebSockets 實現,并通過 Redis 支撐。
搜索箱通過 ElasticSearch 實現,使用了一個 REST 接口。
因為用戶提出問題的頻率很高,因此很難顯示最新問題,每秒都會有新的問題產生,從而這里需要開發一個關注用戶行為模式的算法,只給用戶顯示感興趣的問題。它使用了基于 Tag 的復雜查詢,這也是開發獨立 Tag Engine 的原因。
服務器端模板用于生成頁面。
服務器
25 臺服務器并沒有滿載,CPU 使用率并不高,單計算 SO(Stack Overflow)只需要 5 臺服務器。
數據庫服務器資源利用率在 10% 左右,除下執行備份時。
為什么會這么低?因為數據庫服務器足足擁有 384GB 內存,同時 web server 的 CPU 利用率也只有 10%-15%。
縱向擴展還沒有遇到瓶頸。通常情況下,如此流量使用橫向擴展大約需要 100 到 300 臺服務器。
簡單的系統。基于 .Net,只用了 9 個項目,其他系統可能需要 100 個。之所以使用這么少系統是為了追求極限的編譯速度,這點需要從系統開始時就進行規劃,每臺服務器的編譯時間大約是 10 秒。
11 萬行代碼,對比流量來說非常少。
使用這種極簡的方式主要基于幾個原因。首先,不需要太多測試,因為 Meta.stackoverflow 本來就是一個問題和 bug 討論社區。其次,Meta.stackoverflow 還是一個軟件的測試網站,如果用戶發現問題的話,往往會提出并給予解決方案。
紐約數據中心使用的是 Windows 2012,已經向 2012 R2 升級(Oregon 已經完成了升級),Linux 系統使用的是 Centos 6.4。
SSD
默認使用的是 Intel 330(Web 層等)
Intel 520 用于中間層寫入,比如 Elastic Search
數據層使用 Intel 710 和 S3700
系統同時使用了 RAID 1 和 RAID 10(任何4+ 以上的磁盤都使用 RAID 10)。不畏懼故障發生,即使生產環境中使用了上千塊 2.5 英寸 SSD,還沒碰到過一塊失敗的情景。每個模型都使用了 1 個以上的備件,多個磁盤發生故障的情景不在考慮之中。
ElasticSearch 在 SSD 上表現的異常出色,因為 SO writes/re-indexes 的操作非常頻繁。
SSD 改變了搜索的使用方式。因為鎖的問題,Luncene.net 并不能支撐 SO 的并發負載,因此他們轉向了 ElasticSearch。在全 SSD 環境下,并不需要圍繞 Binary Reader 建立鎖。
高可用性
異地備份——主數據中心位于紐約,備份數據中心在 Oregon。
Redis 有兩個從節點,SQL 有 2 個備份,Tag Engine 有 3 個節點,elastic 有 3 個節點,冗余一切,并在兩個數據中心同時存在。
Nginx 是用于 SSL,終止 SSL 時轉換使用 HAProxy。
并不是主從所有,一些臨時的數據只會放到緩存中
所有 HTTP 流量發送只占總流量的 77%,還存在 Oregon 數據中心的備份及一些其他的 VPN 流量。這些流量主要由 SQL 和 Redis 備份產生。
數據庫
MS SQL Server
Stack Exchange 為每個網站都設置了數據庫,因此 Stack Overflow 有一個、Server Fault 有一個,以此類推。
在紐約的主數據中心,每個集群通常都使用 1 主和 1 只讀備份的配置,同時還會在 Oregon 數據中心也設置一個備份。如果是運行的是 Oregon 集群,那么兩個在紐約數據中心的備份都會是只讀和同步的。
為其他內容準備的數據庫。這里還存在一個“網絡范圍”的數據庫,用于儲存登陸憑證和聚合數據(大部分是 stackexchange.com 用戶文件或者 API)。
Careers Stack Overflow、stackexchange.com 和 Area 51 等都擁有自己獨立的數據庫模式。
模式的變化需要同時提供給所有站點的數據庫,它們需要向下兼容,舉個例子,如果需要重命名一個列,那么將非常麻煩,這里需要進行多個操作:增加一個新列,添加作用在兩個列上的代碼,給新列寫數據,改變代碼讓新列有效,移除舊列。
并不需要分片,所有事情通過索引來解決,而且數據體積也沒那么大。如果有 filtered indexes 需求,那么為什么不更高效的進行?常見模式只在 DeletionDate = Null 上做索引,其他則通過為枚舉指定類型。每項 votes 都設置了 1 個表,比如一張表給 post votes,1 張表給 comment votes。大部分的頁面都可以實時渲染,只為匿名用戶緩存,因此,不存在緩存更新,只有重查詢。
Scores 是非規范化的,因此需要經常查詢。它只包含 IDs 和 dates,post votes 表格當下大約有 56454478 行,使用索引,大部分的查詢都可以在數毫秒內完成。
Tag Engine 是完全獨立的,這就意味著核心功能并不依賴任何外部應用程序。它是一個巨大的內存結構數組結構,專為 SO 用例優化,并為重負載組合進行預計算。Tag Engine 是個簡單的 windows 服務,冗余的運行在多個主機上。CPU 使用率基本上保持在2-5%,3 個主機專門用于冗余,不負責任何負載。如果所有主機同時發生故障,網絡服務器將把 Tag Engine 加載到內存中持續運行。
關于 Dapper 無編譯器校驗查詢與傳統 ORM 的對比。使用編譯器有很多好處,但在運行時仍然會存在 fundamental disconnect 問題。同時更重要的是,由于生成 nasty SQL,通常情況還需要去尋找原始代碼,而 Query Hint 和 parameterization 控制等能力的缺乏更讓查詢優化變得復雜。
編碼
流程
大部分程序員都是遠程工作,自己選擇編碼地點
編譯非常快
然后運行少量的測試
一旦編譯成功,代碼即轉移至開發交付準備服務器
通過功能開關隱藏新功能
在相同硬件上作為其他站點測試運行
然后轉移至 Meta.stackoverflow 測試,每天有上千個程序員在使用,一個很好的測試環境
如果通過則上線,在更廣大的社區進行測試
大量使用靜態類和方法,為了更簡單及更好的性能
編碼過程非常簡單,因為復雜的部分被打包到庫里,這些庫被開源和維護。.Net 項目數量很低,因為使用了社區共享的部分代碼。
開發者同時使用 2 到 3 個顯示器,多個屏幕可以顯著提高生產效率。
緩存
緩存一切
5 個等級的緩存
1 級是網絡級緩存,緩存在瀏覽器、CDN 以及代理服務器中。
2 級由 .Net 框架 HttpRuntime.Cache 完成,在每臺服務器的內存中。
3 級 Redis,分布式內存鍵值存儲,在多個支撐同一個站點的服務器上共享緩存項。
4 級 SQL Server Cache,整個數據庫,所有數據都被放到內存中。
5 級 SSD。通常只在 SQL Server 預熱后才生效。
舉個例子,每個幫助頁面都進行了緩存,訪問一個頁面的代碼非常簡單:
使用了靜態的方法和類。從 OOP 角度來看確實很糟,但是非常快并有利于簡潔編碼。
緩存由 Redis 和 Dapper 支撐,一個微型 ORM
為了解決垃圾收集問題,模板中 1 個類只使用 1 個副本,被建立和保存在緩存中。監測一切,包括 GC 操。據統計顯示,間接層增加 GC 壓力達到了某個程度時會顯著的降低性能。
CDN Hit 。鑒于查詢字符串基于文件內容進行哈希,只在有新建立時才會被再次取出。每天 3000 萬到 5000 萬 Hit,帶寬大約為 300GB 到 600GB。
CDN 不是用來應對 CPU 或I/O負載,而是幫助用戶更快的獲得答案
部署
每天 5 次部署,不去建立過大的應用。主要因為
可以直接的監視性能
盡可能最小化建立,可以工作才是重點
產品建立后再通過強大的腳本拷貝到各個網頁層,每個服務器的步驟是:
通過 POST 通知 HAProxy 下架某臺服務器
延遲 IIS 結束現有請求(大約 5 秒)
停止網站(通過同一個 PSSession 結束所有下游)
Robocopy 文件
開啟網站
通過另一個 POST 做 HAProxy Re-enable
幾乎所有部署都是通過 puppet 或 DSC,升級通常只是大幅度調整 RAID 陣列并通過 PXE boot 安裝,這樣做非常快速。
協作
團隊
SRE (System Reliability Engineering):5 人
Core Dev(Q&A site)6-7 人
Core Dev Mobile:6 人
Careers 團隊專門負責 SO Careers 產品開發:7 人
Devops 和開發者結合的非常緊密
團隊間變化很大
大部分員工遠程工作
辦公室主要用于銷售,Denver 和 London 除外
一切平等,些許偏向紐約工作者,因為面對面有助于工作交流,但是在線工作影響也并不大
對比可以在同一個辦公室辦公,他們更偏向熱愛產品及有才華的工程師,他們可以很好的衡量利弊
許多人因為家庭而選擇遠程工作,紐約是不錯,但是生活并不寬松
辦公室設立在曼哈頓,那是個人才的誕生地。數據中心不能太偏,因為經常會涉及升級
打造一個強大團隊,偏愛極客。早期的微軟就聚集了大量極客,因此他們征服了整個世界
Stack Overflow 社區也是個招聘的地點,他們在那尋找熱愛編碼、樂于助人及熱愛交流的人才。
編制預算
預算是項目的基礎。錢只花在為新項目建立基礎設施上,如此低利用率的 web server 還是 3 年前數據中心建立時購入。
測試
快速迭代和遺棄
許多測試都是發布隊伍完成的。開發擁有一個同樣的 SQL 服務器,并且運行在相同的 Web 層,因此性能測試并不會糟糕。
非常少的測試。Stack Overflow 并沒有進行太多的單元測試,因為他們使用了大量的靜態代碼,還有一個非常活躍的社區。
基礎設施改變。鑒于所有東西都有雙份,所以每個舊配置都有備份,并使用了一個快速故障恢復機制。比如,keepalived 可以在負載均衡器中快速回退。
對比定期維護,他們更愿意依賴冗余系統。SQL 備份用一個專門的服務器進行測試,只為了可以重存儲。計劃做每兩個月一次的全數據中心故障恢復,或者使用完全只讀的第二數據中心。
每次新功能發布都做單元測試、集成測試盒 UI 測試,這就意味著可以預知輸入的產品功能測試后就會推送到孵化網站,即 meta.stackexchange(原 meta.stackoverflow)。
監視/日志
當下正在考慮使用 http://logstash.net/做日志管理,目前使用了一個專門的服務將 syslog UDP 傳輸到 SQL 數據庫中。網頁中為計時添加 header,這樣就可以通過 HAProxy 來捕獲并且融合到 syslog 傳輸中。
Opserver 和 Realog 用于顯示測量結果。Realog 是一個日志展示系統,由 Kyle Brandt 和 Matt Jibson 使用 Go 建立。
日志通過 HAProxy 負載均衡器借助 syslog 完成,而不是 IIS,因為其功能比 IIS 更豐富。
關于云
還是老生常談,硬件永遠比開發者和有效率的代碼便宜。基于木桶效應,速度肯定受限于某個短板,現有的云服務基本上都存在容量和性能限制。
如果從開始就使用云來建設 SO 說不定也會達到現在的水準。但毫無疑問的是,如果達到同樣的性能,使用云的成本將遠遠高于自建數據中心。
性能至上
StackOverflow 是個重度的性能控,主頁加載的時間永遠控制在 50 毫秒內,當下的響應時間是 28 毫秒。
程序員熱衷于降低頁面加載時間以及提高用戶體驗。
每個獨立的網絡提交都予以計時和記錄,這種計量可以弄清楚提升性能需要修改的地方。
如此低資源利用率的主要原因就是高效的代碼。web server 的 CPU 平均利用率在5% 到 15% 之間,內存使用為 15.5 GB,網絡傳輸在 20 Mb/s到 40 Mb/s。SQL 服務器的 CPU 使用率在5% 到 10% 之間,內存使用是 365GB,網絡傳輸為 100 Mb/s到 200 Mb/s。這可以帶來 3 個好處:給升級留下很大的空間;在嚴重錯誤發生時可以保持服務可用;在需要時可以快速回檔。我更愿意把Stack Overflow看作是能夠運行于大規模數據下,但本身并不算大規模的(running with scale but not at scale)。意思是我們的網站非常有效率,但至少目前為止,我們的規模還不夠“大”。讓我們通過一些數字來介紹Stack Overflow當前是一個怎樣的規模吧。以下是一些核心的數字,來自于不久前在一整天(24小時)內的統計,準確說是2013年11月12日。這是一個典型的工作日,并且只統計了我們活動的數據中心,也就是我們自己的服務器。那些對CDN節點的請求和流量被排除在外,因為它們并不直接訪問我們的網絡。
負載均衡器接受了148,084,833次HTTP請求
其中36,095,312次是加載頁面
833,992,982,627 bytes (776 GB) 的HTTP流量用于發送
總共接收了286,574,644,032 bytes (267 GB) 數據
總共發送了1,125,992,557,312 bytes (1,048 GB) 數據
334,572,103次SQL查詢(僅包含來自于HTTP請求的)
412,865,051次Redis請求
3,603,418次標簽引擎請求
耗時558,224,585 ms (155 hours) 在SQL查詢上
耗時99,346,916 ms (27 hours) 在Redis請求上
耗時132,384,059 ms (36 hours) 在標簽引擎請求上
耗時2,728,177,045 ms (757 hours) 在ASP.Net程序處理上
(我覺得應該發表一篇文章介紹我們如何快速采集這些數據,以及為什么值得耗費精力去獲取它們)
注意以上數字包括了整個Stack Exchange網絡,但那并不是我們全部的。除此之外,這些數字也僅僅來自于我們為了檢測性能而記錄的HTTP請求。“哇,一天有這么多個小時,你們怎么做到的?”我們把這叫做魔法,當然有些人喜歡說成“許多個有多核處理器的服務器”,但我們依然堅持這是魔法。以下是那個數據中心里運行Stack Exchange網絡的設備:
4個MS SQL 服務器
11個IIS服務器
2個Redis服務器
3個標簽引擎服務(任何針對標簽的請求都會訪問它們,比如/questions/tagged/c++)
3個ElasticSearch服務器
2個負載均衡器(HAProxy)
2個交換機(Nexus 5596和Fabric Extenders)
2個Cisco 5525-X ASA (可看作是防火墻)
2個Cisco 3945 Router
有圖有真相:
我們不僅僅運行網站,旁邊架子上還有一些運行著虛擬機的服務器和其他設備,它們并不直接服務于網站,而是進行部署、域名控制、監控、操作數據庫等其他工作。上面列表中的兩個數據庫服務器之前一直都是用作備份,直到最近才作為只讀的負載(主要用于Stack Exchange API),于是我們可以不需要太多考慮便繼續擴大規模了。Web服務器有兩個分別用于開發和存儲元數據,運行負載非常低。
讓我們再來總結一下:
核心設備
如果除去那些多余的設備,以下是Stack Exchange運行需要的(保持目前的性能水平):
2個MS SQL服務器(Stack Overflow在一臺,其他的在另一臺,實際上只需一臺機器運行還能有富余)
2個Web服務器(或許3個吧,不過我有信心2個足矣)
1個Redis服務器
1個標簽引擎服務器
1個ElasticSearch服務器
1個負載均衡器
1個交換機
1個ASA
1個路由器
(我們真該找個機會嘗試這個配置,關閉部分設備,看看極限在哪)
現在還有一些虛擬機運行在后臺,執行一些輔助功能,比如域名控制等等。但那都是些相當低負載的任務,我們就不做討論了,這里把重心放在Stack Overflow本身,看看它是怎樣全速加載出頁面的。如果你希望更精確全面,可以增加一個VMware虛擬機進來,用于執行所有的輔助工作。這樣看來并不需要很多機器,但是這些機器的規格通常在云上難以實現,除非你有足夠多的錢。以下是這些“增強型”服務器簡要的配置介紹:
數據庫服務器有384GB內存和1.8TB的SSD硬盤
Redis服務器有96GB內存
ElasticSearch服務器有196GB內存
標簽引擎服務器有著我們能買得起的最快的處理器
交換機每個端口有10Gb的帶寬
Web服務器不是很特別,有32GB內存、2個4核處理器和300GB的SSD硬盤
有些服務器有2個10Gb帶寬的接口(比如數據庫),其他有4個1Gb帶寬的
20Gb的帶寬太多余了?你還真特么說對了,活動的數據庫服務器平均只利用了20Gb通道中的100-200Mb。然而,像備份、重建等等操作,根據當前內存和SSD硬盤的情況,可以使帶寬完全飽和,所以說這樣設計還是有意義的。
存儲設備
我們目前有大約2TB的數據庫存儲(第一個集群有18塊SSD硬盤—— 總共1.63TB,使用1.06TB;第二個集群由4塊SSD硬盤組成—— 總共1.45TB,使用889GB),這是我們在云服務器上需要的(嗯哼,又要吐槽價格了吧),請記住這全部都是SSD硬盤。歸功于存儲器良好的表現,我們數據庫的平均寫入時間是0毫秒,甚至超出我們能度量的精度了。算上內存中的數據以及兩級緩存,Stack Overflow中實際的數據庫讀寫比例是40:60。你沒看錯,60%是寫操作(點此了解讀寫比)。此外,每個Web服務器都有兩塊320GB SSD硬盤組成的RAID1。ElasticSearch在每個區塊大約需要300GB的容量,由于我們會非常頻繁的寫入或重建索引,SSD硬盤在這里是更好的選擇。
值得注意的是我們擁有一個SAN(存儲區域網絡)連接到核心網絡,那就是 Equal Logic PS6110X,它有24個可熱交換的10K SAS磁盤和2個10Gb的控制器。這個設備僅僅被VM服務器用作共享儲存空間以保證虛擬機高度的可用性,但并不實際支撐網站的運行。換句話說,如果SAN掛掉了,在一段時間內網站甚至無法察覺(只有虛擬機中的域名控制器能感知到)。
整合到一起
這所有的設備在一起是為了什么?性能。我們需要很高的性能,這是一個對我們來說很重要的特性。所有站點的首頁都是問題頁面,我們內部把它親切地稱作Question/Show(路由的名字)。在11月12日,這個頁面平均渲染時間是28毫秒,而我們的要求是至多50ms。為了使用戶獲得更好的體驗,我們盡一切可能縮短頁面加載的時間,哪怕只有一毫秒。在和性能有關的問題上,我們所有的開發人員都是“錙銖必較”的,這也有助于我們的網站保持快速響應。以下是一些Stack Overflow上熱門頁面的平均渲染時間,數據還是來自于前面統計的那24小時:
Question/Show: 28 ms (2970萬次點擊)
User Profiles: 39 ms (170萬次點擊)
Question List: 78 ms (110萬次點擊)
Home page: 65 ms (100萬次點擊) (這對我們來說已經很慢了,Kevin Montrose正在著手修復這個問題)
憑借對每一次請求的時間線的記錄,我們能夠準確觀察到頁面加載的過程。我們需要這樣的數據,否則難道靠腦補來做決定嗎?有數據在手,我們就可以這樣監控性能: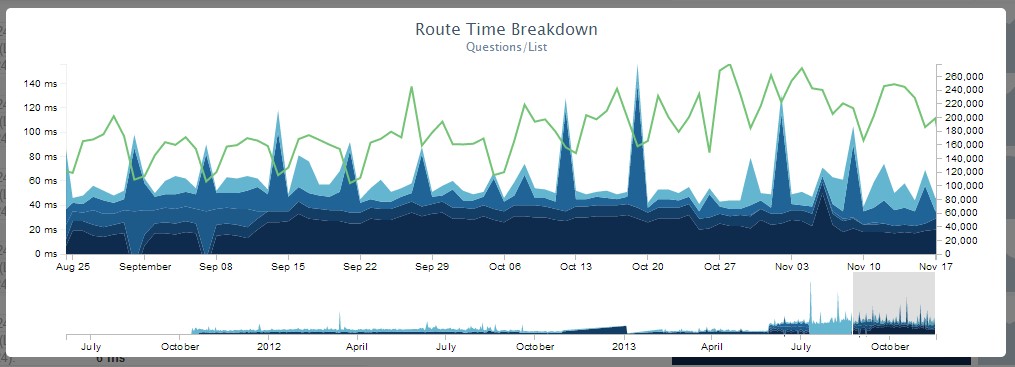
如果你對某個特定頁面的數據感興趣,我也很樂意發布出來。但這里我重點關注渲染時間,因為它表示我們的服務器需要多久來生成一個網頁。網絡傳輸速度是一個完全不同的話題了(盡管不得不承認它也有很大的關系),不過將來我會講到的。
增長空間
非常值得一提的是我們這些服務器運行時的使用率都非常低。比如Web服務器的CPU平均使用率為5-15%,內存只使用了15.5GB,網絡流量只有20-40Mb/s;而數據庫服務器CPU平均使用率為5-10%,使用了365GB內存,以及100-200Mb/s的網絡。這使我們能做到幾件重要的事情:在網站規模增大時不至于需要馬上升級設備;當出現問題時(錯誤的查詢、代碼以及攻擊等等,無論是什么樣的問題),我們能保持網站始終不掛;在必要的時候降低功耗。這里有個我們Web層的監控項目: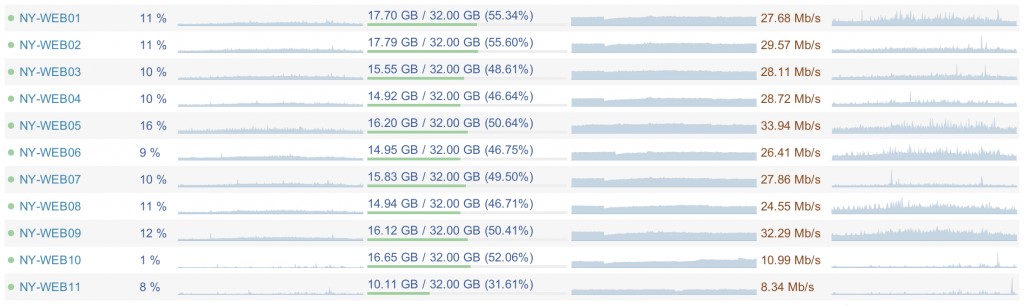
利用率如此之低的主要原因是高效的代碼。盡管本文的主題并不是這個,但是高效的代碼對挖掘服務器的性能也有著決定性的作用。做一件非必要的事情所損失的,居然比無所作為還要多——把這引申到代碼中就是說,你需要把它們改進得更高效了。這些損失或者消耗可以是能源、硬件(你需要更多更快的服務器)、開發人員理解代碼更困難(平心而論,這個有兩面性,高效的代碼并不一定那么簡單),以及緩慢的頁面渲染——可能導致用戶更少地瀏覽網站其他頁面甚至再也不訪問你的網站了。低效率代碼帶來的損失可能比你想象的大很多。
到此,關于“有哪些支撐StackOverflow運營的網站硬件配置”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





