溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“用分表存儲提高性能的方法有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“用分表存儲提高性能的方法有哪些”吧!
首先,童家旺介紹了他認為的什么是優化:第一、做任何事情最快的方法就是什么也不做。

▲支付寶資深數據庫架構師童家旺
第二、不訪問不必要的數據:使用B*Tree/hash等方法定位必要的數據。使用column Store或分表的方式將數據分開存儲。使用Bloom filter算法排除空值查詢。
第三、合理的利用硬件來提升訪問效率:使用緩存消除對數據的重復訪問。使用批量處理來減少磁盤的Seek操作。使用批量處理來減少網絡的Round Trip。使用SSD來提升磁盤訪問效率。
響應時間和吞吐量之間的關系
1、性能。衡量完成特定任務的速度或效率。
2、響應時間。衡量系統與用戶交互式多久能夠發出響應。
3、吞吐量。衡量系統在單位時間里可以完成的任務量。
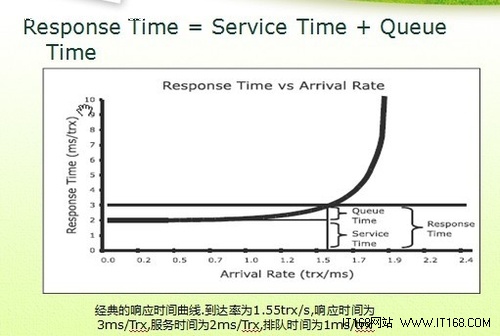
▲反應時間
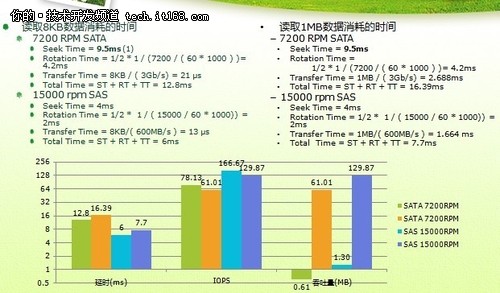
▲傳統磁盤的訪問特性
B*Tree優化數據訪問介紹
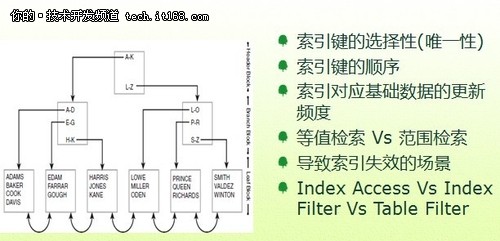
▲B*Tree優化數據訪問
B*Tree優化數據訪問模擬場景

▲B*Tree優化數據訪問模擬場景
童家旺通過阿里巴巴的真實應用場景介紹了如何用分表存儲來提高性能。
一、場景介紹:
1、表VeryBigTable含有30個列
2、表的記錄數為50,000,000條
3、平均每個用戶為300條左右
4、其中有2個列屬于詳細描述字段,平均長度為2k
5、其它的列的總長度平均為250個字節
6、此表上的查詢有兩種模式
7、列出表中的主要信息(每次20條,不包含詳細信息,90%的查詢)
8、查看記錄的詳細信息(10%的查詢)
9、保存與Oracle數據庫,默認block_size(8k)
二、要求:
1、對此業務進行優化
2、分析數據,說服開發部門實施此優化
三、性能分析
1、每塊記錄數
8192 * 0.80(1) / 250 = 25.5 (主表)
8192 * 0.80 / 2000 = 3.27(詳情表)
8192 * 0.80 / ( 2000 + 250 ) = 2.91
2、訪問的邏輯IO(內存塊訪問)
List的查詢代價
改進后=( 300/25.5 ) * y + 4 + x = 4 + x + 11.8y = 4(2) + 7(3) + 11.8 * 1.5(4) = 28.7
改進前=( 300/2.91 ) * y + 4 + x = 4 + x + 103.y = 4 + 7 + 103 * 1.5 = 165.5
3、訪問涉及到的物理讀(磁盤塊訪問)
List的查詢代價(邏輯IO * ( 1 – 命中率 ))
改進后=28.7 * ( 1 – 0.85(5)) = 4.305
改進前=165.5 * ( 1 – 0.85 ) = 24.825
4、訪問時間(ms)
改進前=邏輯IO時間+物理IO時間= 28.7 * 0.01(6) + 4.305 * 7(7) = 30.422ms
改進后=邏輯IO時間+物理IO時間= 165.5 * 0.01 + 24.825 * 7 = 175.43ms
到此,相信大家對“用分表存儲提高性能的方法有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





