溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python爬蟲中Xpath指的是什么?這個問題可能是我們日常學習或工作經常見到的。希望通過這個問題能讓你收獲頗深。下面是小編給大家帶來的參考內容,讓我們一起來看看吧!
xpath簡介
前面介紹了這么多種解析網頁的方式,今天再來介紹一種xpath,
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言。
它可以確定元素在XML中的位置,同樣我們也可以用它來獲取dom節點在html中的位置,就可以便利我們爬取數據
這是今天大概內容的簡介
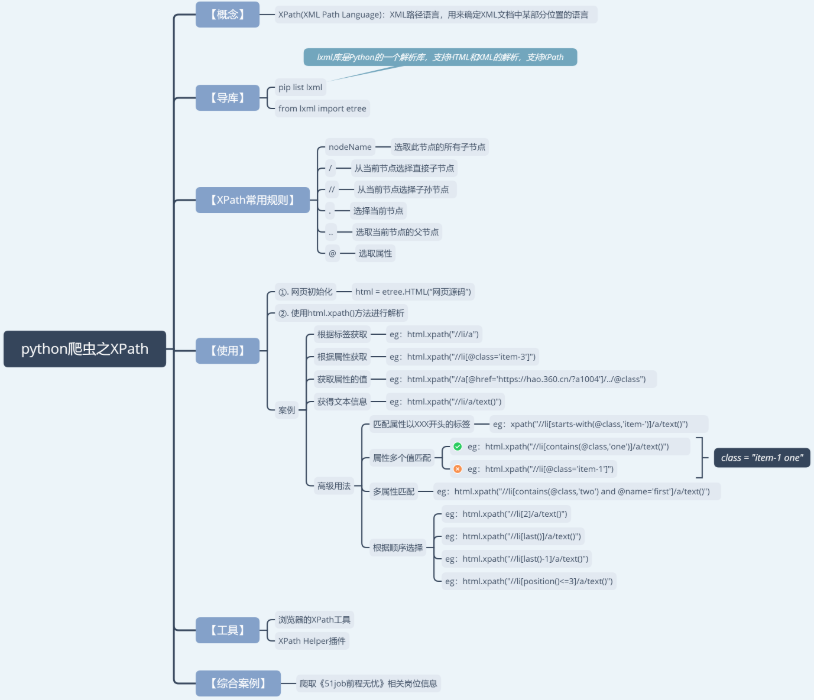
我在這里也就不詳細介紹XPath的語法了,介紹一些我們夠用的就行,想了解自己去看API了:https://www.w3school.com.cn/xpath/index.asp
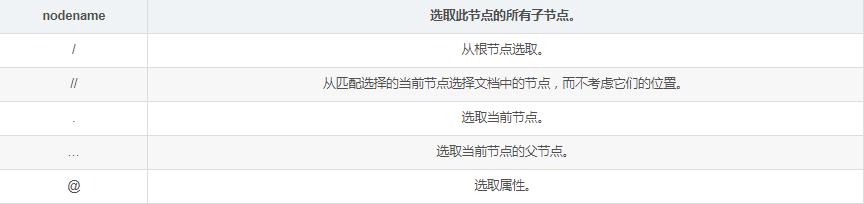
至于語法當然可以不需要我們自己手動寫,我們可以利用瀏覽器的工具,就哪CSND來舉例子,我要獲取左側導航‘程序人生’這個標簽的xpath路徑。
首先要利用瀏覽器的元素選擇器,找到它的html位置
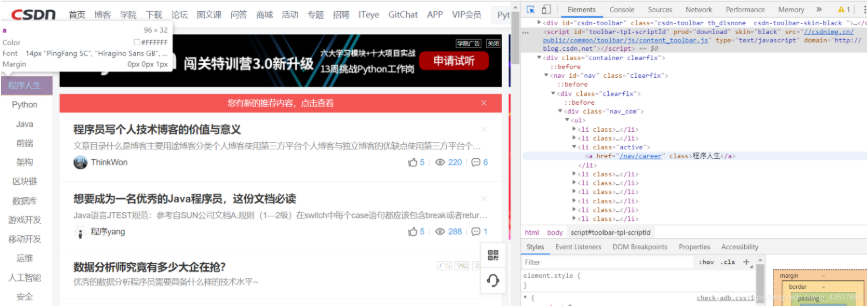
然后我們選擇我們要的元素右擊copy XPath
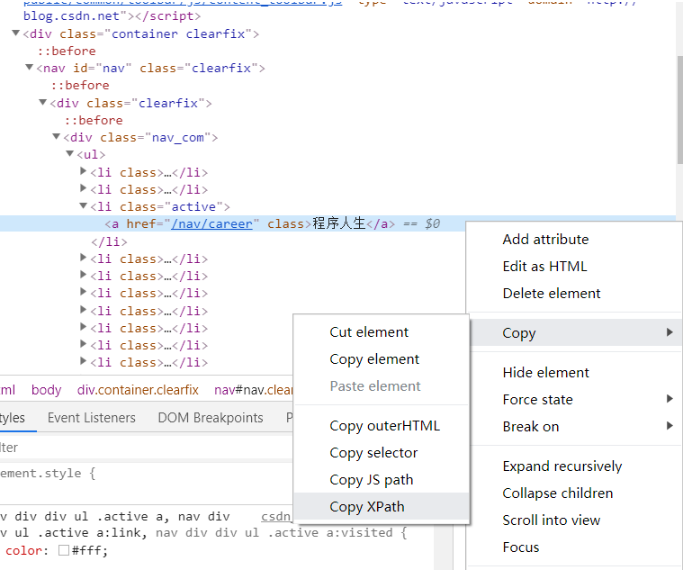
然后我們粘貼下來://*[@id=“nav”]/div/div/ul/li[3]
這就是程序人生的XPath路徑,然后我們就能根據這個來爬取它的這一整塊的信息了,后面我的案例就是這樣做的。
爬取51job招聘信息
案例就直接上代碼了,思路都大同小異,分析信息的頁面、頁碼、元素等等,然后寫代碼。
"""
爬取 51job 相關職位信息,并保存成cvs文件格式
"""
import requests
from lxml import etree
import csv
# csv后綴的格式就是excel文件打開的格式,我們等于是直接存入了excel中
import time
headers = {
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}
f = open("java職位.cvs","w",newline="")
writer = csv.writer(f)
writer.writerow(['編號', '職位名稱', '公司名稱', '薪資', '地址', '發布時間'])
i = 1;
for page in range(1,159):
requests_get = requests.get(
f"https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,{page}.html?lang=c&stype=&postchannel
=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius
=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=",
headers=headers)
requests_get.encoding="gbk"
if requests_get.status_code == 200:
html = etree.HTML(requests_get.text)
els = html.xpath("//div[@class='el']")[4:]
for el in els:
jobname = str(el.xpath("p[contains(@class,'t1')]/span/a/@title")).strip("[']")
jobcom = str(el.xpath("span[@class='t2']/a/@titlr")).strip("[']")
jobaddress = str(el.xpath("span[@class='t3']/text()")).strip("[']")
jobsalary = str(el.xpath("span[@class='t4']/text()")).strip("[']")
jobdate = str(el.xpath("span[@class='t5']/text()")).strip("[']")
writer.writerow([i, jobname, jobcom, jobaddress, jobsalary, jobdate])
i += 1
print(f"第{page}頁獲取完畢")最后存入excel中的樣子。

感謝各位的閱讀!看完上述內容,你們對Python爬蟲中Xpath指的是什么大概了解了嗎?希望文章內容對大家有所幫助。如果想了解更多相關文章內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





