溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中XML和XPATH指的是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
XML和XPATH
用正則處理HTML文檔很麻煩,我們可以先將HTML文件轉換成XML文檔,然后用XPath查找HTML節點或元素。
XML 指可擴展標記語言(EXtensible Markup Language)
XML 是一種標記語言,很類似 HTML
XML 的設計宗旨是傳輸數據,而非顯示數據
XML 的標簽需要我們自行定義。
XML 被設計為具有自我描述性。
XML 是 W3C 的推薦標準
XML和HTML區別

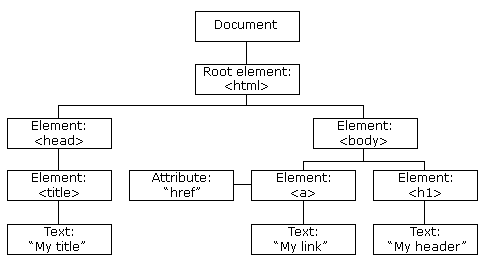
HTML DOM 模型示例
HTML DOM 定義了訪問和操作 HTML 文檔的標準方法,以樹結構方式表達 HTML 文檔。
XPATH
XPath (XML Path Language) 是一門在XML文檔中查找信息的語言,可用來在 XML 文檔中對元素和屬性進行遍歷。
chrome插件XPATH HelPer
Firefox插件XPATH Checker
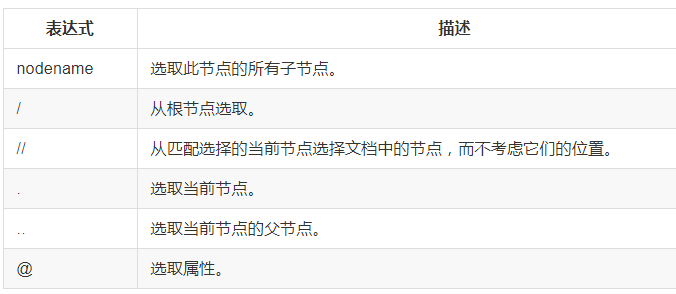
XPATH語法
最常用的路徑表達式:

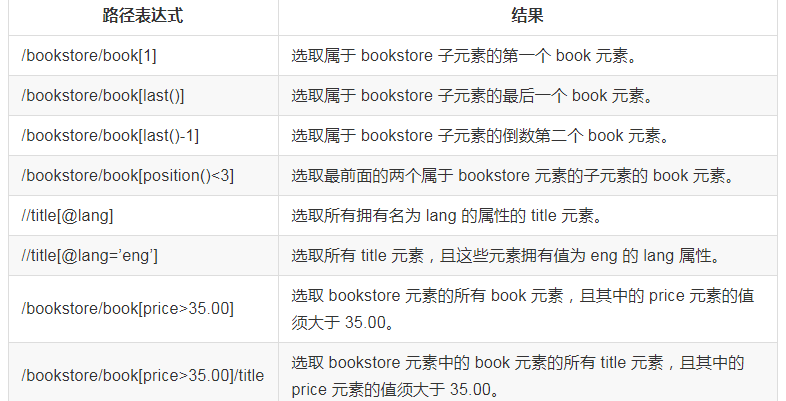
謂語
謂語用來查找某個特定的節點或者包含某個指定的值的節點,被嵌在方括號中。
在下面的表格中,我們列出了帶有謂語的一些路徑表達式,以及表達式的結果:
選取位置節點
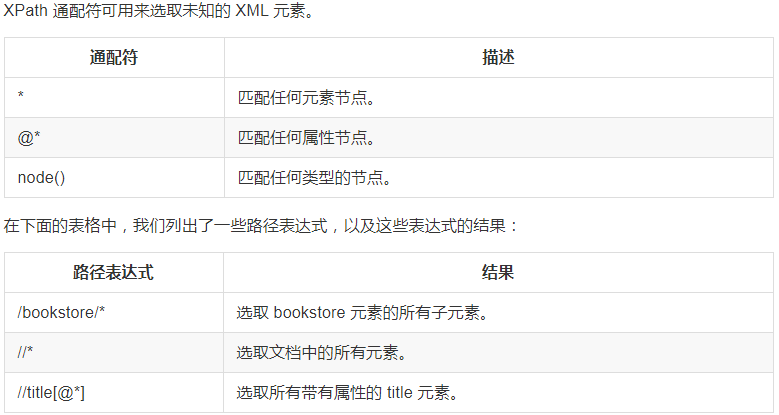
選取若干路徑
LXML庫
安裝:pip install lxml
lxml 是 一個HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 數據。
lxml和正則一樣,也是用 C 實現的,是一款高性能的 Python HTML/XML 解析器,可以利用XPath語法,來快速的定位特定元素以及節點信息。
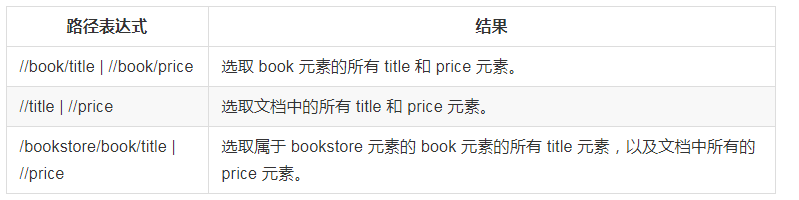
簡單使用方法
#!/usr/bin/env python # -*- coding:utf-8 -*- from lxml import etree text = ''' <div> <li>11</li> <li>22</li> <li>33</li> <li>44</li> </div> ''' #利用etree.HTML,將字符串解析為HTML文檔 html = etree.HTML(text) # 按字符串序列化HTML文檔 result = etree.tostring(html) print(result)
結果:
爬取美女吧圖片
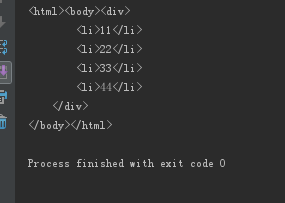
1.先找到每個帖子列表的url集合
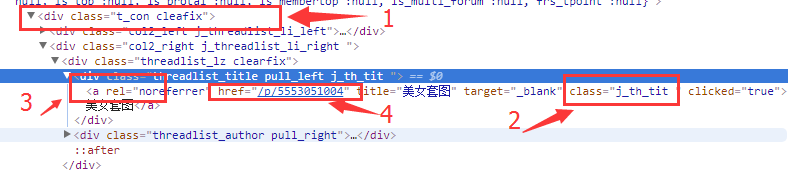

2.再找到每個帖子里面的每個圖片的的完整url鏈接


3.要用到 lxml 模塊去解析html
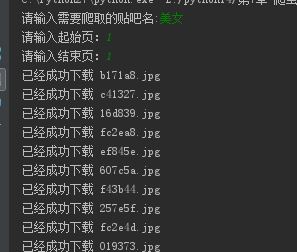
#!/usr/bin/env python # -*- coding:utf-8 -*- import urllib import urllib2 from lxml import etree def loadPage(url): """ 作用:根據url發送請求,獲取服務器響應文件 url: 需要爬取的url地址 """ request = urllib2.Request(url) html = urllib2.urlopen(request).read() # 解析HTML文檔為HTML DOM模型 content = etree.HTML(html) # 返回所有匹配成功的列表集合 link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href') for link in link_list: fulllink = "http://tieba.baidu.com" + link # 組合為每個帖子的鏈接 #print link loadImage(fulllink) # 取出每個帖子里的每個圖片連接 def loadImage(link): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'} request = urllib2.Request(link, headers = headers) html = urllib2.urlopen(request).read() # 解析 content = etree.HTML(html) # 取出帖子里每層層主發送的圖片連接集合 link_list = content.xpath('//img[@class="BDE_Image"]/@src') # 取出每個圖片的連接 for link in link_list: # print link writeImage(link) def writeImage(link): """ 作用:將html內容寫入到本地 link:圖片連接 """ #print "正在保存 " + filename headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 文件寫入 request = urllib2.Request(link, headers = headers) # 圖片原始數據 image = urllib2.urlopen(request).read() # 取出連接后10位做為文件名 filename = link[-10:] # 寫入到本地磁盤文件內 with open(filename, "wb") as f: f.write(image) print "已經成功下載 "+ filename def tiebaSpider(url, beginPage, endPage): """ 作用:貼吧爬蟲調度器,負責組合處理每個頁面的url url : 貼吧url的前部分 beginPage : 起始頁 endPage : 結束頁 """ for page in range(beginPage, endPage + 1): pn = (page - 1) * 50 #filename = "第" + str(page) + "頁.html" fullurl = url + "&pn=" + str(pn) #print fullurl loadPage(fullurl) #print html print "謝謝使用" if __name__ == "__main__": kw = raw_input("請輸入需要爬取的貼吧名:") beginPage = int(raw_input("請輸入起始頁:")) endPage = int(raw_input("請輸入結束頁:")) url = "http://tieba.baidu.com/f?" key = urllib.urlencode({"kw": kw}) fullurl = url + key tiebaSpider(fullurl, beginPage, endPage)
4.爬取的圖片全部保存到了電腦里面
關于Python中XML和XPATH指的是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





