溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python爬蟲技術指的是什么?這個問題可能是我們日常學習或工作經常見到的。希望通過這個問題能讓你收獲頗深。下面是小編給大家帶來的參考內容,讓我們一起來看看吧!
相信很多小伙伴剛接觸網絡爬蟲這個詞語,腦海中一點概念也沒有,其實從字面上我們稍微能夠揣摩到一點,這需要去“接觸”內容,由此,那就可以展開本章話題。
首先將網絡爬蟲技術分解成四個部分:
1、獲取網頁數據
2、解析網頁數據
3、存儲網頁數據
4、分析網頁數據
步驟一、獲取網頁數據
在python程序里面,可以通過獲取網頁中的源代碼實現,進而獲得網頁中的數據。
查看網址的源代碼查看方法:
使用google瀏覽器,右鍵選擇檢查,查看需要爬取的網址源代碼。
具體如下:
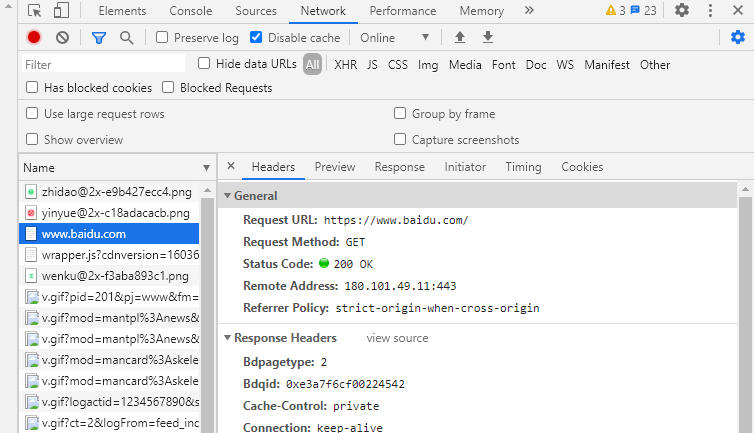
根據下圖可得知,在Network選項卡里面,點擊第三個條目,也就是http://www.baidu.com,看到源代碼。
在本圖中,第一部分是General,包括了網址的基本信息,比如狀態 200等,第二部分是Response Headers,包括了請求的應答信息,還有body部分,比如Set-Cookie,Server等。第三部分是Request headers,包含了服務器使用的附加信息,比如Cookie,User-Agent等內容。
上面的網頁源代碼,在python語言中,我們只需要使用urllib、requests等庫實現即可,具體如下。這里特別說明一些,requests比urllib更加方便、快捷。一旦學會requests庫,肯定會愛不釋手。
import urllib.request
import socket
from urllib import error
try:
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.read().decode('utf-8'))
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')步驟二、解析網頁數據
上述我們獲得了網頁的源代碼,也就是數據。然后就是解析里面的數據,為我們的分析使用。常見的方法有很多,比如正則表達式、xpath解析等。
在Python語言中,我們經常使用Beautiful Soup、pyquery、lxml等庫,可以高效的從中獲取網頁信息,如節點的屬性、文本值等。
Beautiful Soup庫是解析、遍歷、維護“標簽樹”的功能庫,對應一個HTML/XML文檔的全部內容。安裝方法非常簡單,如下:
#安裝方法 pips install beautifulsoup4 #驗證方法 from bs4 import BeautifulSoup
步驟三、存儲網頁數據
解析完數據以后,就可以保存起來。如果不是很多,可以考慮保存在txt 文本、csv文本或者json文本等,如果爬取的數據條數較多,我們可以考慮將其存儲到數據庫中。因此,我們需要學會 MySql、MongoDB、SqlLite的用法。更加深入的,可以學習數據庫的查詢優化。
JSON(JavaScript Object Notation) 是一種輕量級的數據交換格式。它基于ECMAScript的一個子集。 JSON采用完全獨立于語言的文本格式,但是也使用了類似于C語言家族的習慣(包括C、C++、Java、JavaScript、Perl、Python等)。這些特性使JSON成為理想的數據交換語言。易于人閱讀和編寫,同時也易于機器解析和生成(一般用于提升網絡傳輸速率)。
具體使用方法:
with open('douban_movie_250.csv','a',encoding='utf-8') as f: f.write(json.dumps(content,ensure_ascii=False)+'\n')步驟四、分析網頁數據
爬蟲的目的是分析網頁數據,進的得到我們想要的結論。在 python數據分析中,我們可以使用使用第三步保存的數據直接分析,主要使用的庫如下:NumPy、Pandas、 Matplotlib 三個庫。
NumPy :它是高性能科學計算和數據分析的基礎包。 Pandas : 基于 NumPy 的一種工具,該工具是為了解決數據分析任務而創建的。它可以算得上作弊工具。 Matplotlib:Python中最著名的繪圖系統Python中最著名的繪圖系統。它可以制作出散點圖,折線圖,條形圖,直方圖,餅狀圖,箱形圖散點圖,折線圖,條形圖,直方圖,餅狀圖,箱形圖等。
感謝各位的閱讀!看完上述內容,你們對python爬蟲技術指的是什么大概了解了嗎?希望文章內容對大家有所幫助。如果想了解更多相關文章內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





