溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么在Node中使用Puppeteer實現一個爬蟲,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
架構圖
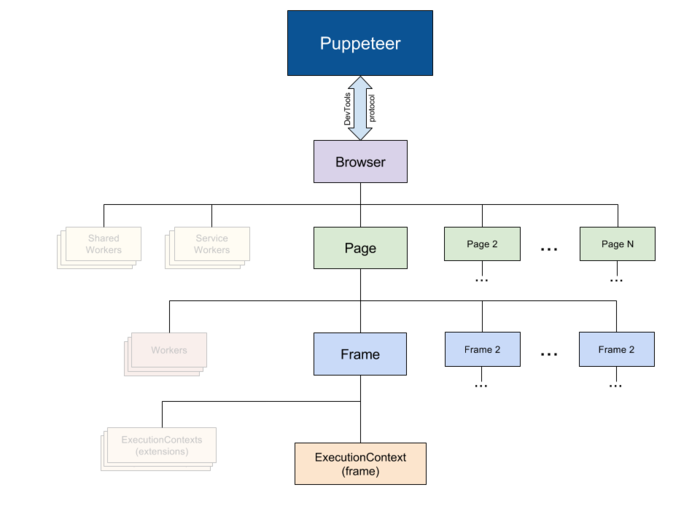
Puppeteer架構圖
Puppeteer 通過 devTools 與 browser 通信
Browser 一個可以擁有多個頁面的瀏覽器(chroium)實例
Page 至少含有一個 Frame 的頁面
Frame 至少還有一個用于執行 javascript 的執行環境,也可以拓展多個執行環境
前言
最近想要入手一臺臺式機,筆記本的i5在打開網頁和vsc的時候有明顯卡頓的情況,因此打算配1臺 i7 + GTX1070TI or GTX1080TI的電腦,直接在淘寶上搜需要翻頁太多,并且圖片太多,腦容量接受不了,因此想爬一些數據,利用圖形化分析一下最近價格的走勢。因此寫了一個用Puppeteer寫了一個爬蟲爬去相關數據。
什么是Puppeteer?
Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
簡而言之,這貨是一個提供高級API的node庫,能夠通過devtool控制headless模式的chrome或者chromium,它可以在headless模式下模擬任何的人為操作。
和cheerio的區別
cherrico本質上只是一個使用類似jquery的語法操作HTML文檔的庫,使用cherrico爬取數據,只是請求到靜態的HTML文檔,如果網頁內部的數據是通過ajax動態獲取的,那么便爬去不到的相應的數據。而Puppeteer能夠模擬一個瀏覽器的運行環境,能夠請求網站信息,并運行網站內部的邏輯。然后再通過WS協議動態的獲取頁面內部的數據,并能夠進行任何模擬的操作(點擊、滑動、hover等),并且支持跳轉頁面,多頁面管理。甚至能注入node上的腳本到瀏覽器內部環境運行,總之,你能對一個網頁做的操作它都能做,你不能做的它也能做。
開始
本文不是一個手把手教程,因此需要你有基本的Puppeteer API常識,如果不懂,請先看看官方介紹
Puppeteer官方站點
PuppeteerAPI
首先我們觀察要爬去的網站信息 GTX1080
這是我們要爬取的淘寶網頁,只有中間的商品項目是我們需要爬取的內容,仔細分析它的結構,相信一個前端都有這樣的能力。
我使用的Typescript,能夠獲得完整的Puppetter及相關庫的API提示,如果你不會TS,只需要將相關的代碼換成ES的語法就好了
// 引入一些需要用到的庫以及一些聲明 import * as puppeteer from 'puppeteer' // 引入Puppeteer import mongo from '../lib/mongoDb' // 需要用到的 mongodb庫,用來存取爬取的數據 import chalk from 'chalk' // 一個美化 console 輸出的庫 const log = console.log // 縮寫 console.log const TOTAL_PAGE = 50 // 定義需要爬取的網頁數量,對應頁面下部的跳轉鏈接 // 定義要爬去的數據結構 interface IWriteData { link: string // 爬取到的商品詳情鏈接 picture: string // 爬取到的圖片鏈接 price: number // 價格,number類型,需要從爬取下來的數據進行轉型 title: string // 爬取到的商品標題 } // 格式化的進度輸出 用來顯示當前爬取的進度 function formatProgress (current: number): string { let percent = (current / TOTAL_PAGE) * 100 let done = ~~(current / TOTAL_PAGE * 40) let left = 40 - done let str = `當前進度:[${''.padStart(done, '=')}${''.padStart(left, '-')}] ${percent}%` return str }
接下來我們開始進入到爬蟲的主要邏輯
// 因為我們需要用到大量的 await 語句,因此在外層包裹一個 async function
async function main() {
// Do something
}
main()// 進入代碼的主邏輯
async function main() {
// 首先通過Puppeteer啟動一個瀏覽器環境
const browser = await puppeteer.launch()
log(chalk.green('服務正常啟動'))
// 使用 try catch 捕獲異步中的錯誤進行統一的錯誤處理
try {
// 打開一個新的頁面
const page = await browser.newPage()
// 監聽頁面內部的console消息
page.on('console', msg => {
if (typeof msg === 'object') {
console.dir(msg)
} else {
log(chalk.blue(msg))
}
})
// 打開我們剛剛看見的淘寶頁面
await page.goto('https://s.taobao.com/search?q=gtx1080&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180416&ie=utf8')
log(chalk.yellow('頁面初次加載完畢'))
// 使用一個 for await 循環,不能一個時間打開多個網絡請求,這樣容易因為內存過大而掛掉
for (let i = 1; i <= TOTAL_PAGE; i++) {
// 找到分頁的輸入框以及跳轉按鈕
const pageInput = await page.$(`.J_Input[type='number']`)
const submit = await page.$('.J_Submit')
// 模擬輸入要跳轉的頁數
await pageInput.type('' + i)
// 模擬點擊跳轉
await submit.click()
// 等待頁面加載完畢,這里設置的是固定的時間間隔,之前使用過page.waitForNavigation(),但是因為等待的時間過久導致報錯(Puppeteer默認的請求超時是30s,可以修改),因為這個頁面總有一些不需要的資源要加載,而我的網絡最近日了狗,會導致超時,因此我設定等待2.5s就夠了
await page.waitFor(2500)
// 清除當前的控制臺信息
console.clear()
// 打印當前的爬取進度
log(chalk.yellow(formatProgress(i)))
log(chalk.yellow('頁面數據加載完畢'))
// 處理數據,這個函數的實現在下面
await handleData()
// 一個頁面爬取完畢以后稍微歇歇,不然太快淘寶會把你當成機器人彈出驗證碼(雖然我們本來就是機器人)
await page.waitFor(2500)
}
// 所有的數據爬取完畢后關閉瀏覽器
await browser.close()
log(chalk.green('服務正常結束'))
// 這是一個在內部聲明的函數,之所以在內部聲明而不是外部,是因為在內部可以獲取相關的上下文信息,如果在外部聲明我還要傳入 page 這個對象
async function handleData() {
// 現在我們進入瀏覽器內部搞些事情,通過page.evaluate方法,該方法的參數是一個函數,這個函數將會在頁面內部運行,這個函數的返回的數據將會以Promise的形式返回到外部
const list = await page.evaluate(() => {
// 先聲明一個用于存儲爬取數據的數組
const writeDataList: IWriteData[] = []
// 獲取到所有的商品元素
let itemList = document.querySelectorAll('.item.J_MouserOnverReq')
// 遍歷每一個元素,整理需要爬取的數據
for (let item of itemList) {
// 首先聲明一個爬取的數據結構
let writeData: IWriteData = {
picture: undefined,
link: undefined,
title: undefined,
price: undefined
}
// 找到商品圖片的地址
let img = item.querySelector('img')
writeData.picture = img.src
// 找到商品的鏈接
let link: HTMLAnchorElement = item.querySelector('.pic-link.J_ClickStat.J_ItemPicA')
writeData.link = link.href
// 找到商品的價格,默認是string類型 通過~~轉換為整數number類型
let price = item.querySelector('strong')
writeData.price = ~~price.innerText
// 找到商品的標題,淘寶的商品標題有高亮效果,里面有很多的span標簽,不過一樣可以通過innerText獲取文本信息
let title: HTMLAnchorElement = item.querySelector('.title>a')
writeData.title = title.innerText
// 將這個標簽頁的數據push進剛才聲明的結果數組
writeDataList.push(writeData)
}
// 當前頁面所有的返回給外部環境
return writeDataList
})
// 得到數據以后寫入到mongodb
const result = await mongo.insertMany('GTX1080', list)
log(chalk.yellow('寫入數據庫完畢'))
}
} catch (error) {
// 出現任何錯誤,打印錯誤消息并且關閉瀏覽器
console.log(error)
log(chalk.red('服務意外終止'))
await browser.close()
} finally {
// 最后要退出進程
process.exit(0)
}
}思考
1、為什么使用Typescript?
因為Typescript就是好用啊,我也背不住Puppeteer的全部API,也不想每一個都查,所以使用TS就能智能提醒了,也能避免因為拼寫導致的低級錯誤。基本上用了TS以后,敲代碼都能一遍過
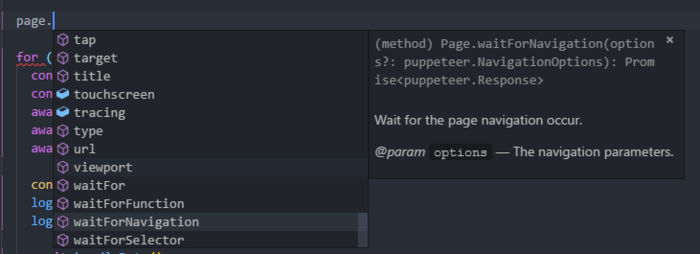
puppeteer.png
2、爬蟲的性能問題?
因為Puppeteer會啟動一個瀏覽器,執行內部的邏輯,所以占用的內存是蠻多的,看了看控制臺,這個node進程大概占用300MB左右的內存。
我的頁面是一個個爬的,如果想更快的爬取可以啟動多個進程,注意,V8是單線程的,所以在一個進程內部打開多個頁面是沒有意義的,需要配置不同的參數打開不同的node進程,當然也可以通過node的cluster(集群)實現,本質都是一樣的
我在爬取的過程中也設置了不同的等待時間,一方面是為了等待網頁的加載,一方面避免淘寶識別到我是爬蟲彈驗證碼
3、Puppeteer的其它功能
這里僅僅利用了Puppeteer的一些基本特性,實際上Puppeteer還有更多的功能。比如引入node上的處理函數在瀏覽器內部執行,將當前頁面保存為pdf或者png圖片。并且還可以通過const browser = await puppeteer.launch({ headless: false })啟動一個帶界面效果的瀏覽器,你可以看見你的爬蟲是如何運作的。此外一些需要登錄的網站,如果你不想識別驗證碼委托第三方進行處理,你也可以關閉headless,然后在程序中設置等待時間,手動完成一些驗證從而達到登錄的目的。
當然google制作了一個這么牛逼的庫可不只是用來做爬蟲爬取數據的,這個庫也用作于一些自動化的性能分析、界面測試、前端網站監控等
關于怎么在Node中使用Puppeteer實現一個爬蟲就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





