溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Spark集群執行任務失敗如何處理”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
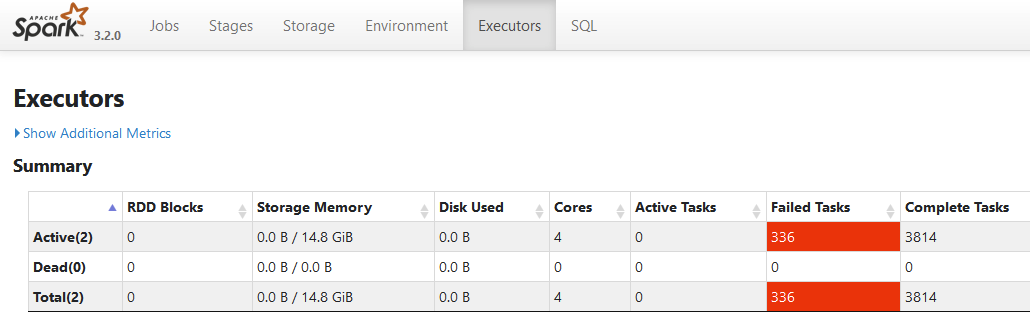
大量執行失敗的 Task,最終任務也是失敗的
在 Spark Master 管理界面上看到任務的 Driver 地址不是真實 IP 地址,而是一個叫做“host.containers.internal”的主機名;
Spark 的 worker 節點上能觀察到在不停的創建 Java 進程,然后進程瞬間就結束了;
進入 worker 節點的日志目錄查看日志內容,發現異常信息為連接 “host.containers.internal” 這個地址失敗。
所以顯然當前出現的問題跟“host.containers.internal”有關系。
背景說明:我們的 Spark 集群是運行在 podman 容器里的,而且是在非 root 用戶下運行。
經過在互聯網上搜索,發現這個主機名是容器分配給內部進程用來連接容器所在主機自身的。再進一步查看 podman 參考文檔,按照里面的說法,僅當容器運行網絡模式為 slirp4netns,即帶上參數 "--network=slirp4netns" 時,才會有 host.containers.internal 這個主機名。
但我運行容器時帶的參數是 "--network=host" 啊。
再仔細看文檔才知道,slirp4netns 模式是非 root 運行容器的默認模式。按照我遇到的實際情況,難道我給的 "--network=host" 參數并沒有起作用?但是用 podman inspect xxx | grep NetworkMode 命令查看容器得到的結果是:
"NetworkMode": "host"
不懂,先把這個放到一邊,那么如何訪問 host.containers.internal 這個主機呢,有兩種方式:
參數改為 "--network=slirp4netns:allow_host_loopback=true"
修改 /usr/share/containers/containers.conf,修改或添加配置 network_cmd_options 的值為 ["allow_host_loopback=true"]
在不修改 --network 參數的前提下,我用第二種方法試試。
修改配置文件然后重啟各個 worker 容器,故障消失,Spark 任務能夠順利執行完成。但還需要觀察一段時間。
“Spark集群執行任務失敗如何處理”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。