溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Node中的進程和線程怎么實現的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Node中的進程和線程怎么實現文章都會有所收獲,下面我們一起來看看吧。
進程(Process),進程是計算機中的程序關于某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎,進程是線程的容器。
線程(Thread),線程是操作系統能夠進行運算調度的最小單位,被包含在進程之中,是進程中的實際運作單位。
以上描述比較硬,看完可能也沒看懂,還不利于理解記憶。那么我們舉個簡單的例子:
假設你是某個快遞站點的一名小哥,起初這個站點負責的區域住戶不多,收取件都是你一個人。給張三家送完件,再去李四家取件,事情得一件件做,這叫單線程,所有的工作都得按順序執行。
后來這個區域住戶多了,站點給這個區域分配了多個小哥,還有個小組長,你們可以為更多的住戶服務了,這叫多線程,小組長是主線程,每個小哥都是一個線程。
快遞站點使用的小推車等工具,是站點提供的,小哥們都可以使用,并不僅供某一個人,這叫多線程資源共享。
站點小推車目前只有一個,大家都需要使用,這叫沖突。解決的方法有很多,排隊等待或者等其他小哥用完后的通知,這叫線程同步。
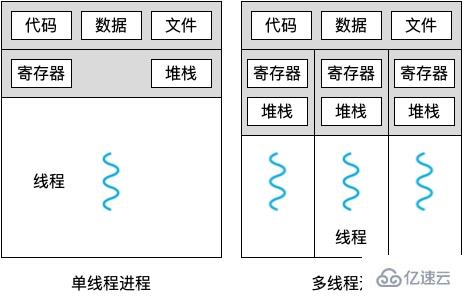
總公司有很多站點,各個站點的運營模式幾乎一模一樣,這叫多進程。總公司叫主進程,各個站點叫子進程。
總公司和站點之間,以及各個站點互相之間,小推車都是相互獨立的,不能混用,這叫進程間不共享資源。各站點間可以通過電話等方式聯系,這叫管道。各站點間還有其他協同手段,便于完成更大的計算任務,這叫進程間同步。
還可以看看阮一峰的 進程與線程的一個簡單解釋。
Node.js 是單線程服務,事件驅動和非阻塞 I/O 模型的語言特性,使得 Node.js 高效和輕量。優勢在于免去了頻繁切換線程和資源沖突;擅長 I/O 密集型操作(底層模塊 libuv 通過多線程調用操作系統提供的異步 I/O 能力進行多任務的執行),但是對于服務端的 Node.js,可能每秒有上百個請求需要處理,當面對 CPU 密集型請求時,因為是單線程模式,難免會造成阻塞。
我們利用 Koa 簡單地搭建一個 Web 服務,用斐波那契數列方法來模擬一下 Node.js 處理 CPU 密集型的計算任務:
斐波那契數列,也稱黃金分割數列,這個數列從第三項開始,每一項都等于前兩項只和:0、1、1、2、3、5、8、13、21、......
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用來測試是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契數列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
執行 node app.js 啟動服務,用 Postman 發送請求,可以看到,計算 38 次耗費了 617ms,換而言之,因為執行了一個 CPU 密集型的計算任務,所以 Node.js 主線程被阻塞了六百多毫秒。如果同時處理更多的請求,或者計算任務更復雜,那么在這些請求之后的所有請求都會被延遲執行。

我們再新建一個 axios.js 用來模擬發送多次請求,此時將 app.js 中的 fibo 計算次數改為 43,用來模擬更復雜的計算任務:
// axios.js
const axios = require('axios')
const start = Date.now()
const fn = (url) => {
axios.get(`http://127.0.0.1:9000/${ url }`).then((res) => {
console.log(res.data, `耗時: ${ Date.now() - start }ms`)
})
}
fn('test')
fn('fibo?num=43')
fn('test')

可以看到,當請求需要執行 CPU 密集型的計算任務時,后續的請求都被阻塞等待,這類請求一多,服務基本就阻塞卡死了。對于這種不足,Node.js 一直在彌補。
master-worker 模式是一種并行模式,核心思想是:系統有兩個及以上的進程或線程協同工作時,master 負責接收和分配并整合任務,worker 負責處理任務。
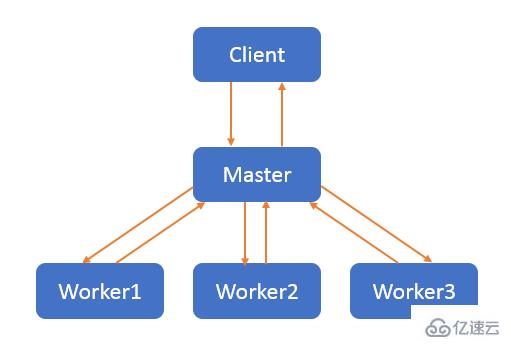
線程是 CPU 調度的一個基本單位,只能同時執行一個線程的任務,同一個線程也只能被一個 CPU 調用。如果使用的是多核 CPU,那么將無法充分利用 CPU 的性能。
多線程帶給我們靈活的編程方式,但是需要學習更多的 Api 知識,在編寫更多代碼的同時也存在著更多的風險,線程的切換和鎖也會增加系統資源的開銷。
worker_threads 工作線程,給 Node.js 提供了真正的多線程能力。
worker_threads 是 Node.js 提供的一種多線程 Api。對于執行 CPU 密集型的計算任務很有用,對 I/O 密集型的操作幫助不大,因為 Node.js 內置的異步 I/O 操作比 worker_threads 更高效。worker_threads 中的 Worker,parentPort 主要用于子線程和主線程的消息交互。
將 app.js 稍微改動下,將 CPU 密集型的計算任務交給子線程計算:
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const { Worker } = require('worker_threads')
const app = new Koa()
// 用來測試是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', async (ctx) => {
const { num = 38 } = ctx.query
ctx.body = await asyncFibo(num)
})
const asyncFibo = (num) => {
return new Promise((resolve, reject) => {
// 創建 worker 線程并傳遞數據
const worker = new Worker('./fibo.js', { workerData: { num } })
// 主線程監聽子線程發送的消息
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`))
})
})
}
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
新增 fibo.js 文件,用來處理復雜計算任務:
const { workerData, parentPort } = require('worker_threads')
const { num } = workerData
const start = Date.now()
// 斐波那契數列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
parentPort.postMessage({
pid: process.pid,
duration: Date.now() - start
})
執行上文的 axios.js,此時將 app.js 中的 fibo 計算次數改為 43,用來模擬更復雜的計算任務:

可以看到,將 CPU 密集型的計算任務交給子線程處理時,主線程不再被阻塞,只需等待子線程處理完成后,主線程接收子線程返回的結果即可,其他請求不再受影響。
上述代碼是演示創建 worker 線程的過程和效果,實際開發中,請使用線程池來代替上述操作,因為頻繁創建線程也會有資源的開銷。
線程是 CPU 調度的一個基本單位,只能同時執行一個線程的任務,同一個線程也只能被一個 CPU 調用。
我們再回味下,本小節開頭提到的線程和 CPU 的描述,此時由于是新的線程,可以在其他 CPU 核心上執行,可以更充分的利用多核 CPU。
Node.js 為了能充分利用 CPU 的多核能力,提供了 cluster 模塊,cluster 可以通過一個父進程管理多個子進程的方式來實現集群的功能。
child_process 子進程,衍生新的 Node.js 進程并使用建立的 IPC 通信通道調用指定的模塊。
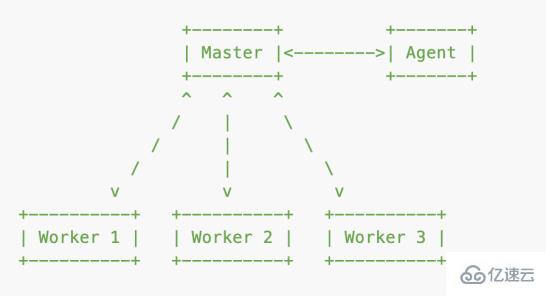
cluster 集群,可以創建共享服務器端口的子進程,工作進程使用 child_process 的 fork 方法衍生。
cluster 底層就是 child_process,master 進程做總控,啟動 1 個 agent 進程和 n 個 worker 進程,agent 進程處理一些公共事務,比如日志等;worker 進程使用建立的 IPC(Inter-Process Communication)通信通道和 master 進程通信,和 master 進程共享服務端口。
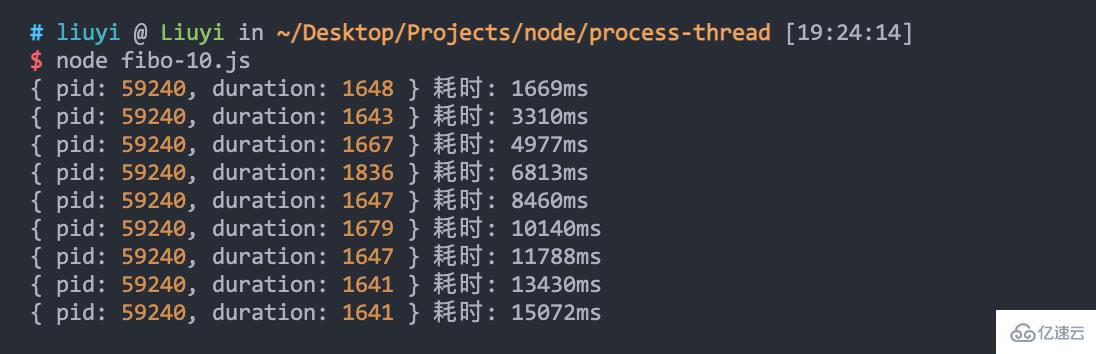
新增 fibo-10.js,模擬發送 10 次請求:
// fibo-10.js
const axios = require('axios')
const url = `http://127.0.0.1:9000/fibo?num=38`
const start = Date.now()
for (let i = 0; i < 10; i++) {
axios.get(url).then((res) => {
console.log(res.data, `耗時: ${ Date.now() - start }ms`)
})
}
可以看到,只使用了一個進程,10 個請求慢慢阻塞,累計耗時 15 秒:
接下來,將 app.js 稍微改動下,引入 cluster 模塊:
// app.js
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
// const numCPUs = 10 // worker 進程的數量一般和 CPU 核心數相同
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用來測試是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契數列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`)
// 衍生 worker 進程
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`)
})
} else {
app.listen(9000)
console.log(`Worker ${process.pid} started`)
}
執行 node app.js 啟動服務,可以看到,cluster 幫我們創建了 1 個 master 進程和 4 個 worker 進程:
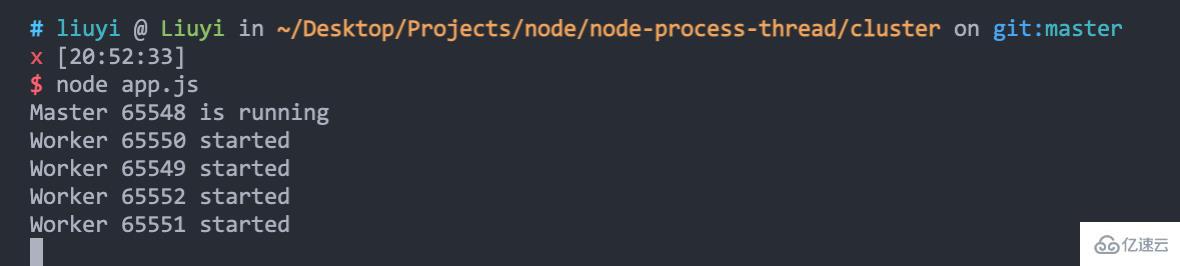
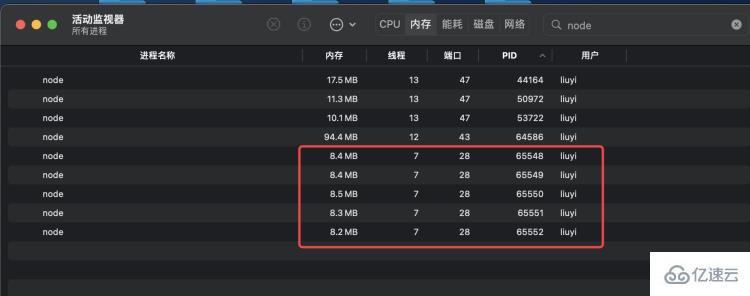
通過 fibo-10.js 模擬發送 10 次請求,可以看到,四個進程處理 10 個請求耗時近 9 秒:
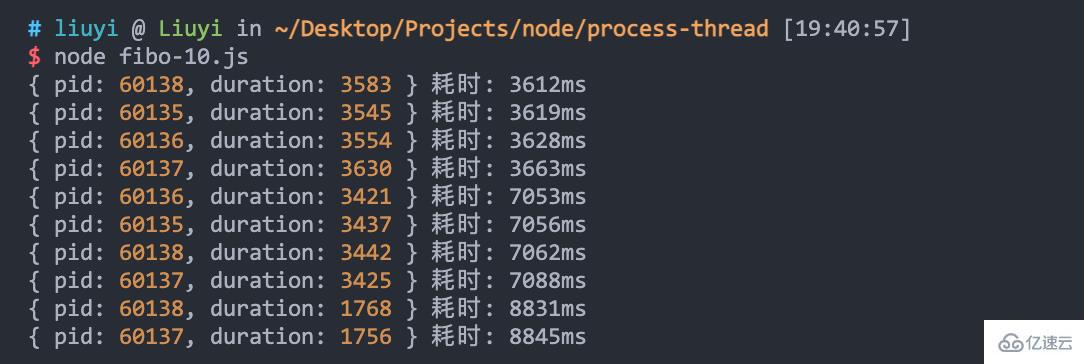
當啟動 10 個 worker 進程時,看看效果:
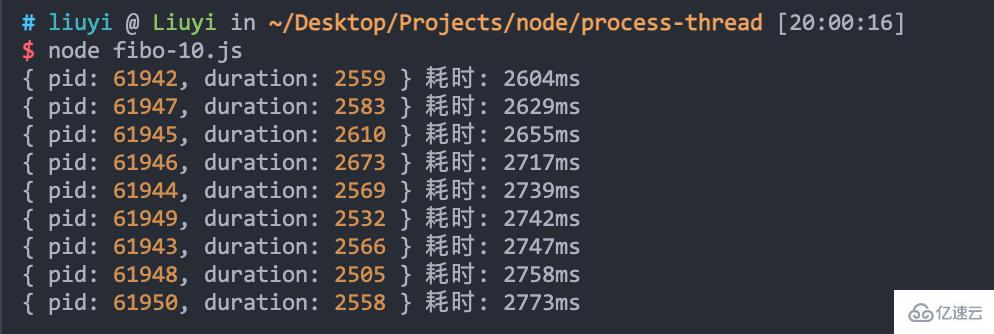
僅需不到 3 秒,不過進程的數量也不是無限的。在日常開發中,worker 進程的數量一般和 CPU 核心數相同。
開啟多進程不全是為了處理高并發,而是為了解決 Node.js 對于多核 CPU 利用率不足的問題。
由父進程通過 fork 方法衍生出來的子進程擁有和父進程一樣的資源,但是各自獨立,互相之間資源不共享。通常根據 CPU 核心數來設置進程數量,因為系統資源是有限的。
關于“Node中的進程和線程怎么實現”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Node中的進程和線程怎么實現”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





