溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“C++如何實現特殊矩陣的壓縮存儲算法”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“C++如何實現特殊矩陣的壓縮存儲算法”文章吧。
什么是特殊矩陣?
C++,一般使用二維數組存儲矩陣數據。
在實際存儲時,會發現矩陣中有許多值相同的數據或有許多零數據,且分布呈現出一定的規律,稱這類型的矩陣為特殊矩陣。
為了節省存儲空間,可以設計算法,對這類特殊矩陣進行壓縮存儲,讓多個相同的非零數據只分配一個存儲空間;對零數據不分配空間。
什么是對稱矩陣?
在一個n階矩陣A中,若所有數據滿足如下述特性,則可稱A為對稱矩陣。
a[i][j]==a[j][i]
i是數據在矩陣中的行號。
j是數據在矩陣中的列號。
0<<i,j<<n-1
在n階對稱矩陣 a[i][j]中,當i==j(行號和列號相同)時所有元素所構建成的集合稱為主對角線。
如下圖所示:
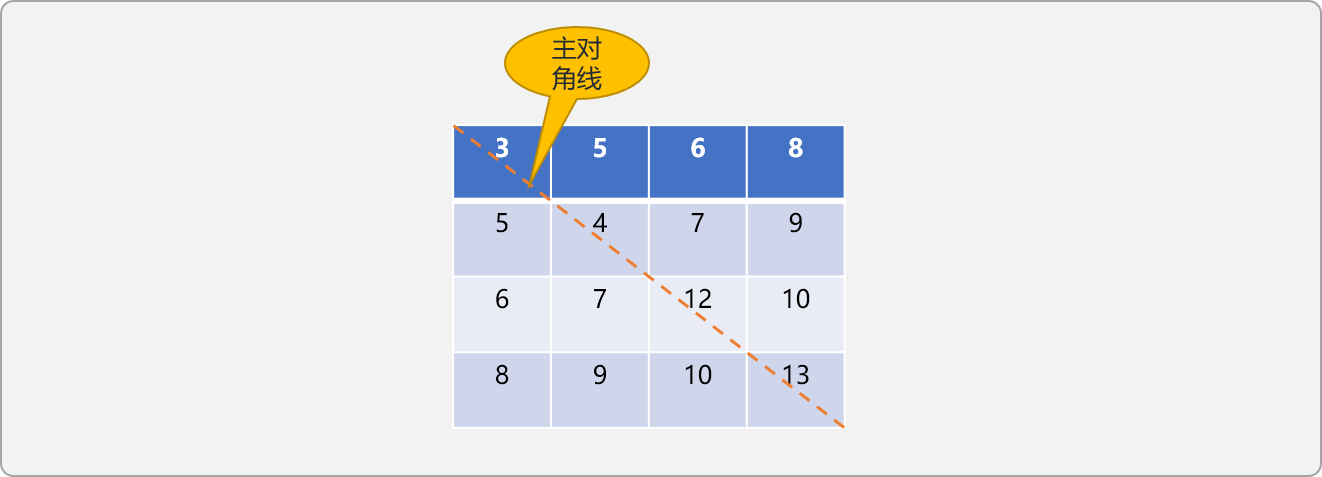
對稱矩陣以主對角線為分界線,把整個矩陣分成 2 個三角區域,主對角線之上的稱為上三角,主對角線之下的區域稱為下三角。
對稱矩陣的上三角和下三角區域中的元素是相同的,以n行n列的二維數組存儲時,會浪費近一半的空間,可以采壓縮機制,將 二維數組中的數據壓縮存儲在一個一維數組中,這個過程也稱為數據線性化。
線性過程時,一維數組的空間需要多大?
n階矩陣,使用二維數組存儲,理論上所需要的存儲單元應該是 n2。
對稱矩陣以主對角線為分界線,上三角和下三角區域中的數據是相同的。注意,主對角線上的元素是需要單獨存儲的,主對角線上的數據個數為 n。
真正需要的存儲單元應該:(理論上所需要的存儲單元-主對角線上的數據所需單元) / 2 +主對角線上的數據所需單元。
如下表達式所述:
(n2-n)/2+n=n(n+1)/2
所以,可以把n階矩陣中的數據可以全部壓縮在長度為 n(n+1)/2 的一維數組中,能節約近一半的存儲空間。并且n階矩陣和一維數組之間滿足如下的位置對應關系:
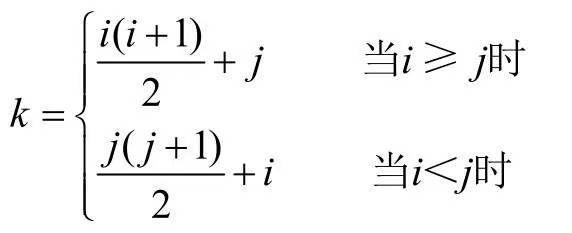
i>=j 表示矩陣中的下三角區域(包含主對角線上數據)。
i<j表示矩陣中的上三角區域。
轉存實現:
#include <iostream>
using namespace std;
int main(int argc, char** argv) {
//對稱矩陣
int nums[4][4]= { {3,5,6,8},{5,4,7,9},{6,7,12,10},{8,9,10,13} };
//一維數組,根據上述公式,一維數組長度為 4*(4+1)/2=10
int zipNums[10]= {0};
for(int i=0; i<4; i++) {
for(int j=0; j<4; j++) {
if (i>=j) {
zipNums[ i*(i+1)/2+j]=nums[i][j];
} else {
zipNums[ j*(j+1)/2+i]=nums[i][j];
}
}
}
for(int i=0; i<10; i++) {
cout<<zipNums[i]<<"\t";
}
return 0;
}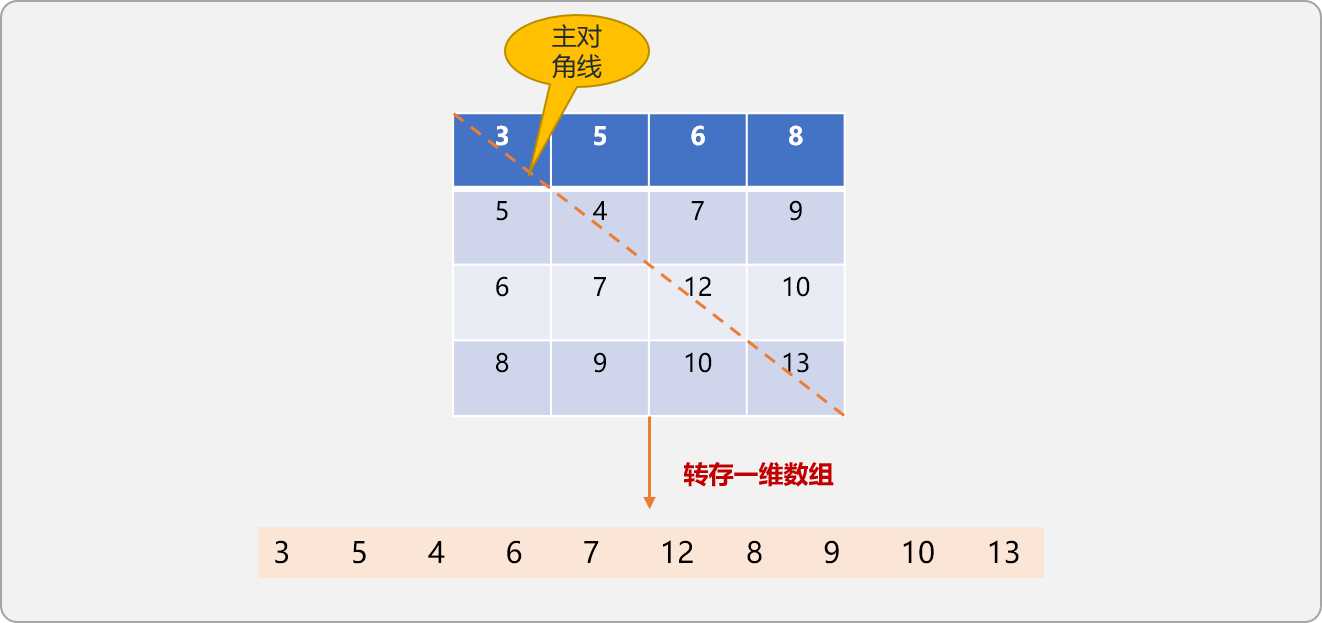
如上是二維數組壓縮到一維數組后的結果。
什么是稀疏矩陣?
如果矩陣A中的有效數據的數量遠遠小于矩陣實際能描述的數據的總數,則稱A為稀疏矩陣。
現假設有 m行n列的矩陣,其中所保存的元素個數為 c,則稀疏因子為:e=c/(m*n)。當用二維數組存儲稀疏矩陣中數據時,僅有少部分空間被利用,可以采用壓縮機制來進行存儲。
稀疏因子越小,表示有效數據越少。
稀疏矩陣中的非零數據的存儲位置是沒有規律的,在壓縮存儲時,除了需要記錄非零數據本身外還需要記錄其位置信息。所以需要一個三元組對象(i,j,a[i][j])對數據進行唯一性確定。
為了便于描述,壓縮前的矩陣稱為原稀疏矩陣,壓縮后的稀疏矩陣稱三元組表矩陣。
原稀疏矩陣也好,三元組表矩陣也好。只要頂著矩陣這個概念,就應該能進行矩陣相應的操作。矩陣的內置操作有很多,本文選擇矩陣的轉置操作來對比壓縮前和壓縮后的算法差異性。
什么是矩陣轉置?
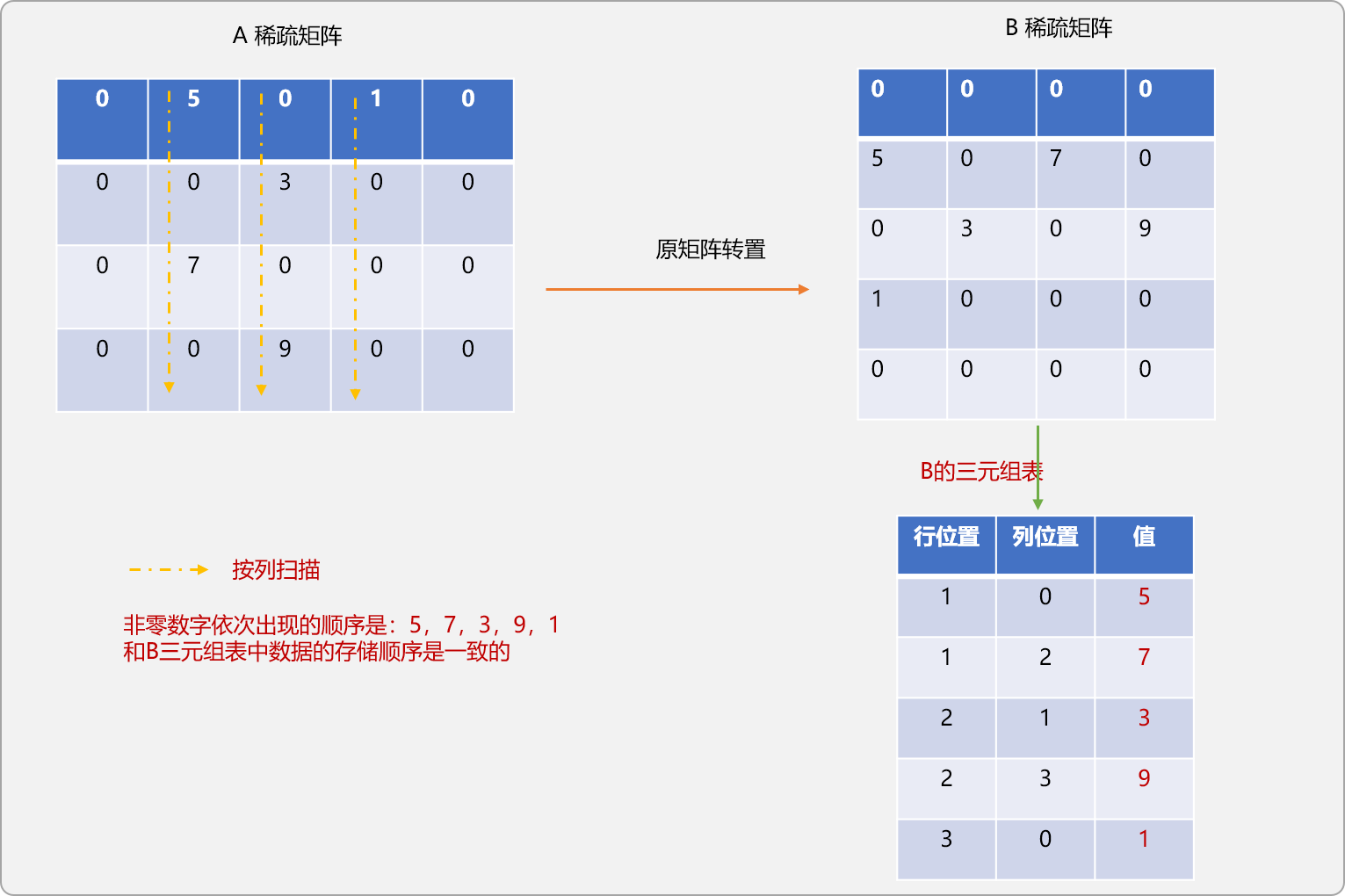
如有 m行n列的A 矩陣,所謂轉置,指把A變成 n行m列的 B矩陣。A和B滿足 A[i][j]=B[j][i]。即A的行變成B的列。如下圖所示:
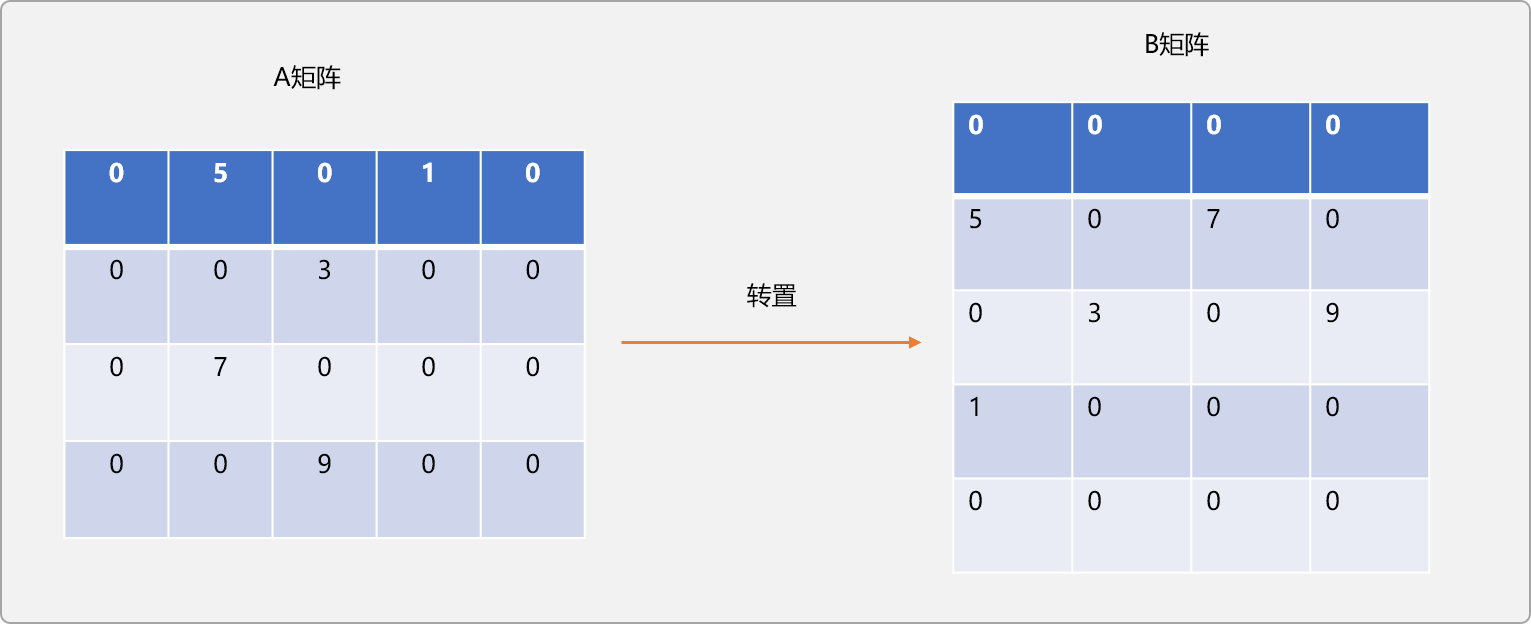
A稀疏矩陣轉置成B稀疏矩陣的原生實現:
//原矩陣
int aArray[4][5]= {{0,5,0,1,0},{0,0,3,0,0},{0,7,0,0,0},{0,0,9,0,0}};
//轉置后矩陣
int bArray[5][4];
//轉置算法
for(int row=0; row<4; row++) {
for(int col=0; col<5; col++) {
bArray[col][row]=aArray[row][col];
}
}基于原生矩陣上的轉置算法,其時間復雜度為 O(m*n),即O(n2)。
從存儲角度而言,aArray矩陣和其轉置后的bArray矩陣都是稀疏矩陣,使用二維數組存儲會浪費大量的空間。有必要對其以三元組表的形式進行壓縮存儲。
三元組表是一個一維數組,因其中的每一個存儲位置需要存儲原稀疏矩陣中非零數據的3 個信息(行,列,值)。三元組表名由此而來,也就是說數組中存儲的是對象。
先來一個圖示,直觀上了解一下A稀疏矩陣壓縮前后的差異性。
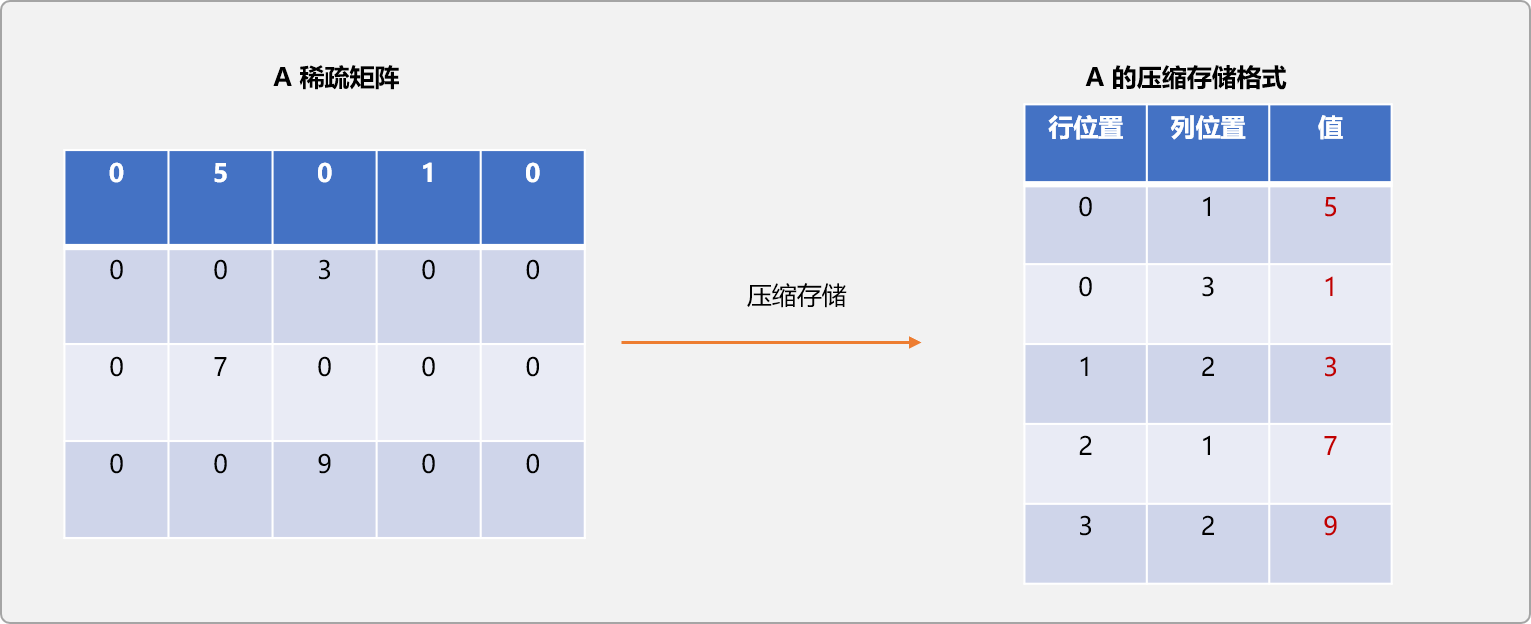
壓縮算法實現:
#include <iostream>
using namespace std;
typedef int DataType;
#define maxSize 100
//三元組結構
struct Node {
//行號
int row=-1;
//列號
int col=-1;
//非零元素的值
DataType val=0;
} ;
//維護三元組表的類
class Matrix {
private:
//位置編號
int idx=0;
//壓縮前稀疏矩陣的行數
int rows;
//壓縮前稀疏矩陣的列數
int cols;
//原稀疏矩陣中非零數據的個數
int terms;
//壓縮存儲的一維數組,初始化
Node node;
Node data[maxSize]= {node};
public:
//構造函數
Matrix(int row,int col) {
this->rows=row;
this->cols=col;
this->terms=0;
}
//存儲三元結點
void setData(int row ,int col,int val) {
Node n;
n.row=row;
n.col=col;
n.val=val;
this->data[idx++]=n;
//記錄非零數據的數量
this->terms++;
}
//重載上面函數
void setData(int index,int row ,int col,int val) {
Node n;
n.row=row;
n.col=col;
n.val=val;
this->data[index]=n;
this->terms++;
}
//顯示三無組表中的數據
void showInfo() {
for(int i=0; i<maxSize; i++ ) {
if(data[i].val==0)break;
cout<<data[i].row<<"\t"<<data[i].col<<"\t"<<data[i].val<<endl;
}
}
//基于三元組表的轉置算法
Matrix transMatrix();
};
int main(int argc, char** argv) {
//原稀疏矩陣
int aArray[4][5]= {{0,5,0,1,0},{0,0,3,0,0},{0,7,0,0,0},{0,0,9,0,0}};
//實例化
Matrix matrix(4,5);
//壓縮矩陣
for(int row=0; row<4; row++) {
for(int col=0; col<5; col++) {
if (aArray[row][col]!=0) {
//轉存至三元組表中
matrix.setData(row,col,aArray[row][col]);
}
}
}
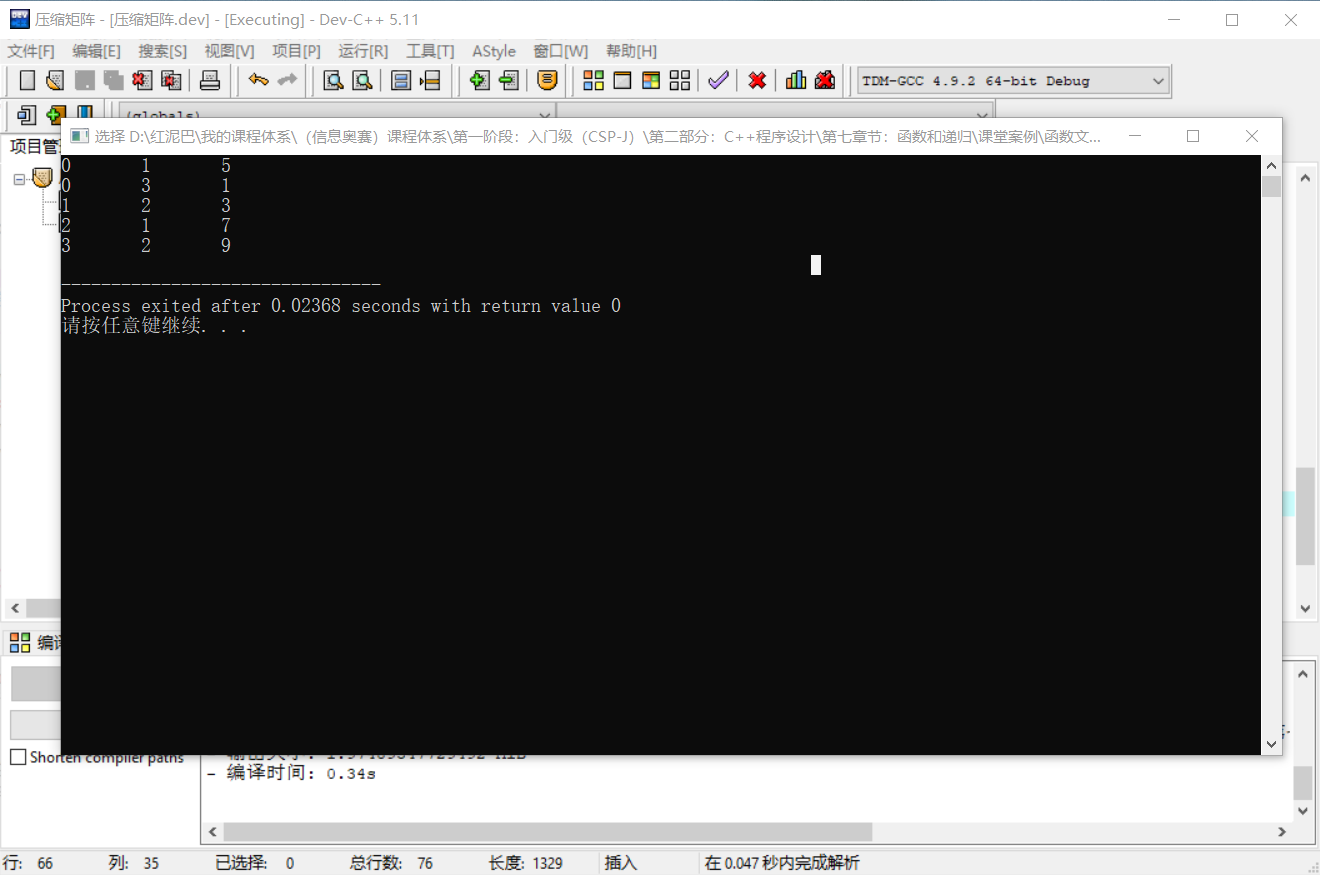
matrix.showInfo();
return 0;
}代碼執行后的結果和直觀圖示結果一致:
壓縮之后,則要思考,如何在A三元組表的基礎上直接實現矩陣的轉置。或者說 ,轉置后的矩陣還是使用三元組表方式描述。
先從直觀上了解一下,轉置后的B矩稀疏陣的三元組表的結構應該是什么樣子。

是否可以通過直接交換A的三元組表中行和列位置中的值?至于可不可以,可以先用演示圖推演一下:

從圖示可知,如果僅是交換A三元組表的行和列位置后得到的新三元組表并不和前面所推演出現的B三元組表一致。
如果仔細觀察,可發現得到的新三元組表的是對原B稀疏表以列優先遍歷后的結果。
B稀疏矩陣的三元組表顯然應該是以行優先遍歷的結果。
經過轉置后,A稀疏矩陣的行會變成B稀疏矩陣的列,也可以說A的列變成B的行。如果在A中以列優先搜索,則相當于在B中以行優先進行搜索。可利用這個簡單而又令人興奮的道理實現基于三元組表的轉置。
Matrix Matrix::transMatrix(){
//轉置后的三元組表對象
Matrix bMatrix(this->cols,this->rows);
//對原稀疏矩陣以列優先搜索
for(int c=0;c<this->cols;c++){
//在對應的三元組表上查找此列上是否有非零數據
for(int j=0;j<this->terms;j++ ){
if(this->data[j].col==c){
//如果此列上有數據,則轉置并保存
bMatrix.setData(this->data[j].col,this->data[j].row,this->data[j].val);
}
}
}
return bMatrix;
}測試代碼:
int main(int argc, char** argv) {
//原稀疏矩陣
int aArray[4][5]= {{0,5,0,1,0},{0,0,3,0,0},{0,7,0,0,0},{0,0,9,0,0}};
//實例化壓縮矩陣
Matrix matrix(4,5);
//壓縮矩陣
for(int row=0; row<4; row++) {
for(int col=0; col<5; col++) {
if (aArray[row][col]!=0) {
matrix.setData(row,col,aArray[row][col]);
}
}
}
cout<<"顯示 A 稀疏矩陣壓縮后的結果:"<<endl;
matrix.showInfo();
cout<<"在A的三元組表的基礎上轉置后的結果:"<<endl;
Matrix bMatrix= matrix.transMatrix();
bMatrix.showInfo();
return 0;
}輸出結果:
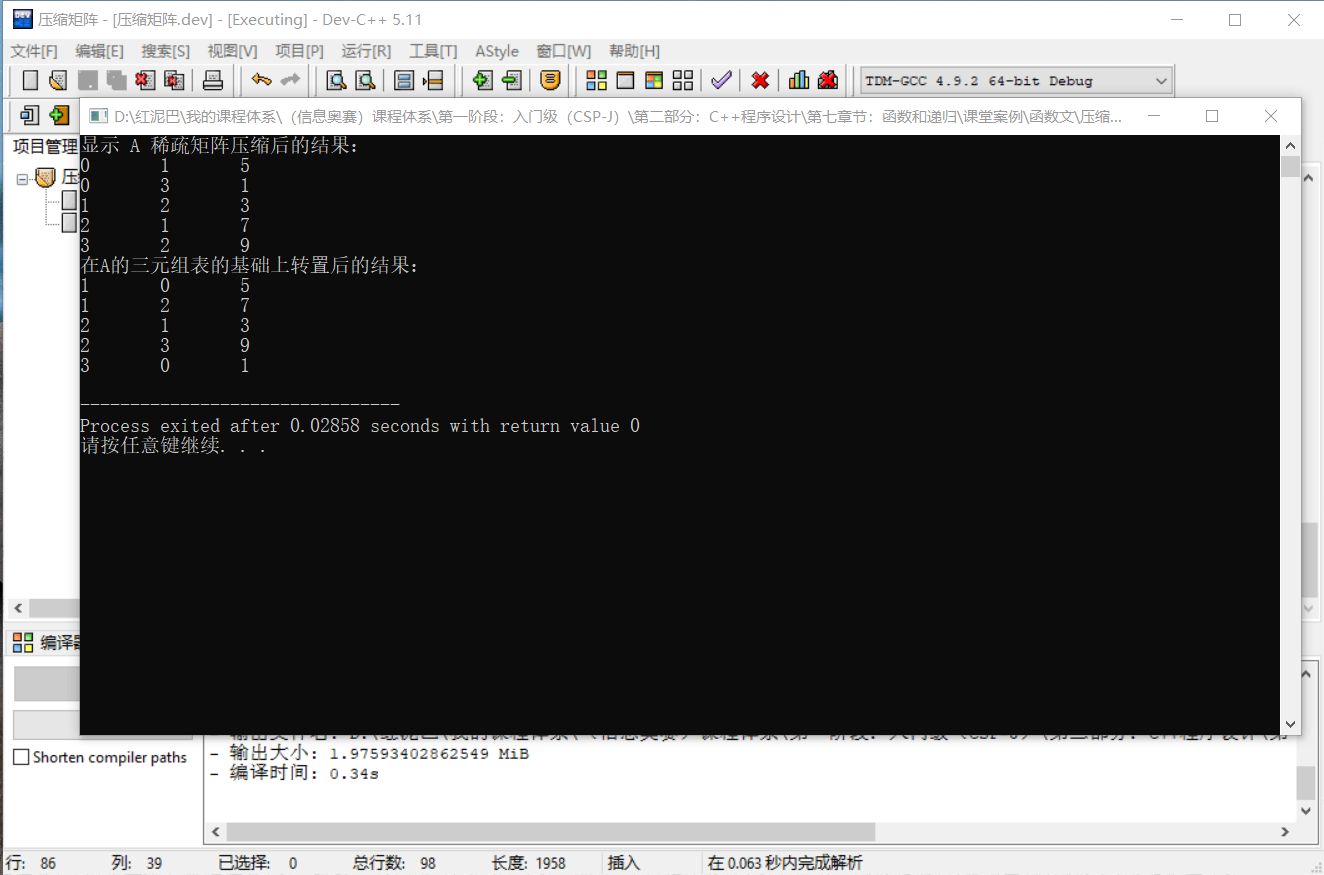
代碼執行后輸出的結果,和前文推演出來的結果是一樣的。
前文可知,基于原生稀疏矩陣上的轉置時間復雜度為 O(m*n)。基于三元組表的 時間復雜度=稀疏矩陣的列數乘以稀疏矩陣中非零數據的個數。當稀疏矩陣中的元素個數為n*m時,則上述的時間復雜度會變成 O(m*n2)。
上述算法適合于當稀疏因子較小時,當矩陣中的非零數據較多時,時間復雜度會較高。可以在上述列優先搜索的算法基礎上進行優化。
其核心思路如下所述:
在原A稀疏矩陣中按列優先進行搜索。
統計每一列中非零數據的個數。
記錄每一列中第一個非零數據在B三元組表中的位置。
對A稀疏矩陣按列遍歷時,可以發現,掃描時,數據出現的順序和其在B三元組表中的存儲順序是一致的。
如果在遍歷時,能記錄每列非零數據在B三元組表中應該存儲的位置,則可以實現A三元組表中的數據直接以轉置要求存儲在B三元組表中。
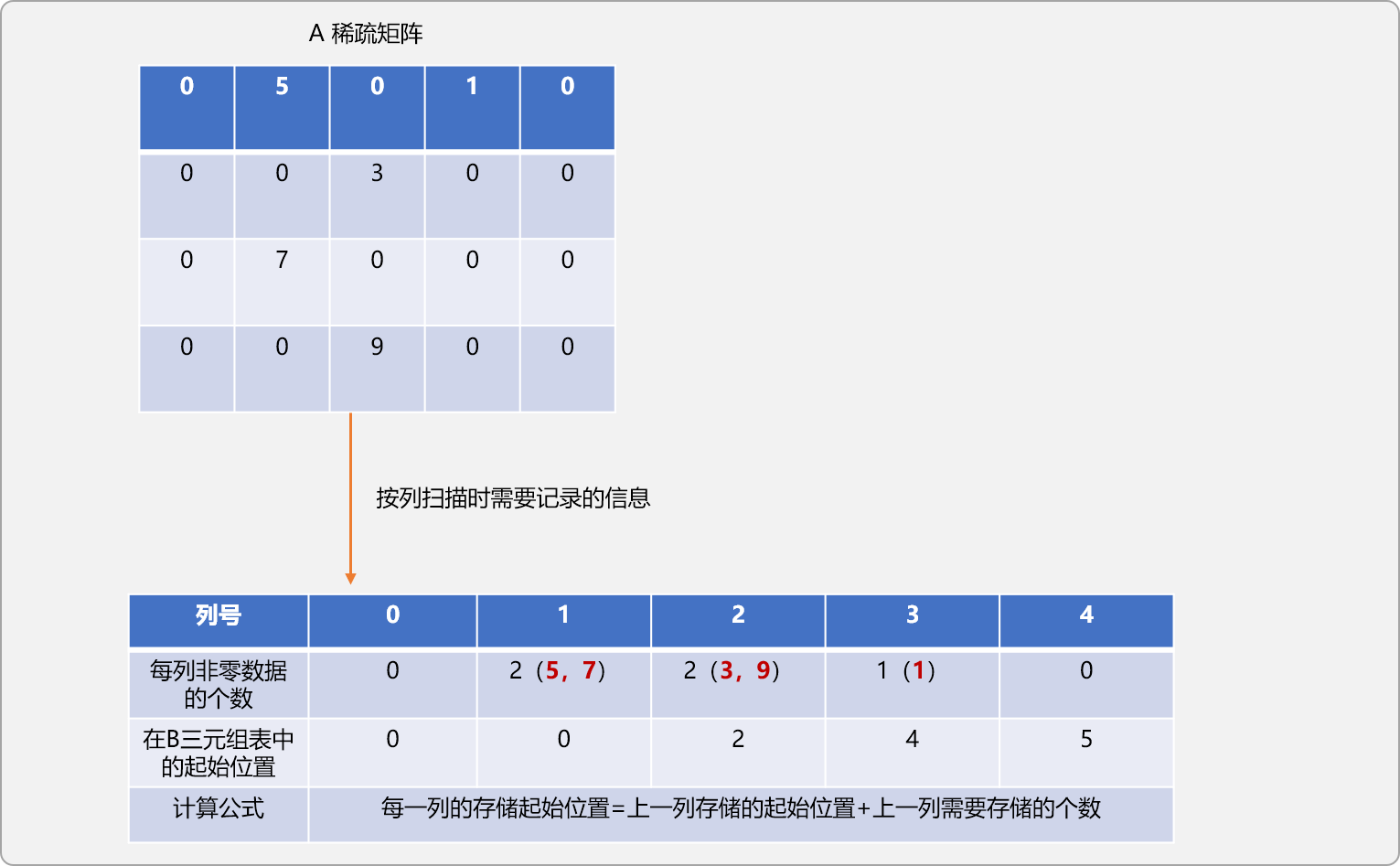
重寫上述的轉置函數。
Matrix Matrix::transMatrix() {
//保存轉置后數據的壓縮矩陣
Matrix bMatrix(this->cols,this->rows);
//初始化數組,用來保存A稀疏矩陣中第一列中非零數據的個數
int counts[this->cols]= {0};
//計算每一列中非零數據個數
for(int i=0; i<this->terms; i++)
counts[this->data[i].col]++;
//初始化數組,用來保存A稀疏矩陣每列中非零數據在B三元組表中的起始位置
int position[this->cols]= {0};
for(int i=1;i<this->cols;i++ ){
//上一列的起始位置加上上一列非零數據的個數
position[i]=position[i-1]+counts[i-1];
}
//轉置A三元組表
for(int i=0;i<this->terms;i++){
int col=this->data[i].col;
int row=this->data[i].row;
int val=this->data[i].val;
//找到在B三元組中的起始存儲位置
int pos=position[col];
bMatrix.setData(pos,col,row,val);
position[col]++;
}
return bMatrix;
}測試代碼不需要任何變化:
int main(int argc, char** argv) {
//原稀疏矩陣
int aArray[4][5]= {{0,5,0,1,0},{0,0,3,0,0},{0,7,0,0,0},{0,0,9,0,0}};
//實例化壓縮矩陣
Matrix matrix(4,5);
//壓縮矩陣
for(int row=0; row<4; row++) {
for(int col=0; col<5; col++) {
if (aArray[row][col]!=0) {
matrix.setData(row,col,aArray[row][col]);
}
}
}
cout<<"顯示 A 稀疏矩陣壓縮后的結果:"<<endl;
matrix.showInfo();
cout<<"在A的三元組表的基礎上轉置后的結果:"<<endl;
Matrix bMatrix= matrix.transMatrix();
bMatrix.showInfo();
return 0;
}輸出結果:
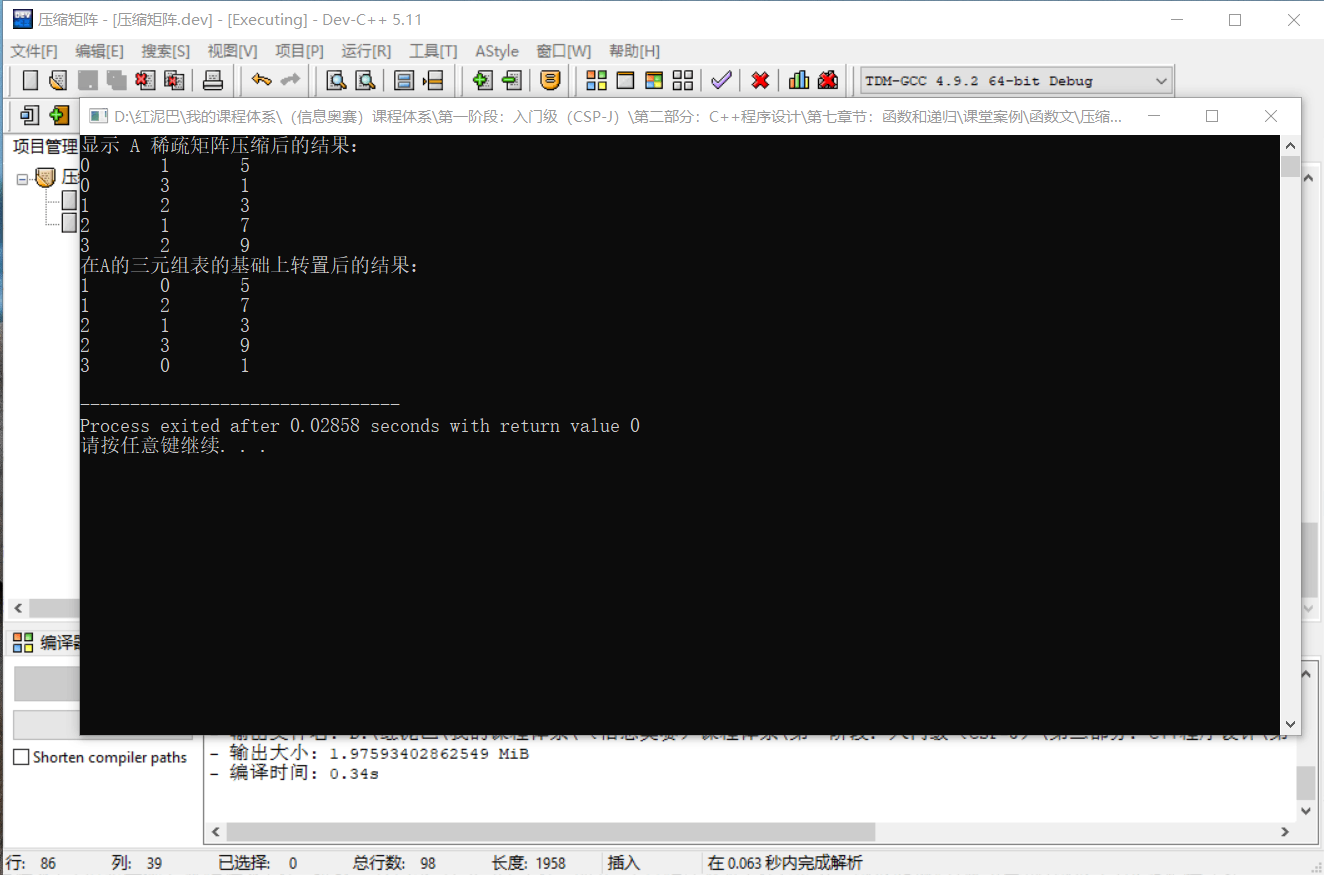
上述 2 種轉置算法,其本質是一樣的,第一種方案更容易理解,第二種方案在第一種方案的基礎上用空間換取了時間上性能的提升。
以上就是關于“C++如何實現特殊矩陣的壓縮存儲算法”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





