溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么使用PyTorch實現隨機搜索策略”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么使用PyTorch實現隨機搜索策略”吧!
一種簡單但有效的方法是將智能體對環境的觀測值映射到代表兩個動作的二維向量,然后我們選擇值較高的動作執行。映射函數使用權重矩陣描述,權重矩陣的形狀為 4 x 2,因為在CarPole環境中狀態是一個 4 維向量,而動作有 2 個可能值。在每個回合中,首先隨機生成權重矩陣,并用于計算此回合中每個步驟的動作,并在回合結束時計算總獎勵。重復此過程,最后將能夠得到最高總獎勵的權重矩陣作為最終的動作選擇策略。由于在每個回合中我們均會隨機選擇權重矩陣,因此稱這種方法為隨機搜索,期望通過在多個回合的測試中找到最佳權重。
在本節中,我們使用 PyTorch 實現隨機搜索算法。
首先,導入 Gym 和 PyTorch 以及其他所需庫,并創建一個 CartPole 環境實例:
import gym
import torch
from matplotlib import pyplot as plt
env = gym.make('CartPole-v0')獲取并打印狀態空間和行動空間的尺寸:
n_state = env.observation_space.shape[0] print(n_state) # 4 n_action = env.action_space.n print(n_action) # 2
當我們在之后定義權重矩陣時,將會使用這些尺寸,即權重矩陣尺寸為 (n_state, n_action) = (4 x 2)。
接下來,定義函數用于使用給定輸入權重模擬 CartPole 環境的一個游戲回合并返回此回合中的總獎勵:
def run_episode(env, weight): state = env.reset() total_reward = 0 is_done = False while not is_done: state = torch.from_numpy(state).float() action = torch.argmax(torch.matmul(state, weight)) state, reward, is_done, _ = env.step(action.item()) total_reward += reward return total_reward
在以上代碼中,我們首先將狀態數組 state 轉換為浮點型張量,然后計算狀態數組和權重矩陣張量的乘積 torch.matmul(state, weight),以將狀態數組進行映射映射為動作數組,使用 torch.argmax() 操作選擇值較高的動作,例如值為 [0.122, 0.333],則應選擇動作 1。然后使用 item() 方法獲取操作結果值,因為此處的 step() 方法需要接受單元素張量,獲取新的狀態和獎勵。重復以上過程,直到回合結束。
指定回合數,并初始化變量用于記錄最佳總獎勵和相應權重矩陣,并初始化數組用于記錄每個回合的總獎勵:
n_episode = 1000 best_total_reward = 0 best_weight = None total_rewards = []
接下來,我們運行 n_episode 個回合,在每個回合中,執行以下操作:
構建隨機權重矩陣
智能體根據權重矩陣將狀態映射到相應的動作
回合終止并返回總獎勵
更新最佳總獎勵和最佳權重,并記錄總獎勵
for e in range(n_episode):
weight = torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
print('Episode {}: {}'.format(e+1, total_reward))
if total_reward > best_total_reward:
best_weight = weight
best_total_reward = total_reward
total_rewards.append(total_reward)運行 1000 次隨機搜索獲得最佳策略,最佳策略由 best_weight 參數化。在測試最佳策略之前,我們可以計算通過隨機搜索獲得的平均總獎勵:
print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards) / n_episode))
# Average total reward over 1000 episode: 46.722可以看到,對比使用隨機動作獲得的結果 (22.19),使用隨機搜索獲取的總獎勵是其兩倍以上。
接下來,我們使用隨機搜索得到的最佳權重矩陣,在 1000 個新的回合中測試其表現如何:
n_episode_eval = 1000
total_rewards_eval = []
for episode in range(n_episode_eval):
total_reward = run_episode(env, best_weight)
print('Episode {}: {}'.format(episode+1, total_reward))
total_rewards_eval.append(total_reward)
print('Average total reward over {} episode: {}'.format(n_episode_eval, sum(total_rewards_eval) / n_episode_eval))
# Average total reward over 1000 episode: 114.786隨機搜索算法的效果能夠獲取較好結果的主要原因是 CartPole 環境較為簡單。它的觀察狀態數組僅由四個變量組成。而在 Atari Space Invaders 游戲中的觀察值超過 100000 (即 210 \times 160 \times 3210×160×3)。同樣 CartPole 中動作狀態的維數也僅僅為 2。通常,使用簡單算法可以很好地解決簡單問題。
我們也可以注意到,隨機搜索策略的性能優于隨機選擇動作。這是因為隨機搜索策略將智能體對環境的當前狀態考慮在內。有了關于環境的相關信息,隨機搜索策略中的動作就可以比完全隨機的選擇動作更加智能。
我們還可以在訓練和測試階段繪制每個回合的總獎勵:
plt.plot(total_rewards, label='search')
plt.plot(total_rewards_eval, label='eval')
plt.xlabel('episode')
plt.ylabel('total_reward')
plt.legend()
plt.show()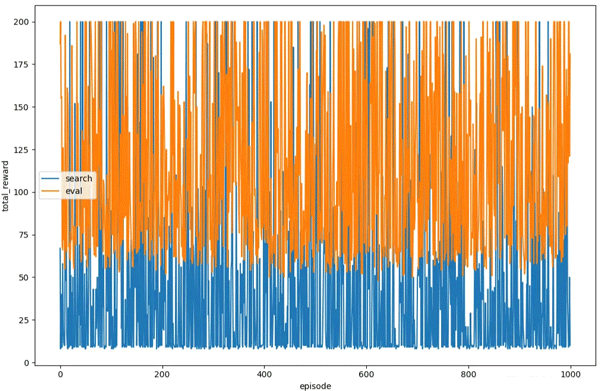
可以看到,每個回合的總獎勵是非常隨機的,并且并沒有因為回合數的增加顯示出改善的趨勢。在訓練過程中,可以看到在實現前期有些回合的總獎勵已經可以達到 200,由于智能體的策略并不會因為回合數的增加而改善,因此我們可以在回合總獎勵達到 200 時結束訓練:
n_episode = 1000
best_total_reward = 0
best_weight = None
total_rewards = []
for episode in range(n_episode):
weight = torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
print('Episode {}: {}'.format(episode+1, total_reward))
if total_reward > best_total_reward:
best_weight = weight
best_total_reward = total_reward
total_rewards.append(total_reward)
if best_total_reward == 200:
break由于每回合的權重都是隨機生成的,因此獲取最大獎勵的策略出現的回合也并不確定。要計算所需訓練回合的期望,可以重復以上訓練過程 1000 次,并取訓練次數的平均值作為期望:
n_training = 1000
n_episode_training = []
for _ in range(n_training):
for episode in range(n_episode):
weight = torch.rand(n_state, n_action)
total_reward = run_episode(env, weight)
if total_reward == 200:
n_episode_training.append(episode+1)
break
print('Expectation of training episodes needed: ', sum(n_episode_training) / n_training)
# Expectation of training episodes needed: 14.26可以看到,平均而言,我們預計大約需要 14 個回合才能找到最佳策略。
到此,相信大家對“怎么使用PyTorch實現隨機搜索策略”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





