溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Python+FuzzyWuzzy怎么實現模糊匹配的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
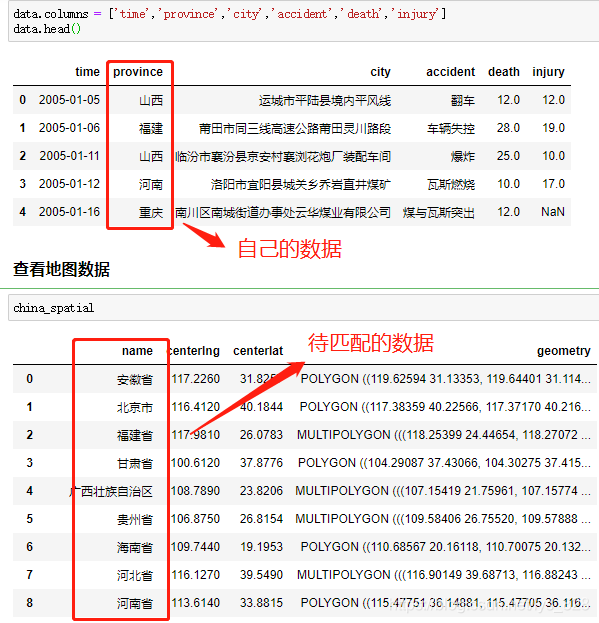
在處理數據的過程中,難免會遇到下面類似的場景,自己手里頭獲得的是簡化版的數據字段,但是要比對的或者要合并的卻是完整版的數據(有時候也會反過來)
最常見的一個例子就是:在進行地理可視化中,自己收集的數據只保留的縮寫,比如北京,廣西,新疆,西藏等,但是待匹配的字段數據卻是北京市,廣西壯族自治區,新疆維吾爾自治區,西藏自治區等,如下。因此就需要有沒有一種方式可以很快速便捷的直接進行對應字段的匹配并將結果單獨生成一列,就可以用到FuzzyWuzzy庫。
FuzzyWuzzy 是一個簡單易用的模糊字符串匹配工具包。它依據 Levenshtein Distance 算法,計算兩個序列之間的差異。
Levenshtein Distance算法,又叫 Edit Distance算法,是指兩個字符串之間,由一個轉成另一個所需的最少編輯操作次數。許可的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符。一般來說,編輯距離越小,兩個串的相似度越大。
這里使用的是Anaconda下的jupyter notebook編程環境,因此在Anaconda的命令行中輸入一下指令進行第三方庫安裝。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple FuzzyWuzzy
該模塊下主要介紹四個函數(方法),分別為:簡單匹配(Ratio)、非完全匹配(Partial Ratio)、忽略順序匹配(Token Sort Ratio)和去重子集匹配(Token Set Ratio)
注意: 如果直接導入這個模塊的話,系統會提示warning,當然這不代表報錯,程序依舊可以運行(使用的默認算法,執行速度較慢),可以按照系統的提示安裝python-Levenshtein庫進行輔助,這有利于提高計算的速度。

2.1.1 簡單匹配(Ratio)
簡單的了解一下就行,這個不怎么精確,也不常用
fuzz.ratio("河南省", "河南省")
>>> 100
>
fuzz.ratio("河南", "河南省")
>>> 802.1.2 非完全匹配(Partial Ratio)
盡量使用非完全匹配,精度較高
fuzz.partial_ratio("河南省", "河南省")
>>> 100
fuzz.partial_ratio("河南", "河南省")
>>> 1002.1.3 忽略順序匹配(Token Sort Ratio)
原理在于:以 空格 為分隔符,小寫 化所有字母,無視空格外的其它標點符號
fuzz.ratio("西藏 自治區", "自治區 西藏")
>>> 50
fuzz.ratio('I love YOU','YOU LOVE I')
>>> 30
fuzz.token_sort_ratio("西藏 自治區", "自治區 西藏")
>>> 100
fuzz.token_sort_ratio('I love YOU','YOU LOVE I')
>>> 1002.1.4 去重子集匹配(Token Set Ratio)
相當于比對之前有一個集合去重的過程,注意最后兩個,可理解為該方法是在token_sort_ratio方法的基礎上添加了集合去重的功能,下面三個匹配的都是倒序
fuzz.ratio("西藏 西藏 自治區", "自治區 西藏")
>>> 40
fuzz.token_sort_ratio("西藏 西藏 自治區", "自治區 西藏")
>>> 80
fuzz.token_set_ratio("西藏 西藏 自治區", "自治區 西藏")
>>> 100fuzz這幾個ratio()函數(方法)最后得到的結果都是數字,如果需要獲得匹配度最高的字符串結果,還需要依舊自己的數據類型選擇不同的函數,然后再進行結果提取,如果但看文本數據的匹配程度使用這種方式是可以量化的,但是對于我們要提取匹配的結果來說就不是很方便了,因此就有了process模塊。
用于處理備選答案有限的情況,返回模糊匹配的字符串和相似度。
2.2.1 extract提取多條數據
類似于爬蟲中select,返回的是列表,其中會包含很多匹配的數據
choices = ["河南省", "鄭州市", "湖北省", "武漢市"]
process.extract("鄭州", choices, limit=2)
>>> [('鄭州市', 90), ('河南省', 0)]
# extract之后的數據類型是列表,即使limit=1,最后還是列表,注意和下面extractOne的區別2.2.2 extractOne提取一條數據
如果要提取匹配度最大的結果,可以使用extractOne,注意這里返回的是 元組 類型, 還有就是匹配度最大的結果不一定是我們想要的數據,可以通過下面的示例和兩個實戰應用體會一下
process.extractOne("鄭州", choices)
>>> ('鄭州市', 90)
process.extractOne("北京", choices)
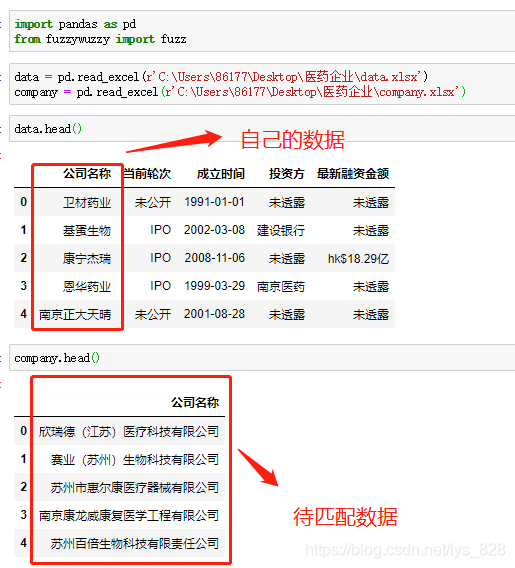
>>> ('湖北省', 45)這里舉兩個實戰應用的小例子,第一個是公司名稱字段的模糊匹配,第二個是省市字段的模糊匹配
數據及待匹配的數據樣式如下:自己獲取到的數據字段的名稱很簡潔,并不是公司的全稱,因此需要進行兩個字段的合并
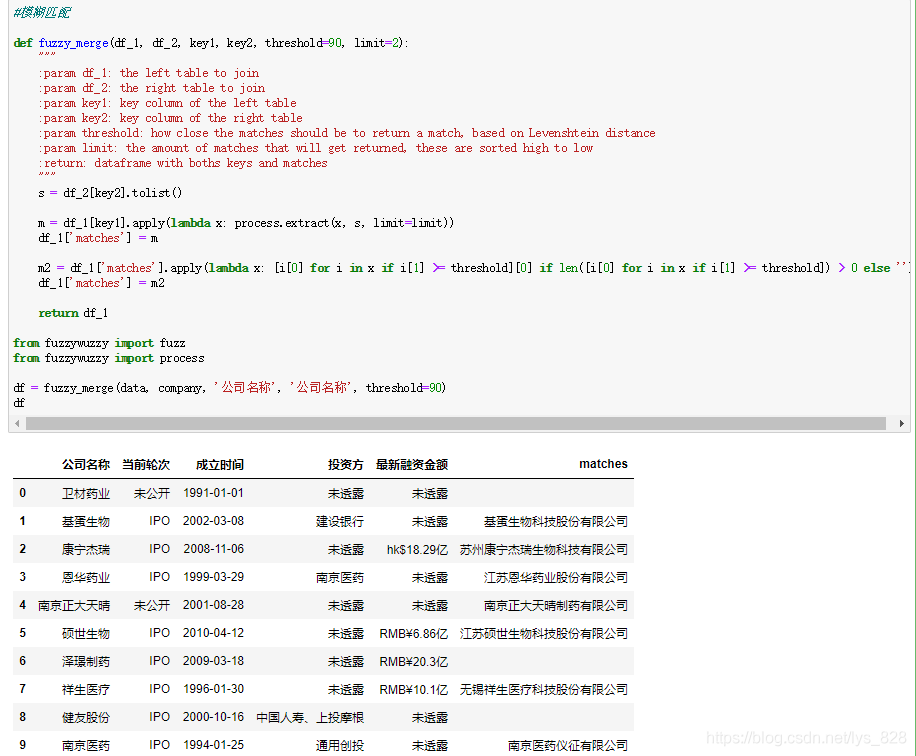
直接將代碼封裝為函數,主要是為了方便日后的調用,這里參數設置的比較詳細,執行結果如下:
3.1.1 參數講解:
① 第一個參數df_1是自己獲取的欲合并的左側數據(這里是data變量);
② 第二個參數df_2是待匹配的欲合并的右側數據(這里是company變量);
③ 第三個參數key1是df_1中要處理的字段名稱(這里是data變量里的‘公司名稱’字段)
④ 第四個參數key2是df_2中要匹配的字段名稱(這里是company變量里的‘公司名稱’字段)
⑤ 第五個參數threshold是設定提取結果匹配度的標準。注意這里就是對extractOne方法的完善,提取到的最大匹配度的結果并不一定是我們需要的,所以需要設定一個閾值來評判,這個值就為90,只有是大于等于90,這個匹配結果我們才可以接受
⑥ 第六個參數,默認參數就是只返回兩個匹配成功的結果
⑦ 返回值:為df_1添加‘matches’字段后的新的DataFrame數據
3.1.2 核心代碼講解
第一部分代碼如下,可以參考上面講解process.extract方法,這里就是直接使用,所以返回的結果m就是列表中嵌套元祖的數據格式,樣式為: [(‘鄭州市’, 90), (‘河南省’, 0)],因此第一次寫入到’matches’字段中的數據也就是這種格式
注意,注意: 元祖中的第一個是匹配成功的字符串,第二個就是設置的threshold參數比對的數字對象
s = df_2[key2].tolist() m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit)) df_1['matches'] = m
第二部分的核心代碼如下,有了上面的梳理,明確了‘matches’字段中的數據類型,然后就是進行數據的提取了,需要處理的部分有兩點需要注意的:
① 提取匹配成功的字符串,并對閾值小于90的數據填充空值
② 最后把數據添加到‘matches’字段
m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '')
#要理解第一個‘matches'字段返回的數據類型是什么樣子的,就不難理解這行代碼了
#參考一下這個格式:[('鄭州市', 90), ('河南省', 0)]
df_1['matches'] = m2
return df_1自己的數據和待匹配的數據背景介紹中已經有圖片顯示了,上面也已經封裝了模糊匹配的函數,這里直接調用上面的函數,輸入相應的參數即可,代碼以及執行結果如下:
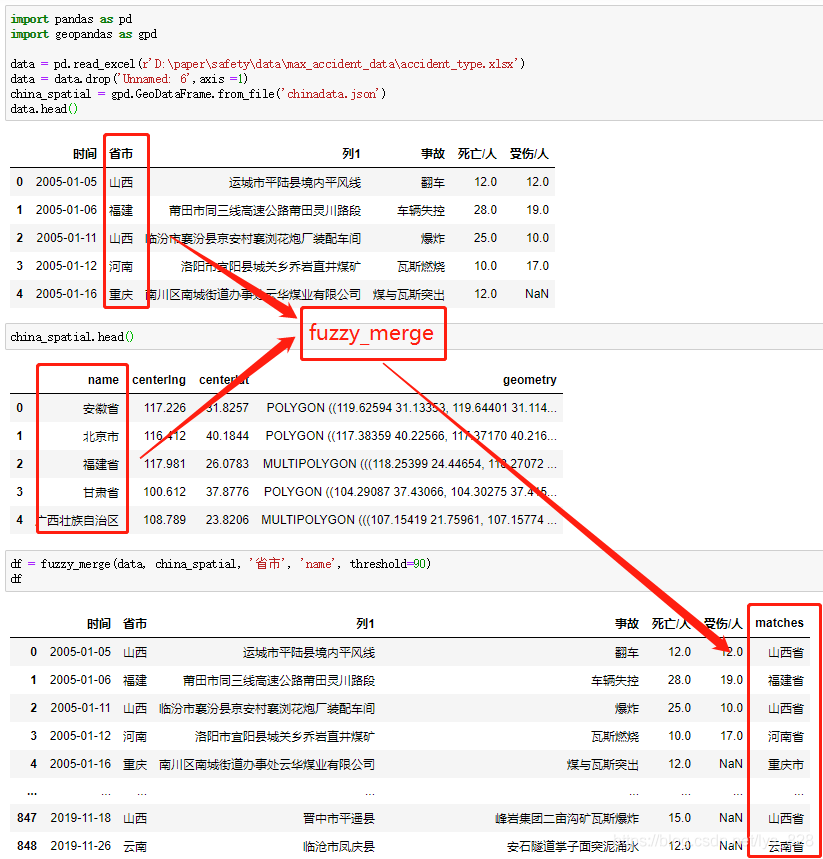
數據處理完成,經過封裝后的函數可以直接放在自己自定義的模塊名文件下面,以后可以方便直接導入函數名即可,可以參考將自定義常用的一些函數封裝成可以直接調用的模塊方法。
#模糊匹配 def fuzzy_merge(df_1, df_2, key1, key2, threshold=90, limit=2): """ :param df_1: the left table to join :param df_2: the right table to join :param key1: key column of the left table :param key2: key column of the right table :param threshold: how close the matches should be to return a match, based on Levenshtein distance :param limit: the amount of matches that will get returned, these are sorted high to low :return: dataframe with boths keys and matches """ s = df_2[key2].tolist() m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit)) df_1['matches'] = m m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '') df_1['matches'] = m2 return df_1 from fuzzywuzzy import fuzz from fuzzywuzzy import process df = fuzzy_merge(data, company, '公司名稱', '公司名稱', threshold=90) df
以上就是“Python+FuzzyWuzzy怎么實現模糊匹配”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





