溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Apache Hudi內核文件標記機制的示例分析,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
Hudi 支持在寫入時自動清理未成功提交的數據。Apache Hudi 在寫入時引入標記機制來有效跟蹤寫入存儲的數據文件。 在本博客中,我們將深入探討現有直接標記文件機制的設計,并解釋了其在云存儲(如 AWS S3、Aliyun OSS)上針對非常大批量寫入的性能問題。 并且演示如何通過引入基于時間軸服務器的標記來提高寫入性能。
Hudi中的marker是一個表示存儲中存在對應的數據文件的標簽,Hudi使用它在故障和回滾場景中自動清理未提交的數據。
每個標記條目由三部分組成
數據文件名
標記擴展名 (.marker)
創建文件的 I/O 操作(CREATE - 插入、MERGE - 更新/刪除或 APPEND - 兩者之一)。
例如標記91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet.marker.CREATE指示相應的數據文件是91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet
并且 I/O 類型是 CREATE。
在寫入每個數據文件之前,Hudi 寫入客戶端首先在存儲中創建一個標記,該標記會被持久化,在提交成功后會被寫入客戶端顯式刪除。
標記對于寫客戶端有效地執行不同的操作很有用,標記主要有如下兩個作用
刪除重復/部分數據文件:通過 Spark 寫入 Hudi 時會有多個 Executor 進行并發寫入。一個 Executor 可能失敗,留下部分數據文件寫入,在這種情況下 Spark 會重試 Task ,當啟用speculative execution時,可以有多次attempts成功將相同的數據寫入不同的文件,但最終只有一次attempt會交給 Spark Driver程序進程進行提交。標記有助于有效識別寫入的部分數據文件,其中包含與后來成功寫入的數據文件相比的重復數據,并在寫入和提交完成之前清理這些重復的數據文件。
回滾失敗的提交:寫入時可能在中間失敗,留下部分寫入的數據文件。在這種情況下,標記條目會在提交失敗時保留在存儲中。在接下來的寫操作中,寫客戶端首先回滾失敗的提交,通過標記識別這些提交中寫入的數據文件并刪除它們。
接下來我們將深入研究現有的標記機制,闡述其性能問題,并演示新的基于時間軸服務器的標記機制來解決該問題。
現有的標記機制簡單地創建與每個數據文件相對應的新標記文件,標記文件名如前面所述。 每個 marker 文件被寫入在相同的目錄層次結構中,即提交即時和分區路徑,在Hudi表的基本路徑下的臨時文件夾.hoodie/.temp下。 例如,下圖顯示了向 Hudi 表寫入數據時創建的標記文件和相應數據文件的示例。 在獲取或刪除所有marker文件路徑時,該機制首先列出臨時文件夾.hoodie/.temp/<commit_instant>下的所有路徑,然后進行操作。
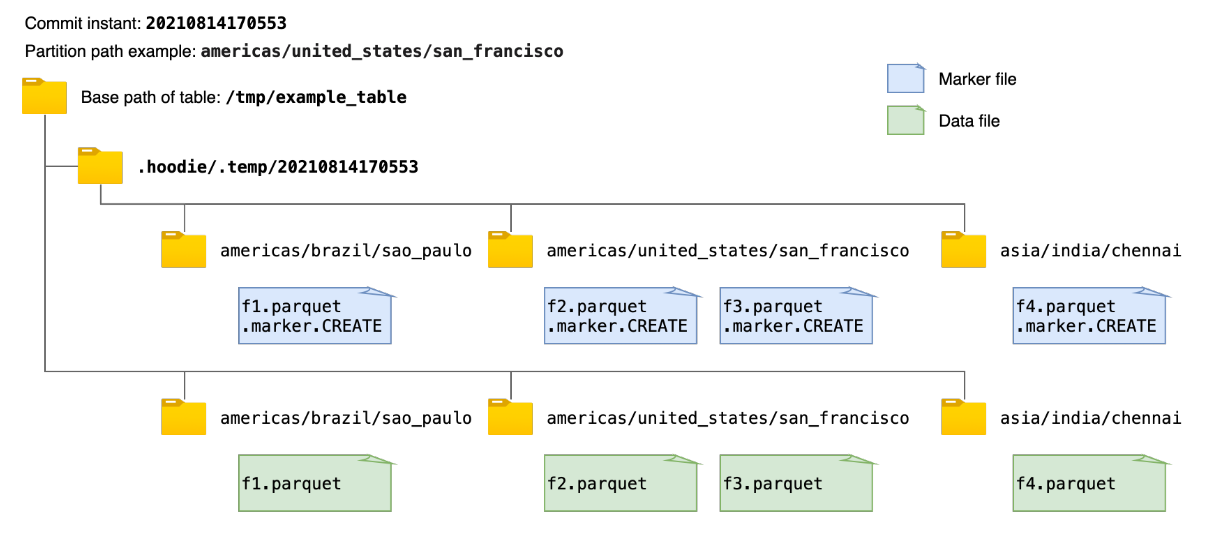
雖然掃描整個表以查找未提交的數據文件效率更高,但隨著要寫入的數據文件數量的增加,要創建的標記文件的數量也會增加。 這可能會為 AWS S3 等云存儲帶來性能瓶頸。 在 AWS S3 中,每個文件創建和刪除調用都會觸發一個 HTTP 請求,并且對存儲桶中每個前綴每秒可以處理的請求數有速率限制。 當并發寫入的數據文件數量和 marker 文件數量巨大時,marker 文件的操作會成為寫入性能的顯著性能瓶頸。而在像 HDFS 這樣的存儲上,用戶可能幾乎不會注意到這一點,其中文件系統元數據被有效地緩存在內存中。
為解決上述 AWS S3 速率限制導致的性能瓶頸,我們引入了一種利用時間線服務器的新標記機制,該機制優化了存儲標記的相關延遲。 Hudi 中的時間線服務器用作提供文件系統和時間線視圖。 如下圖所示,新的基于時間線服務器的標記機制將標記創建和其他標記相關操作從各個執行器委托給時間線服務器進行集中處理。 時間線服務器在內存中為相應的標記請求維護創建的標記,時間線服務器通過定期將內存標記刷新到存儲中有限數量的底層文件來實現一致性。 通過這種方式,即使數據文件數量龐大,也可以顯著減少與標記相關的實際文件操作次數和延遲,從而提高寫入性能。

為了提高處理標記創建請求的效率,我們設計了在時間線服務器上批量處理標記請求。 每個標記創建請求在 Javalin 時間線服務器中異步處理,并在處理前排隊。 對于每個批處理間隔,例如 20 毫秒,調度線程從隊列中拉出待處理的請求并將它們發送到工作線程進行處理。 每個工作線程處理標記創建請求,并通過重寫存儲標記的底層文件。有多個工作線程并發運行,考慮到文件覆蓋的時間比批處理時間長,每個工作線程寫入一個不被其他線程觸及的獨占文件以保證一致性和正確性。 批處理間隔和工作線程數都可以通過寫入選項進行配置。
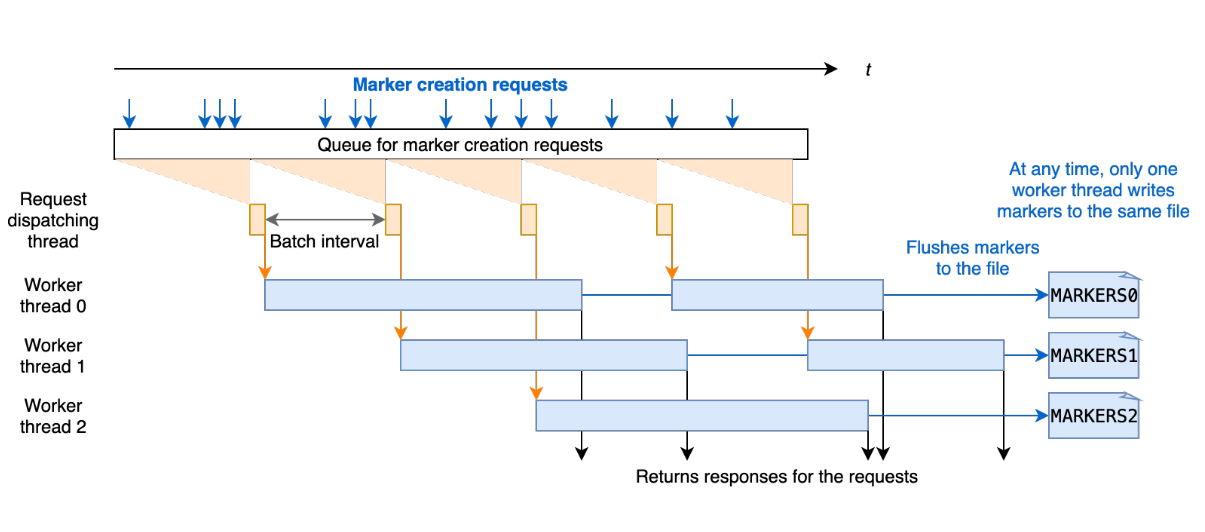
請注意工作線程始終通過將請求中的標記名稱與時間線服務器上維護的所有標記的內存副本進行比較來檢查標記是否已經創建。 存儲標記的底層文件僅在第一個標記請求(延遲加載)時讀取。 請求的響應只有在新標記刷新到文件后才會返回,以便在時間線服務器故障的情況下,時間線服務器可以恢復已經創建的標記。 這些確保存儲和內存中副本之間的一致性,并提高處理標記請求的性能。
我們在 0.9.0 版本中引入了以下與標記相關的新寫入選項,以配置標記機制。
hoodie.write.markers.type,要使用的標記類型。支持兩種模式: direct,每個數據文件對應的單獨標記文件由編寫器直接創建; timeline_server_based,標記操作全部在時間線服務中處理作為代理。 為了提高效率新的標記條目被批處理并存儲在有限數量的基礎文件中。默認值為direct。
hoodie.markers.timeline_server_based.batch.num_threads,用于在時間軸服務器上批處理標記創建請求的線程數。默認值為20。
hoodie.markers.timeline_server_based.batch.interval_ms,標記創建批處理的批處理間隔(以毫秒為單位)。默認值為50。
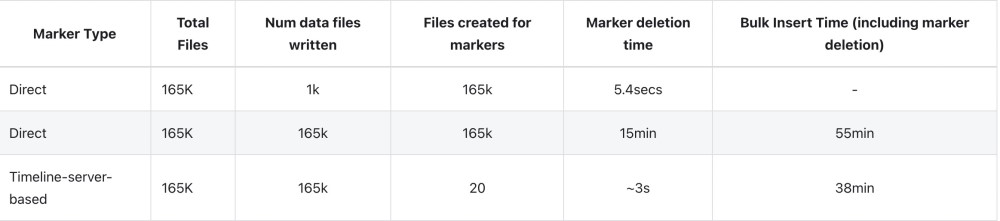
我們通過使用 Amazon EMR 和 Spark 和 S3 批量插入大規模數據集來評估direct和timeline_server_based的標記機制的寫入性能。 輸入數據大約為 100GB。 我們通過設置最大 parquet 文件大小為 1MB 和并行度為 240 來配置寫入操作以并發生成大量數據文件。 正如我們之前提到的,而直接標記機制的延遲對于較小數量的增量寫入是可以接受的,對于產生更多數據文件的大批量插入/寫入,開銷會急劇增加。
如下圖所示,由于是批處理,基于時間線服務器的標記機制生成的存儲標記的文件要少得多,從而導致標記相關的 I/O 操作的時間要少得多,因此與直接相比,寫入完成時間減少了 31%。 標記文件機制。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Apache Hudi內核文件標記機制的示例分析”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





