溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Netty分布式ByteBuf使用subPage級別內存分配的方法”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Netty分布式ByteBuf使用subPage級別內存分配的方法”文章能幫助大家解決問題。
簡單起見, 我們這里僅僅以16字節為例, 講解其分配邏輯
在分析其邏輯前, 首先看PoolArean的一個屬性:
private final PoolSubpage<T>[] tinySubpagePools;
這個屬性是一個PoolSubpage的數組, 有點類似于一個subpage的緩存, 我們創建一個subpage之后, 會將創建的subpage與該屬性其中每個關聯, 下次在分配的時候可以直接通過該屬性的元素去找關聯的subpage
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools);
這里為numTinySubpagePools為32
跟到newSubpagePoolArray(numTinySubpagePools)方法里:
private PoolSubpage<T>[] newSubpagePoolArray(int size) {
return new PoolSubpage[size];
}這里直接創建了一個PoolSubpage數組, 長度為32
for (int i = 0; i < tinySubpagePools.length; i ++) {
tinySubpagePools[i] = newSubpagePoolHead(pageSize);
}我們跟到newSubpagePoolHead中:
private PoolSubpage<T> newSubpagePoolHead(int pageSize) {
PoolSubpage<T> head = new PoolSubpage<T>(pageSize);
head.prev = head;
head.next = head;
return head;
}這里創建了一個PoolSubpage對象head
head.prev = head; head.next = head;
這種寫法我們知道Subpage其實也是個雙向鏈表, 這里的將head的上一個節點和下一個節點都設置為自身, 有關PoolSubpage的關聯關系, 我們稍后會看到
這樣通過循環創建PoolSubpage, 總共會創建出32個subpage, 其中每個subpage實際代表一塊內存大小:

5-8-1
這里就有點類之前小節的緩存數組tinySubPageDirectCaches的結構
了解了tinySubpagePools屬性, 我們看PoolArean的allocate方法, 也就是緩沖區的入口方法:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
//規格化
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) {
int tableIdx;
PoolSubpage<T>[] table;
//判斷是不是tinty
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
//緩存分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
//通過tinyIdx拿到tableIdx
tableIdx = tinyIdx(normCapacity);
//subpage的數組
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
//拿到對應的節點
final PoolSubpage<T> head = table[tableIdx];
synchronized (head) {
final PoolSubpage<T> s = head.next;
//默認情況下, head的next也是自身
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
//首先在緩存上進行內存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
//分配成功, 返回
return;
}
//分配不成功, 做實際的內存分配
allocateNormal(buf, reqCapacity, normCapacity);
} else {
//大于這個值, 就不在緩存上分配
allocateHuge(buf, reqCapacity);
}
}之前我們最這個方法剖析過在page級別相關內存分配邏輯, 這一小節看subpage級別分配的相關邏輯
假設我們分配16字節的緩沖區, isTinyOrSmall(normCapacity)就會返回true, 進入if塊
同樣if (tiny)這里會返回true, 繼續跟到if (tiny)中:
首先會在緩存中分配緩沖區, 如果分配不到, 就開辟一塊內存進行內存分配
首先看這一步:
tableIdx = tinyIdx(normCapacity);
我們跟進去:
static int tinyIdx(int normCapacity) {
return normCapacity >>> 4;
}這里將normCapacity除以16, 其實也就是1
我們回到PoolArena的allocate方法繼續看:
table = tinySubpagePools
這里將tinySubpagePools賦值到局部變量table中, 繼續往下看
final PoolSubpage<T> head = table[tableIdx]
這步時通過下標拿到一個PoolSubpage, 因為我們以16字節為例, 所以我們拿到下標為1的PoolSubpage, 對應的內存大小也就是16B
再看 final PoolSubpage<T> s = head.next 這一步, 跟我們剛才了解的的tinySubpagePools屬性, 默認情況下head.next也是自身, 所以if (s != head)會返回false, 我們繼續往下看:
下面, 會走到allocateNormal(buf, reqCapacity, normCapacity)這個方法:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原來的chunk上進行內存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//創建chunk進行內存分配(2)
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}這里的邏輯我們之前的小節已經剖析過, 首先在原來的chunk中分配, 如果分配不成功, 則會創建chunk進行分配
我們看這一步
long handle = c.allocate(normCapacity)
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) {
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity);
}
}上一小節我們分析page級別分配的時候, 剖析的是allocateRun(normCapacity)方法
因為這里我們是以16字節舉例, 所以這次我們剖析allocateSubpage(normCapacity)方法, 也就是在subpage級別進行內存分配
private long allocateSubpage(int normCapacity) {
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
int d = maxOrder;
//表示在第11層分配節點
int id = allocateNode(d);
if (id < 0) {
return id;
}
//獲取初始化的subpage
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
//表示第幾個subpageIdx
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
//如果subpage為空
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
//則將當前的下標賦值為subpage
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
//取出一個子page
return subpage.allocate();
}
}首先, 通過 PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity) 這種方式找到head節點, 實際上這里head, 就是我們剛才分析的tinySubpagePools屬性的第一個節點, 也就是對應16B的那個節點
int d = maxOrder 是將11賦值給d, 也就是在內存樹的第11層取節點, 這部分上一小節剖析過了, 可以回顧圖5-8-5部分
int id = allocateNode(d) 這里獲取的是上一小節我們分析過的, 字節數組memoryMap的下標, 這里指向一個page, 如果第一次分配, 指向的是0-8k的那個page, 上一小節對此進行詳細的剖析這里不再贅述
final PoolSubpage<T>[] subpages = this.subpages 這一步, 是拿到PoolChunk中成員變量subpages的值, 也是個PoolSubpage的數組, 在PoolChunk進行初始化的時候, 也會初始化該數組, 長度為2048
也就是說每個chunk都維護著一個subpage的列表, 如果每一個page級別的內存都需要被切分成子page, 則會將這個這個page放入該列表中, 專門用于分配子page, 所以這個列表中的subpage, 其實就是一個用于切分的page
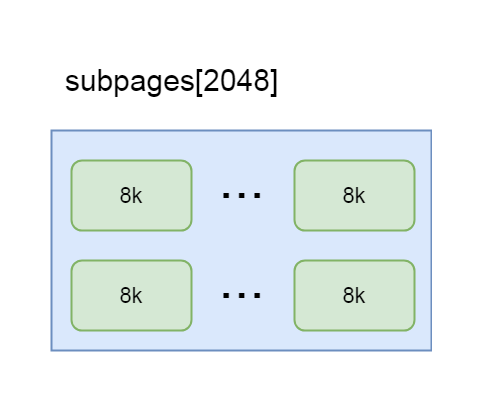
5-8-2
int subpageIdx = subpageIdx(id) 這一步是通過id拿到這個PoolSubpage數組的下標, 如果id對應的page是0-8k的節點, 這里拿到的下標就是0
在 if (subpage == null) 中, 因為默認subpages只是創建一個數組, 并沒有往數組中賦值, 所以第一次走到這里會返回true, 跟到if塊中:
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
這里通過new PoolSubpage創建一個新的subpage之后, 通過 subpages[subpageIdx] = subpage 這種方式將新創建的subpage根據下標賦值到subpages中的元素中
在new PoolSubpage的構造方法中, 傳入head, 就是我們剛才提到過的tinySubpagePools屬性中的節點, 如果我們分配的16字節的緩沖區, 則這里對應的就是第一個節點
PoolSubpage(PoolSubpage<T> head, PoolChunk<T> chunk, int memoryMapIdx, int runOffset, int pageSize, int elemSize) {
this.chunk = chunk;
this.memoryMapIdx = memoryMapIdx;
this.runOffset = runOffset;
this.pageSize = pageSize;
bitmap = new long[pageSize >>> 10];
init(head, elemSize);
}這里重點關注屬性bitmap, 這是一個long類型的數組, 初始大小為8, 這里只是初始化的大小, 真正的大小要根據將page切分多少塊而確定
這里將屬性進行了賦值, 我們跟到init方法中:
void init(PoolSubpage<T> head, int elemSize) {
doNotDestroy = true;
this.elemSize = elemSize;
if (elemSize != 0) {
maxNumElems = numAvail = pageSize / elemSize;
nextAvail = 0;
bitmapLength = maxNumElems >>> 6;
if ((maxNumElems & 63) != 0) {
bitmapLength ++;
}
for (int i = 0; i < bitmapLength; i ++) {
//bitmap標識哪個子page被分配
//0標識未分配, 1表示已分配
bitmap [i] = 0;
}
}
//加到arena里面
addToPool(head);
}this.elemSize = elemSize 表示保存當前分配的緩沖區大小, 這里我們以16字節舉例, 所以這里是16
maxNumElems = numAvail = pageSize / elemSize
這里初始化了兩個屬性maxNumElems, numAvail, 值都為pageSize / elemSize, 表示一個page大小除以分配的緩沖區大小, 也就是表示當前page被劃分了多少分
numAvail則表示剩余可用的塊數, 由于第一次分配都是可用的, 所以 numAvail=maxNumElems
bitmapLength表示bitmap的實際大小, 剛才我們分析過, bitmap初始化的大小為8, 但實際上并不一定需要8個元素, 元素個數要根據page切分的子塊而定, 這里的大小是所切分的子塊數除以64
再往下看, if ((maxNumElems & 63) != 0) 判斷maxNumElems也就是當前配置所切分的子塊是不是64的倍數, 如果不是, 則bitmapLength加1,
最后通過循環, 將其分配的大小中的元素賦值為0
這里詳細介紹一下有關bitmap, 這里是個long類型的數組, long數組中的每一個值, 也就是long類型的數字, 其中的每一個比特位, 都標記著page中每一個子塊的內存是否已分配, 如果比特位是1, 表示該子塊已分配, 如果比特位是0, 表示該子塊未分配, 標記順序是其二進制數從低位到高位進行排列
這里, 我們應該知道為什么bitmap大小要設置為子塊數量除以, 64, 因為long類型的數字是64位, 每一個元素能記錄64個子塊的數量, 這樣就可以通過子page個數除以64的方式決定bitmap中元素的數量
如果子塊不能整除64, 則通過元素數量+1方式, 除以64之后剩余的子塊通過long中比特位由低到高進行排列記錄
這里的邏輯結構如下所示:
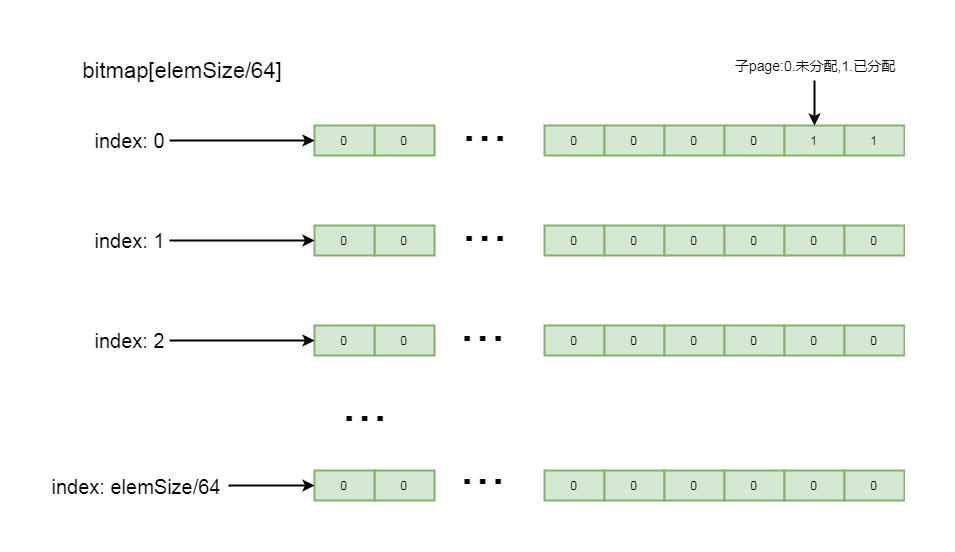
5-8-3
private void addToPool(PoolSubpage<T> head) {
assert prev == null && next == null;
prev = head;
next = head.next;
next.prev = this;
head.next = this;
}這里的head我們剛才講過, 是Arena中數組tinySubpagePools中的元素, 通過以上邏輯, 就會將新創建的Subpage通過雙向鏈表的方式關聯到tinySubpagePools中的元素, 我們以16字節為例, 關聯關系如圖所示:

5-8-4
這樣, 下次如果還需要分配16字節的內存, 就可以通過tinySubpagePools找到其元素關聯的subpage進行分配了
我們再回到PoolChunk的allocateSubpage方法中:
private long allocateSubpage(int normCapacity) {
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
int d = maxOrder;
//表示在第11層分配節點
int id = allocateNode(d);
if (id < 0) {
return id;
}
//獲取初始化的subpage
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
//表示第幾個subpageIdx
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
//如果subpage為空
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
//則將當前的下標賦值為subpage
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
//取出一個子page
return subpage.allocate();
}
}創建完了一個subpage, 我們就可以通過subpage.allocate()方法進行內存分配了
long allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
//取一個bitmap中可用的id(絕對id)
final int bitmapIdx = getNextAvail();
//除以64(bitmap的相對下標)
int q = bitmapIdx >>> 6;
//除以64取余, 其實就是當前絕對id的偏移量
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) == 0;
//當前位標記為1
bitmap[q] |= 1L << r;
//如果可用的子page為0
//可用的子page-1
if (-- numAvail == 0) {
//則移除相關子page
removeFromPool();
}
//bitmapIdx轉換成handler
return toHandle(bitmapIdx);
}這里的邏輯看起來比較復雜, 這里帶著大家一點點剖析:
首先看:
final int bitmapIdx = getNextAvail();
其中bitmapIdx表示從bitmap中找到一個可用的bit位的下標, 注意, 這里是bit的下標, 并不是數組的下標, 我們之前分析過, 因為每一比特位代表一個子塊的內存分配情況, 通過這個下標就可以知道那個比特位是未分配狀態
我們跟進這個方法:
private int getNextAvail() {
//nextAvail=0
int nextAvail = this.nextAvail;
if (nextAvail >= 0) {
//一個子page被釋放之后, 會記錄當前子page的bitmapIdx的位置, 下次分配可以直接通過bitmapIdx拿到一個子page
this.nextAvail = -1;
return nextAvail;
}
return findNextAvail();
}這里nextAvail, 表示下一個可用的bitmapIdx, 在釋放的時候的會被標記, 標記被釋放的子塊對應bitmapIdx的下標, 如果<0則代表沒有被釋放的子塊, 則通過findNextAvail方法進行查找
private int findNextAvail() {
//當前long數組
final long[] bitmap = this.bitmap;
//獲取其長度
final int bitmapLength = this.bitmapLength;
for (int i = 0; i < bitmapLength; i ++) {
//第i個
long bits = bitmap[i];
//!=-1 說明64位沒有全部占滿
if (~bits != 0) {
//找下一個節點
return findNextAvail0(i, bits);
}
}
return -1;
}這里會遍歷bitmap中的每一個元素, 如果當前元素中所有的比特位并沒有全部標記被使用, 則通過findNextAvail0(i, bits)方法挨個往后找標記未使用的比特位
再繼續跟findNextAvail0:
private int findNextAvail0(int i, long bits) {
//多少份
final int maxNumElems = this.maxNumElems;
//乘以64, 代表當前long的第一個下標
final int baseVal = i << 6;
//循環64次(指代當前的下標)
for (int j = 0; j < 64; j ++) {
//第一位為0(如果是2的倍數, 則第一位就是0)
if ((bits & 1) == 0) {
//這里相當于加, 將i*64之后加上j, 獲取絕對下標
int val = baseVal | j;
//小于塊數(不能越界)
if (val < maxNumElems) {
return val;
} else {
break;
}
}
//當前下標不為0
//右移一位
bits >>>= 1;
}
return -1;
}這里從當前元素的第一個比特位開始找, 直到找到一個標記為0的比特位, 并返回當前比特位的下標, 大概流程如下圖所示:
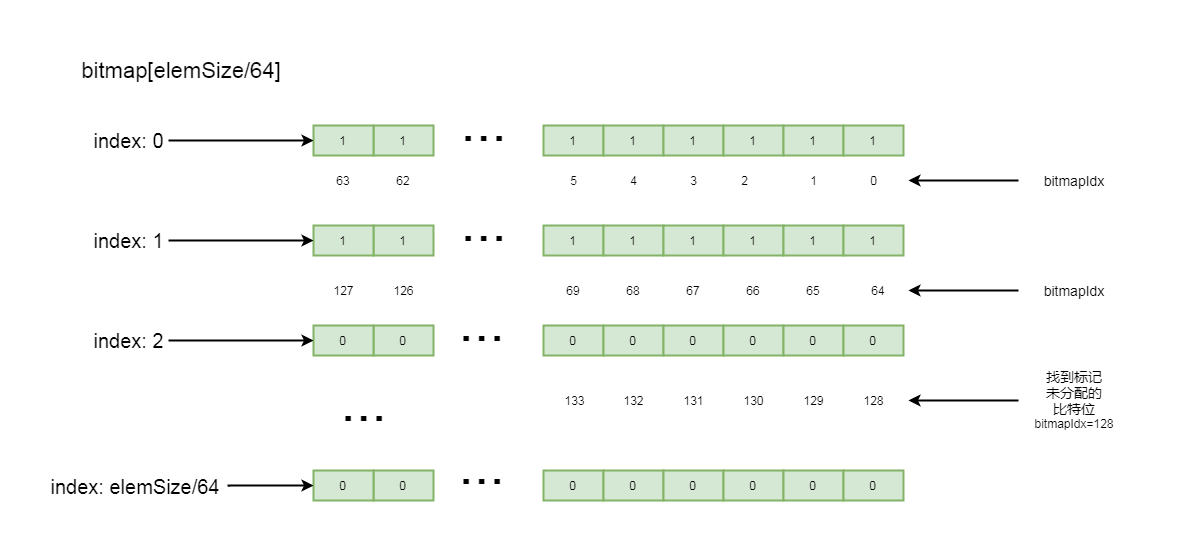
5-8-5
long allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
//取一個bitmap中可用的id(絕對id)
final int bitmapIdx = getNextAvail();
//除以64(bitmap的相對下標)
int q = bitmapIdx >>> 6;
//除以64取余, 其實就是當前絕對id的偏移量
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) == 0;
//當前位標記為1
bitmap[q] |= 1L << r;
//如果可用的子page為0
//可用的子page-1
if (-- numAvail == 0) {
//則移除相關子page
removeFromPool();
}
//bitmapIdx轉換成handler
return toHandle(bitmapIdx);
}找到可用的bitmapIdx之后, 通過 int q = bitmapIdx >>> 6 獲取bitmap中bitmapIdx所屬元素的數組下標
int r = bitmapIdx & 63 表示獲取bitmapIdx的位置是從當前元素最低位開始的第幾個比特位
bitmap[q] |= 1L << r 是將bitmap的位置設置為不可用, 也就是比特位設置為1, 表示已占用
然后將可用子配置的數量numAvail減一
如果沒有可用子page的數量, 則會將PoolArena中的數組tinySubpagePools所關聯的subpage進行移除, 移除之后參考圖5-8-1
最后通過toHandle(bitmapIdx)獲取當前子塊的handle, 上一小節我們知道handle指向的是當前chunk中的唯一的一塊內存, 我們跟進toHandle(bitmapIdx)中:
private long toHandle(int bitmapIdx) {
return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx;
}(long) bitmapIdx << 32 是將bitmapIdx右移32位, 而32位正好是一個int的長度, 這樣, 通過 (long) bitmapIdx << 32 | memoryMapIdx 計算, 就可以將memoryMapIdx, 也就是page所屬的下標的二進制數保存在 (long) bitmapIdx << 32 的低32位中
0x4000000000000000L是一個最高位是1并且所有低位都是0的二進制數, 這樣通過按位或的方式可以將 (long) bitmapIdx << 32 | memoryMapIdx 計算出來的結果保存在0x4000000000000000L的所有低位中, 這樣, 返回對的數字就可以指向chunk中唯一的一塊內存
我們回到PoolArena的allocateNormal方法中:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原來的chunk上進行內存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//創建chunk進行內存分配(2)
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}我們分析完了long handle = c.allocate(normCapacity)這步, 這里返回的handle就指向chunk中的某個page中的某個子塊所對應的連續內存
最后, 通過iniBuf初始化之后, 將創建的chunk加到ChunkList里面
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) {
int memoryMapIdx = memoryMapIdx(handle);
//bitmapIdx是后面分配subpage時候使用到的
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx == 0) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
//runOffset(memoryMapIdx):偏移量
//runLength(memoryMapIdx):當前節點的長度
buf.init(this, handle, runOffset(memoryMapIdx), reqCapacity, runLength(memoryMapIdx),
arena.parent.threadCache());
} else {
initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity);
}
}這部分在之前的小節我們剖析過, 相信大家不會陌生, 這里有區別的是 if (bitmapIdx == 0) 的判斷, 這里的bitmapIdx不會是0, 這樣, 就會走到initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity)方法中
跟到initBufWithSubpage方法:
private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) {
assert bitmapIdx != 0;
int memoryMapIdx = memoryMapIdx(handle);
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage.doNotDestroy;
assert reqCapacity <= subpage.elemSize;
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize, reqCapacity, subpage.elemSize,
arena.parent.threadCache());
}首先拿到memoryMapIdx, 這里會將我們之前計算handle傳入, 跟進去:
private static int memoryMapIdx(long handle) {
return (int) handle;
}這里將其強制轉化為int類型, 也就是去掉高32位, 這樣就得到memoryMapIdx
我們注意在buf調用init方法中的一個參數: runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize
這里的偏移量就是, 原來page的偏移量+子塊的偏移量
bitmapIdx & 0x3FFFFFFF 代表當前分配的子page是屬于第幾個子page
(bitmapIdx & 0x3FFFFFFF) * subpage.elemSize 表示在當前page的偏移量
這樣, 分配的ByteBuf在內存讀寫的時候, 就會根據偏移量進行讀寫
最后我們跟到init方法中
void init(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
//初始化
assert handle >= 0;
assert chunk != null;
//在哪一塊內存上進行分配的
this.chunk = chunk;
//這一塊內存上的哪一塊連續內存
this.handle = handle;
memory = chunk.memory;
//偏移量
this.offset = offset;
this.length = length;
this.maxLength = maxLength;
tmpNioBuf = null;
this.cache = cache;
}關于“Netty分布式ByteBuf使用subPage級別內存分配的方法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





