溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python Pandas數據結構的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
2008年WesMcKinney開發出的庫
專門用于數據挖掘的開源python庫
以Numpy為基礎,借力Numpy模塊在計算方面性能高的優勢
基于matplotlib,能夠簡便的畫圖
獨特的數據結構
Numpy已經能夠幫助我們處理數據,能夠結合matplotlib解決部分數據展示等問題,那么pandas學習的目的在什么地方呢?
增強圖表可讀性
便捷的數據處理能力
讀取文件方便
封裝了Matplotlib、Numpy的畫圖和計算
Pandas中一共有三種數據結構,分別為:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一維數據結構,DataFrame是二維的表格型數據結構,MultiIndex是三維的數據結構。
Series是一個類似于一維數組的數據結構,它能夠保存任何類型的數據,比如整數、字符串、浮點數等,主要由一組數據和與之相關的索引兩部分構成。
2.1.1 Series的創建
# 導入pandas import pandas as pd pd.Series(data=None, index=None, dtype=None)
參數:
data:傳入的數據,可以是ndarray、list等
index:索引,必須是唯一的,且與數據的長度相等。如果沒有傳入索引參數,則默認會自動創建一個從0-N的整數索引。
dtype:數據的類型
指定索引創建:
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
通過字典數據創建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count2.1.2 Series的屬性
為了更方便地操作Series對象中的索引和數據,Series中提供了兩個屬性index和values
1.index
color_count.index # 結果 Index(['blue', 'green', 'red', 'yellow'], dtype='object')
2.values
color_count.values # 結果 array([ 200, 500, 100, 1000])
當然也可以使用索引來獲取數據:
color_count[2] # 結果 100
DataFrame是一個類似于二維數組或表格(如excel)的對象,既有行索引,又有列索引。
行索引,表明不同行,橫向索引,叫index,0軸,axis=0
列索引,表名不同列,縱向索引,叫columns,1軸,axis=1
2.2.1 DataFrame的創建
# 導入pandas import pandas as pd pd.DataFrame(data=None, index=None, columns=None)
參數:
index:行標簽。如果沒有傳入索引參數,則默認會自動創建一個從0-N的整數索引。
columns:列標簽。如果沒有傳入索引參數,則默認會自動創建一個從0-N的整數索引。
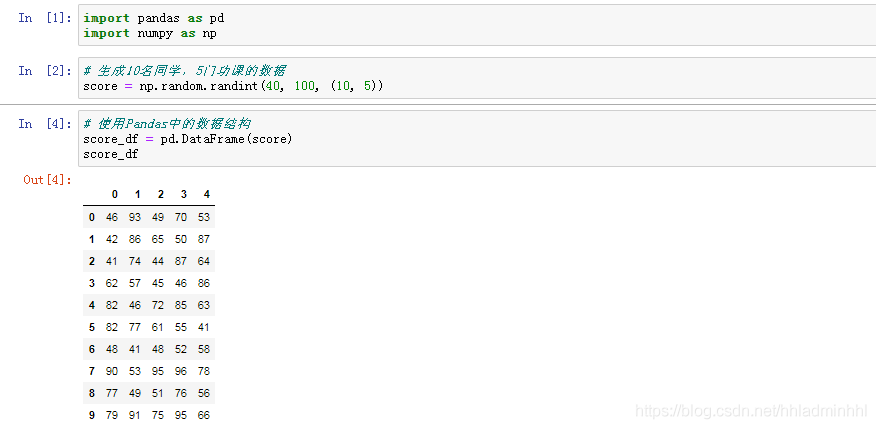
舉例:創建學生成績表
# 生成10名同學,5門功課的數據 score = np.random.randint(40, 100, (10, 5)) # 結果 array([[46, 93, 49, 70, 53], [42, 86, 65, 50, 87], [41, 74, 44, 87, 64], [62, 57, 45, 46, 86], [82, 46, 72, 85, 63], [82, 77, 61, 55, 41], [48, 41, 48, 52, 58], [90, 53, 95, 96, 78], [77, 49, 51, 76, 56], [79, 91, 75, 95, 66]])
但是這樣的數據形式很難看到存儲的是什么的樣的數據,可讀性比較差!!
問題:如何讓數據更有意義的顯示?
# 使用Pandas中的數據結構 score_df = pd.DataFrame(score)
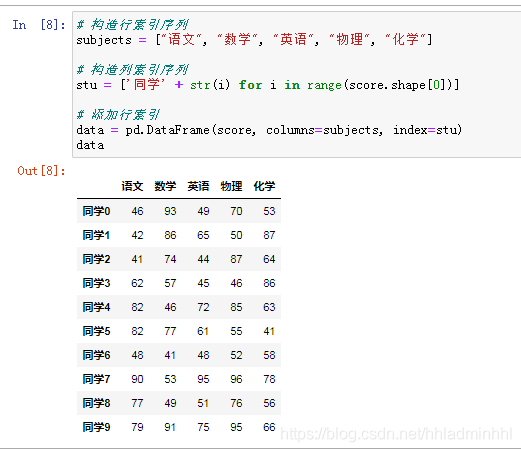
增加行、列索引:
# 構造行索引序列 subjects = ["語文", "數學", "英語", "物理", "化學"] # 構造列索引序列 stu = ['同學' + str(i) for i in range(score.shape[0])] # 添加行索引 data = pd.DataFrame(score, columns=subjects, index=stu)
2.2.2 DataFrame的屬性
1.shape
data.shape # 結果 (10, 5)
2.index
DataFrame的行索引列表
data.index # 結果 Index(['同學0', '同學1', '同學2', '同學3', '同學4', '同學5', '同學6', '同學7', '同學8', '同學9'], dtype='object')
3.columns
DataFrame的列索引列表
data.columns # 結果 Index(['語文', '數學', '英語', '政治', '體育'], dtype='object')
4.values
直接獲取其中array的值
data.values array([[46, 93, 49, 70, 53], [42, 86, 65, 50, 87], [41, 74, 44, 87, 64], [62, 57, 45, 46, 86], [82, 46, 72, 85, 63], [82, 77, 61, 55, 41], [48, 41, 48, 52, 58], [90, 53, 95, 96, 78], [77, 49, 51, 76, 56], [79, 91, 75, 95, 66]])
5.T
轉置
data.T
輸出結果:
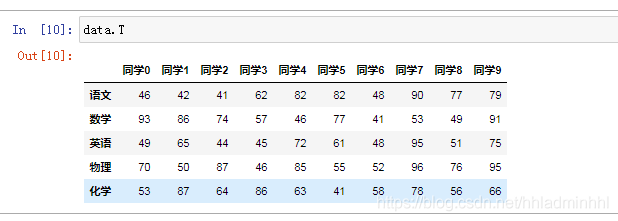
6.head(5):顯示前5行內容 (很常用)
如果不補充參數,默認5行。填入參數N則顯示前N行
data.head(5)
7.tail(5):顯示后5行內容
如果不補充參數,默認5行。填入參數N則顯示后N行
data.tail(5)
2.2.3 DatatFrame索引的設置
1.修改行列索引值
stu = ["學生_" + str(i) for i in range(score_df.shape[0])] # 必須整體全部修改 data.index = stu
注意:以下修改方式是錯誤的
# 錯誤修改方式 data.index[3] = '學生_3' # 錯誤
2.重設索引
reset_index(drop=False)
設置新的下標索引
drop:默認為False,不刪除原來索引,如果為True,刪除原來的索引值
# 重置索引,drop=False data.reset_index()
3.以某列值設置為新的索引
set_index(keys, drop=True)
keys : 列索引名成或者列索引名稱的列表
drop : boolean, default True.當做新的索引,刪除原來的列
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
df = df.set_index(['year', 'month'])注:通過剛才的設置,這樣DataFrame就變成了一個具有MultiIndex的DataFrame。
關于“Python Pandas數據結構的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





