溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Mysql索引底層及優化方法是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。

索引用于快速找出在某個列中有一特定值的行,不使用索引,MySQL必須從第一條記錄開始讀完整個表,直到找出相關的行,表越大,查詢數據所花費的時間就越多,如果表中查詢的列有一個索引,MySQL能夠快速到達一個位置去搜索數據文件,而不必查看所有數據,那么將會節省很大一部分時間。
1. 哈希表是一種以鍵 - 值(key-value)存儲數據的結構,我們只要輸入待查找的鍵即 key,就可以找到其對應的值即 Value。哈希的思路很簡單,把值放在數組里,用一個哈希函數把 key 換算成一個確定的位置,然后把 value 放在數組的這個位置。
不可避免地,多個 key 值經過哈希函數的換算,會出現同一個值的情況。處理這種情況的一種方法是,拉出一個鏈表。
2. 說到bTree,就不得不提二叉樹,二叉樹分為很多,例:二叉查找樹,平衡二叉樹等。當然還有重點紅黑樹。
1) 二叉查找樹的特點是: 父節點左子樹所有節點的值小于父節點的值。右子樹所有節點的值大于父節點的值。 下面以一張圖為例來體現二叉查找樹。
| ID | name |
|---|---|
| 5 | 張五 |
| 6 | 張六 |
| 7 | 張七 |
| 2 | 張二 |
| 1 | 張一 |
| 4 | 張四 |
| 3 | 張三 |
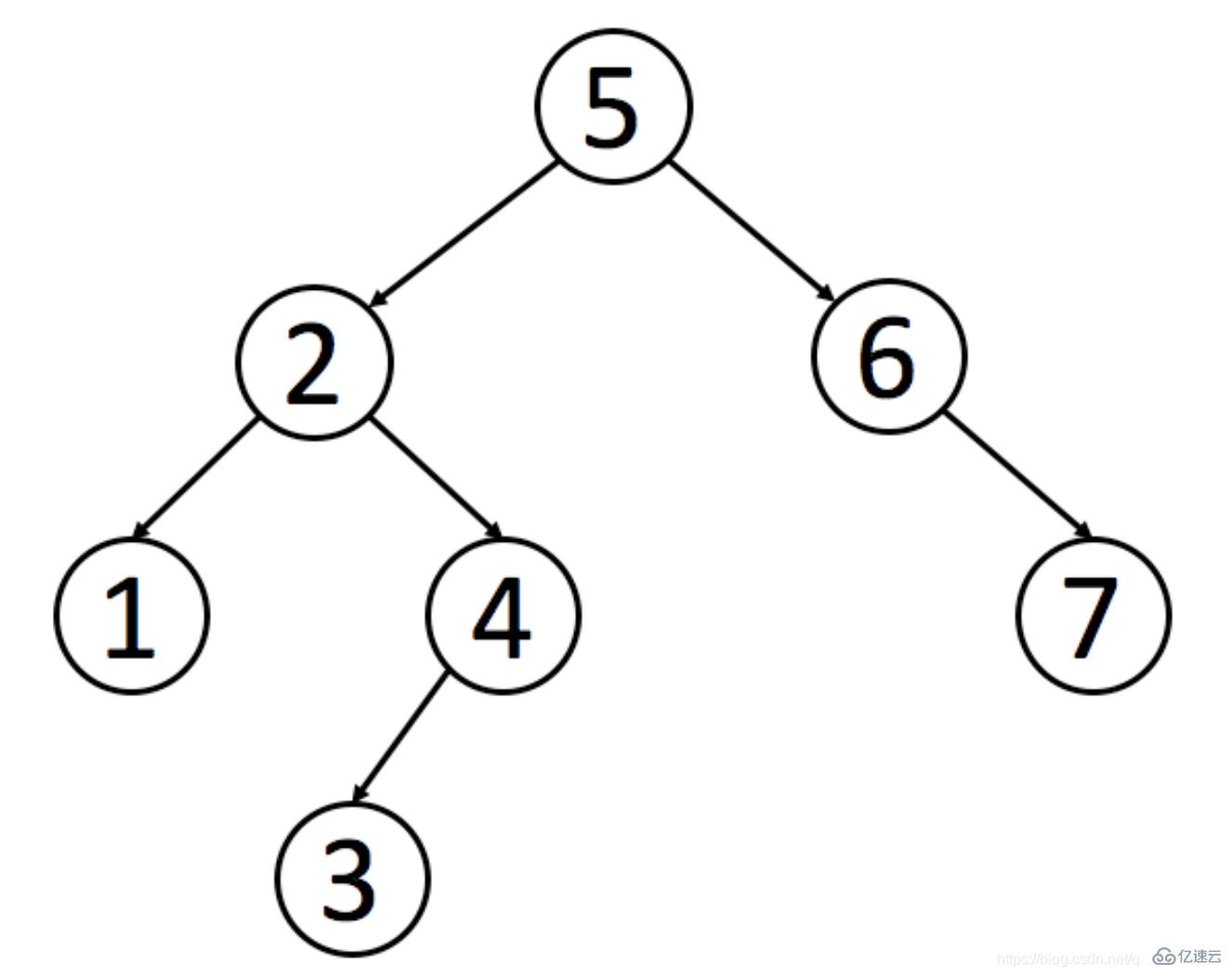 有一個需求,查找張三,如果不使用二叉查找樹那么我們需要查找7次,使用二叉查找樹我們只需要查找4次就可以找到我們想要的值。
有一個需求,查找張三,如果不使用二叉查找樹那么我們需要查找7次,使用二叉查找樹我們只需要查找4次就可以找到我們想要的值。
根據上面說的使用二叉查找樹的確可以減少查詢次數,但是大家有沒有想過,如果數據庫的數據是 1,2,3,4,5,6,7這樣依次遞增的數據呢,繼續使用二叉查找樹就會變成一個鏈表了。那這樣如果我們想要查找7那么需要查找7次,掃描表也是需要7次。這樣跟沒有建立索引沒有區別,這也是弊端之一。下圖為例說明。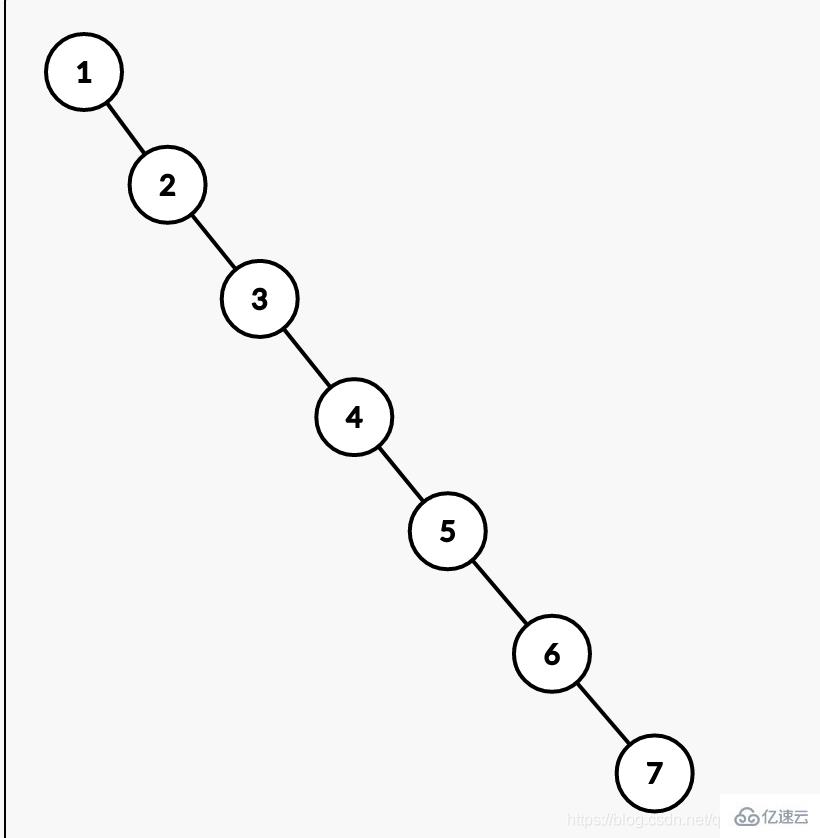
2) 平衡二叉樹:又被稱為AVL樹,它的左右兩個子樹的高度差的絕對值不超過1,并且左右兩個子樹都是一棵平衡二叉樹,AVL樹是最早發明的自平衡二叉查找樹。在AVL樹中,任何節點的兩個子樹的高度最大差別只能為1,所以它又被稱為高度平衡樹。查詢、增加和刪除在平均和最壞情況下都是O(log n)。增加和刪除會需要通過一次或多次樹旋轉來重新平衡這個樹。
我們引入二叉樹的目的是為了提高二叉樹的搜索的效率,從而減少樹的平均搜索長度,為此,就必須在每顆二叉樹插入一個結點時調整樹的結構,讓二叉樹搜索能夠保持平衡,從而可能降低樹的高度,減少的平均樹的搜索長度。
平衡二叉樹特點如下:
1.它的左子樹和右子樹都是AVL樹
2.左子樹和右子樹的高度差不能超過1
例圖: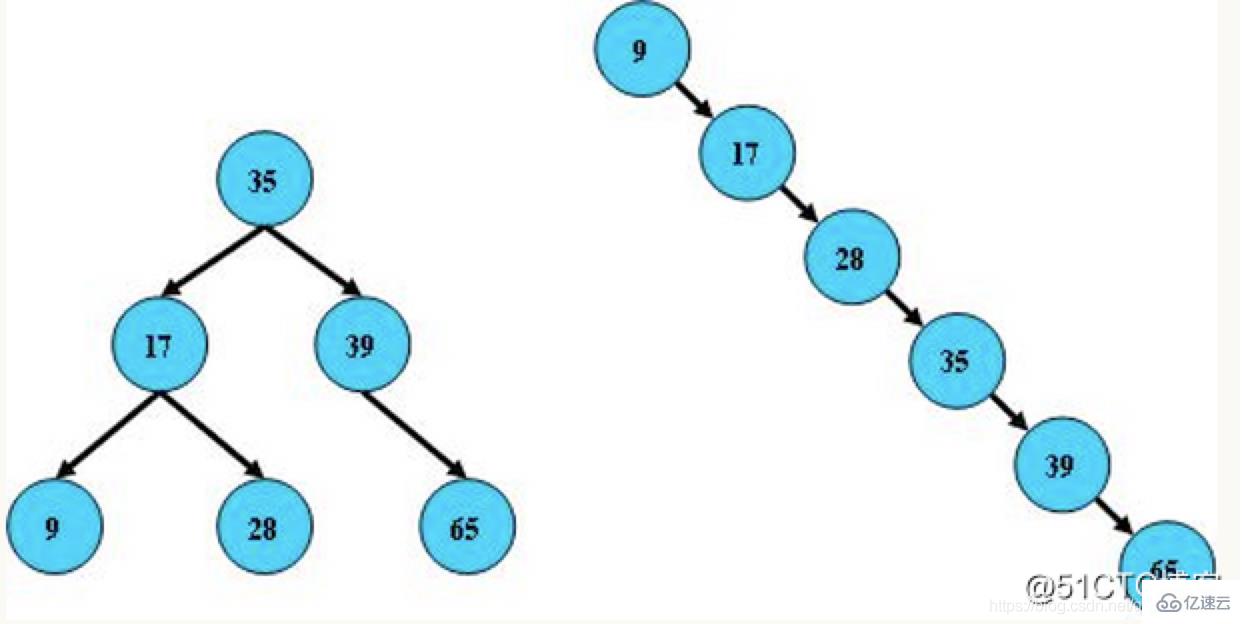 3) 紅黑樹:可以理解為紅黑樹是凌駕于平衡二叉樹之上的一棵樹,紅黑樹不會追求“完全平衡 ”,它只會求部分達到平衡要求,降低了對旋轉的要求,從而提高性能。此外,由于它的設計,所有不平衡都能夠在三次旋轉之內解決。在紅黑樹中,它的算法時間復雜度與AVL相同,并且統計性能會逼AVL樹更高。所以紅黑樹相對于平衡二叉樹來說,不是嚴格意義上的平衡二叉樹,紅黑樹插入和刪除效率更高一些,查詢的效率比平衡二叉樹來說相對低一些,但是二者查詢效率差值做對比,基本可以忽略不計。紅黑樹特點如下:
3) 紅黑樹:可以理解為紅黑樹是凌駕于平衡二叉樹之上的一棵樹,紅黑樹不會追求“完全平衡 ”,它只會求部分達到平衡要求,降低了對旋轉的要求,從而提高性能。此外,由于它的設計,所有不平衡都能夠在三次旋轉之內解決。在紅黑樹中,它的算法時間復雜度與AVL相同,并且統計性能會逼AVL樹更高。所以紅黑樹相對于平衡二叉樹來說,不是嚴格意義上的平衡二叉樹,紅黑樹插入和刪除效率更高一些,查詢的效率比平衡二叉樹來說相對低一些,但是二者查詢效率差值做對比,基本可以忽略不計。紅黑樹特點如下:
1. 節點是紅色或黑色。
2. 根節點是黑色。
3. 每個紅色節點的兩個子節點都是黑色。(紅色節點的子節點必須是黑色節點)
4. 從任一節點到其每個葉子的所有路徑都包含相同數目的黑色節點。
故紅黑樹是黑色平衡的樹,左子樹與右子樹高度差不會超過2。紅節點的父節點、子節點只能是黑節點。
例圖: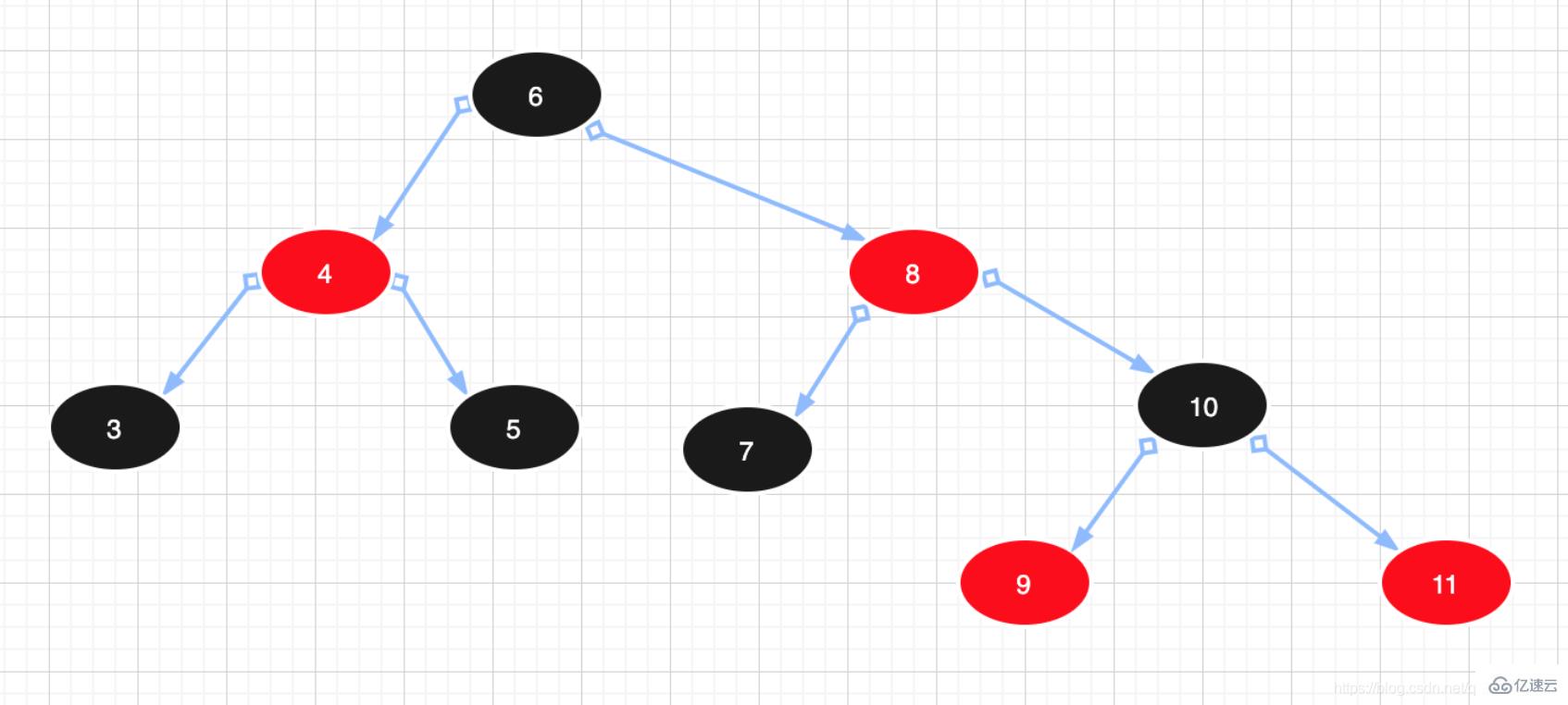
4) BTree(B樹):當然上面說到了紅黑樹,性能非常高。以上圖為例,樹的高度最高才為4,共9條數據,但是對于Mysql數據庫,動則幾百萬條數據,幾千萬條數據,那樹的高度就不可估量了,比如說上百萬條數據需要經過30-50次磁盤IO才能查詢到數據,甚至更多的次數,顯然不能滿足Mysql索引高效的查詢效率。那如果我們控制樹的高度呢,那這樣就會極大減少了請求磁盤IO的請求次數,如果高度控制在4,那只需要經過4次磁盤IO就可以查詢到數據。
但是怎么樣控制樹的高度呢,紅黑樹是每個節點只存儲一個元素,如果每個節點存多個元素呢,這樣就可以解決高度問題了,肯定有同學有疑問,把所有的元素都放到一個節點上,那高度值就是1了,不是更快嗎?這樣想肯定是錯的,Mysql每一次跟磁盤IO打交道是有大小限制的,Mysql限制每一個節點的大小是16K。 想查看自己Mysql限制節點大小的同學可以執行下面的sql。
show global status like ‘Innodb_page_size’
下面以圖為例體現BTree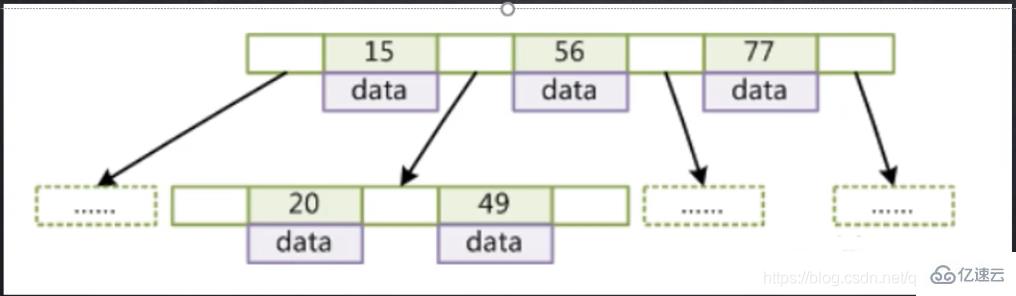 BTree特點如下:
BTree特點如下:
1.所有索引元素不重復
2.節點的數據索引從左到右依次遞增
3.葉節點具有相同的深度,葉節點的指針為空
4.葉子節點和非葉子結點都存儲索引和數據
5) B+樹:上面說到了BTree控制了樹的高度的問題,可以滿足Mysql對于索引的需求,但是最終Mysq索引實現不是BTree而是B+樹,Mysql對B樹做了一點點改造,得到了B+樹,也可以理解為B+樹是B樹的升級版。
下面以圖為例說明:
從這張圖可以看到,我們的非葉子節點只存儲了索引并沒有存儲data,而且葉子節點間用指針相連。B樹的葉子節點和非葉子節點都存儲了索引和數據,而且葉子結點的指針為空,B+樹把數據放在了葉子節點上,這樣非葉子節點就可以存放更多的索引,每次從磁盤IO也能獲取更多的索引。
B+樹特點如下:
1.非葉子節點不存儲data,只存儲索引(冗余)和下層指針,可以放更多的索引
2.葉子節點包含所有索引字段,和數據
3.葉子節點用雙指針連接,提高區間訪問的性能
在百度上和很多博客上畫的B+樹是錯誤的哦,一定要避坑哦。
有興趣看Mysql官方對B+樹的解釋的可以去看看。
鏈接: Mysql官網.
1.按照索引的存儲關聯分類:分為兩大類
1.)聚集索義(聚簇索引):葉節點包含了完整的數據記錄,不需要回表。
2.)非聚集索引:需要回表,二次查樹,影響性能。
1.1) 大家都知道Mysql常用的存儲引擎有兩種MyISAM和InnoDB,但是大家實際了解過兩種存儲引擎底層的數據存儲結構嗎?
下面以圖為例為大家說明: 其中test.myisam表是MyISAM存儲引擎,actor表是InnoDB存儲引擎,可以看到MyISAM存儲引擎有三個文件,分別是frm、MYD、MYI,很容易理解frm-frame的簡稱,存的是表的結構,MYD-MYData存的是數據,MYI-MYIndex存的是索引,索引和數據是分開存儲的,再看InnoDB只有frm、IBD,其中frm一樣也是存的表的結構,IBD文件存的是索引和數據,這點InnoDB和MyISAM不一樣。
其中test.myisam表是MyISAM存儲引擎,actor表是InnoDB存儲引擎,可以看到MyISAM存儲引擎有三個文件,分別是frm、MYD、MYI,很容易理解frm-frame的簡稱,存的是表的結構,MYD-MYData存的是數據,MYI-MYIndex存的是索引,索引和數據是分開存儲的,再看InnoDB只有frm、IBD,其中frm一樣也是存的表的結構,IBD文件存的是索引和數據,這點InnoDB和MyISAM不一樣。
下面以圖為例說明MyISAM存儲引擎主鍵索引是需要回表操作(非聚集索引)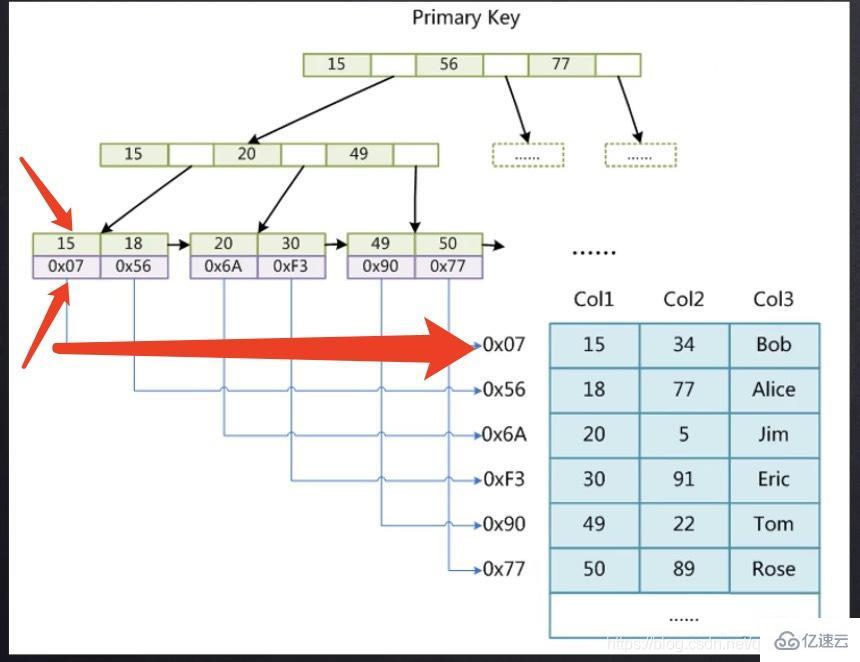 其中15存的是主鍵索引,0x07存的是15所在行記錄的磁盤文件地址指針,比如我們想找到15的數據,那首先應該先通過主鍵索引樹,找到15所對應的指針,然后找到了這個指針再去MyD文件中找具體的數據,需要進行二次查找,這個過程稱為回表操作。
其中15存的是主鍵索引,0x07存的是15所在行記錄的磁盤文件地址指針,比如我們想找到15的數據,那首先應該先通過主鍵索引樹,找到15所對應的指針,然后找到了這個指針再去MyD文件中找具體的數據,需要進行二次查找,這個過程稱為回表操作。
2.1) 下面以圖為例說明InnoDB存儲引擎主鍵索引不需要進行回表操作。(聚集索引)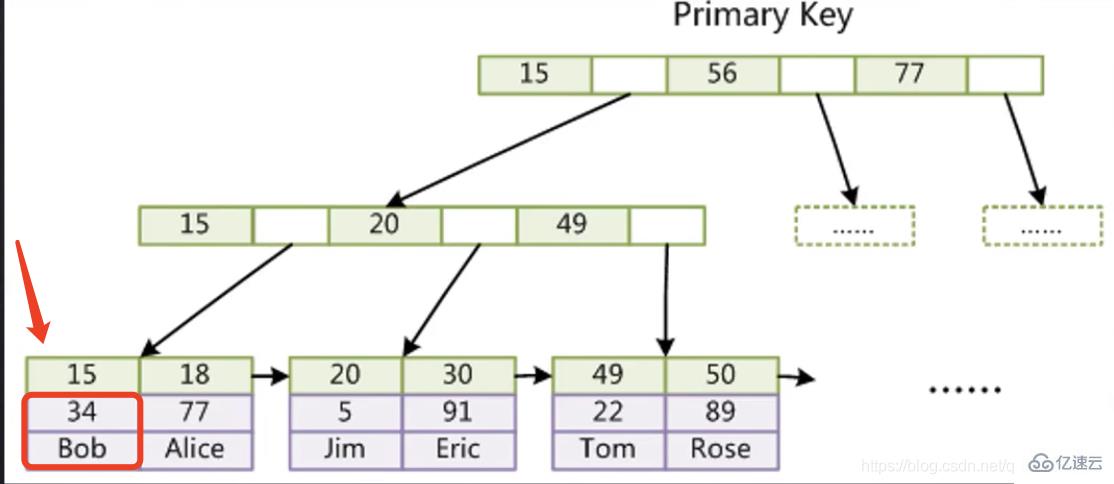 InnoDB存儲引擎子節點首先15那一行存放的是索引,15下面的那一列存放的是索引所在行的其他所有字段,如果我們想要查15的數據,直接就可以找到,不需要在經過二次查樹。
InnoDB存儲引擎子節點首先15那一行存放的是索引,15下面的那一列存放的是索引所在行的其他所有字段,如果我們想要查15的數據,直接就可以找到,不需要在經過二次查樹。
2. 按照功能分類:主要分為五大類
2.1 主鍵索引:InnoDB主鍵索引不需要回表操作
2.2 普通索引(二級索引):InnoDB普通索引需要回表操作,對于二級索引,會默認和主鍵做聯合索引。
2.3 唯一索引
2.4 全文索引
2.5 聯合索引:需要滿足最左前綴原則
3. 在2.2中提到了普通索引需要回表操作,那有沒有不需要回表的普通索引呢,答案是有的,在某個查詢里面,索引已經覆蓋了我們的查詢需求,我們稱為覆蓋索引。這時是不需要回表操作的。
由于覆蓋索引可以減少樹的搜索次數,顯著提升查詢性能,所以使用覆蓋索引是一個常用的性能優化手段。
舉個例子:下面是這個表的初始化語句。
mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'), (300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
在上面這個表 T 中,如果我執行 select * from T where k between 3 and 5,需要執行幾次樹的搜索操作,會掃描多少行?
現在,我們一起來看看這條 SQL 查詢語句的執行流程。看下圖。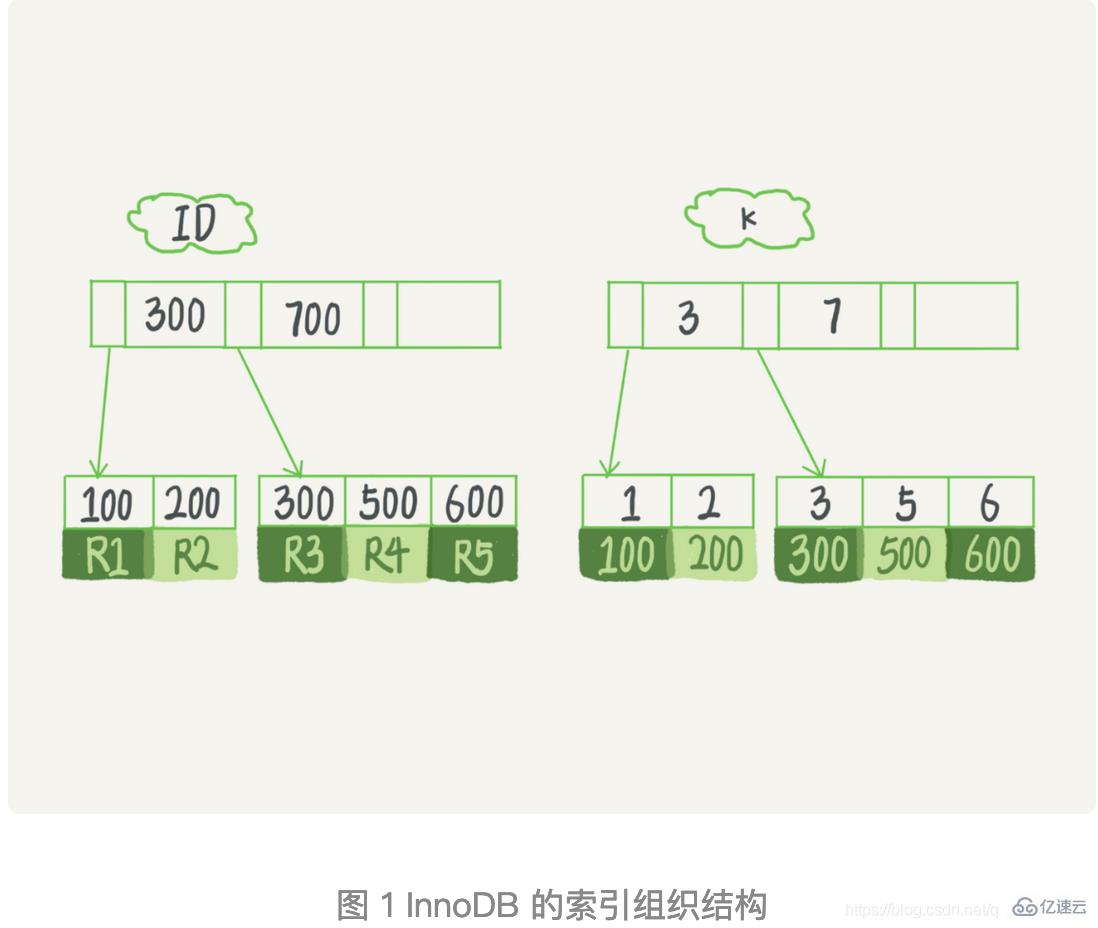
1.) 在 k 索引樹上找到 k=3 的記錄,取得 ID = 300;
2.) 再到 ID 索引樹查到 ID=300 對應的 R3;
3.) 在 k 索引樹取下一個值 k=5,取得 ID=500;
4.) 再回到 ID 索引樹查到 ID=500 對應的 R4;
5.) 在 k 索引樹取下一個值 k=6,不滿足條件,循環結束。
在這個過程中,回到主鍵索引樹搜索的過程,我們稱為回表。可以看到,這個查詢過程讀了 k 索引樹的 3 條記錄(步驟 1、3 和 5),回表了兩次(步驟 2 和 4)。
在這個例子中,由于查詢結果所需要的數據只在主鍵索引上有,所以不得不回表。
如果執行的語句是 select ID from T where k between 3 and 5,這時只需要查 ID 的值,而 ID 的值已經在 k 索引樹上了,因此可以直接提供查詢結果,不需要回表。也就是說,在這個查詢里面,索引 k 已經“覆蓋了”我們的查詢需求,我們稱為覆蓋索引。
在 InnoDB 中,表都是根據主鍵順序以索引的形式存放的,這種存儲方式的表稱為索引組織表。又因為前面我們提到的,InnoDB 使用了 B+ 樹索引模型,所以數據都是存儲在 B+ 樹中的。每一個索引在 InnoDB 里面對應一棵 B+ 樹。
1.) 當組合索引中只要有一列含有null值,索引失效
2.) 在列上做計算索引失效,范圍之后的索引全部失效
3.) 在查詢條件上使用函數會造成索引失效
4.) 在where字句中使用 != 或 <> 操作符,導致索引失效
5.) 避免使用or,導致索引失效
6.) 使用模糊查詢也會造成索引失效,可以用like ‘a%’而不是like ‘%a%’
7.) 盡量使用覆蓋索引,減少 select * 語句
8.) 滿足最左前綴法則,最左前列開始并且不跳過索引中的列
9.) 字符串不加單引號索引失效
新創建一個員工表,有5個屬性,如下。
create table employees(
id int primary key auto_increment comment '主鍵自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年齡',
id_card varchar(40) not null default '' comment '身份證號',
position varchar(40) not null default '' comment '位置'
);
-- 創建聯合索引
create index name_index on employees (name,age,position);
-- 插入一條數據
insert into employees(name,age,id_card,position) values('張三',15,
'201124199011035321','北京');-- 下面以10條sql測試,注意建立的聯合索引順序是 name,age,position 1.explain select * from employees where age=15 and position='北京' and name='張三'; 2.explain select * from employees where name='張三' and age=15 and position='北京'; 3.explain select * from employees where age=15 and name='張三'; 4.explain select * from employees where position='北京' and name='張三'; 5.explain select * from employees where position='北京' and age=15; 6.explain select * from employees where position='北京' and age>15 and name='張三'; 7.explain select * from employees where position='北京'; 8.explain select * from employees where age=15; 9.explain select * from employees where name='張三'; 10.explain select * from employees where name != '張三';
以上10條sql有哪些是索引失效,有哪些是索引沒有失效的呢? 相信同學們已經有了答案,但是答案對不對呢,下面我們一起分析下。 首先說第1條,查詢條件把3個索引全部用上了,但是索引的順序有變化,由name,age,position變成 了age,position,name,想到這里肯定有很多同學給出的答案就是索引失效,但是事實證明這個結果 是錯的,索引生效,肯定有很多同學疑惑,為什么呢,這條sql不滿足最左原則法則呀,這就要涉及到sql 的執行流程了,這里博主簡單說下,sql執行有1個優化器的過程,優化器的作用之一就是索引的選擇優化, 所以優化器幫我們把索引的順序變成正確的了,所以索引生效。 下面是第1條按照索引順序sql和第2條沒有按照索引順序sql的執行結果。 執行結果入下圖:可以發現全部生效。
第1條sql type的值為ref、字節是288 并且ref有3個const,全部生效。

第2條sql type的值為ref、字節是288 并且ref有3個const,全部生效。

想學習sql的執行流程的可以看博主的另一篇關于sql執行流程的文章哦。 有的同學有疑問了,那最左原則沒有用了嗎? 答案:有用的。
現在我們說下第3、4、5條sql 第3條: explain select * from employees where age=15 and name='張三'; sql在執行的時候,優化器替我們把索引的順序優化了,由 age -> name 變成 name -> age,這時 索引是生效的。 第4條: explain select * from employees where position='北京' and name='張三'; 索引順序優化為name - > position,但是這時索引只有name索引生效,position沒有生效,因為我 們建立的索引順序是 name -> age - > position,你會發現跳過了age,索引本質也是一棵樹,少 了一個節點,下面的索引當然不會生效了,這就沒有滿足最左原則法則。 第5條: explain select * from employees where position='北京' and age=15; 這就和第4條sql一樣的道理了,第一個索引都不見了,后面的不可能生效。 執行結果如下:
可以發現第3條sql type的值為ref、字節是126并且ref有2個const,全部生效。

第4條sql只有122字節并且ref只有1個const,只有name索引生效。

第5條sql type的值為all,字節和ref都是空,全部失效。

下面說第6條sql,剩下的sql都是和之前的sql一樣的道理。 explain select * from employees where position='北京' and age>15 and name='張三'; 這條sql我們會發現,把索引字段全部使用了并且當作條件查詢,不一樣的是age是范圍查找,優化器替我 們把索引順序優化成 name -> age - > position ,按照我們索引優化第2條:在列上做計算索引失效,范圍之后的索引全部失效,想必答案同學們都知道了。 執行結果如下:
第6條sql只有126字節并且type的值為range,范圍查找,只有name和age索引生效。

以上就是“Mysql索引底層及優化方法是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





