溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“有哪些好用的Python庫”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“有哪些好用的Python庫”文章吧。

您不一定總是需要編寫 CLI 應用程序,但這樣做可以省不少事。在 FastAPI 取得巨大成功之后,tiangolo 使用了相同的原理為我們帶來了 Typer:一個新的庫,使您可以利用Python 3.6+的類型提示功能來編寫命令行界面。
該設計的確使Typer脫穎而出。除了確保代碼已正確記錄之外,您還可以輕松進行CLI界面的驗證。通過使用類型提示,您可以在Python編輯器(如VS Code)中獲得自動補全功能,這將提高您的生產率。
為了增強其功能,Typer內核是基于Click的,而Click則是眾所周知,并且經過了嚴格的測試。這意味著它可以利用其所有好處,如社區和插件,同時以更少的樣板代碼從簡單開始,并根據需要變得復雜。
Typer文檔確實很有幫助,并且應該成為其他項目的典范。絕對不能錯過!
順著CLI的主題,誰說終端應用程序必須是純白色,或者如果您是真正的黑客,則必須是綠色,是黑色?
是否要在終端輸出中添加顏色和樣式?毫不費力地顯示漂亮的進度條?Markdown?表情符號?Rich可以實現上述所有功能。查看下面示例截圖可以進一步了解:
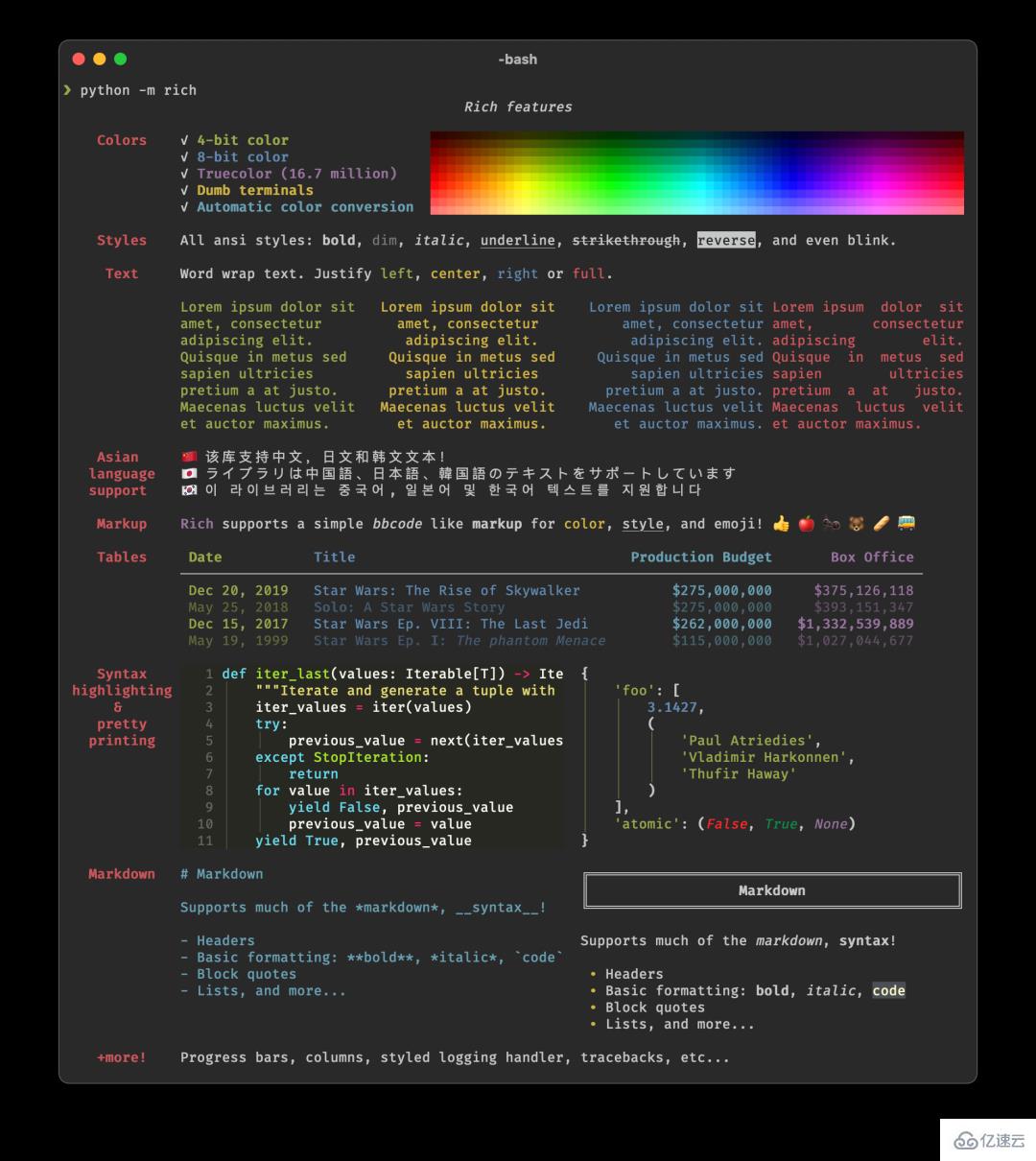
Rich 絕對是一個可以將使用終端應用程序的體驗提升到全新水平的庫。
盡管如我們所見,終端應用程序可以很漂亮,但有時還不夠,您需要一個真正的GUI。
Dear PyGui利用了在視頻游戲中廣為流行的即時模式范例(immediate mode paradigm)。這基本上意味著動態GUI是逐幀獨立繪制的,無需保留任何數據。這使得該工具與其他Python GUI框架有著根本不同。它具有高性能,并使用計算機的GPU來促進高度動態界面的構建,這在工程,仿真,游戲或數據科學應用程序中經常用到。
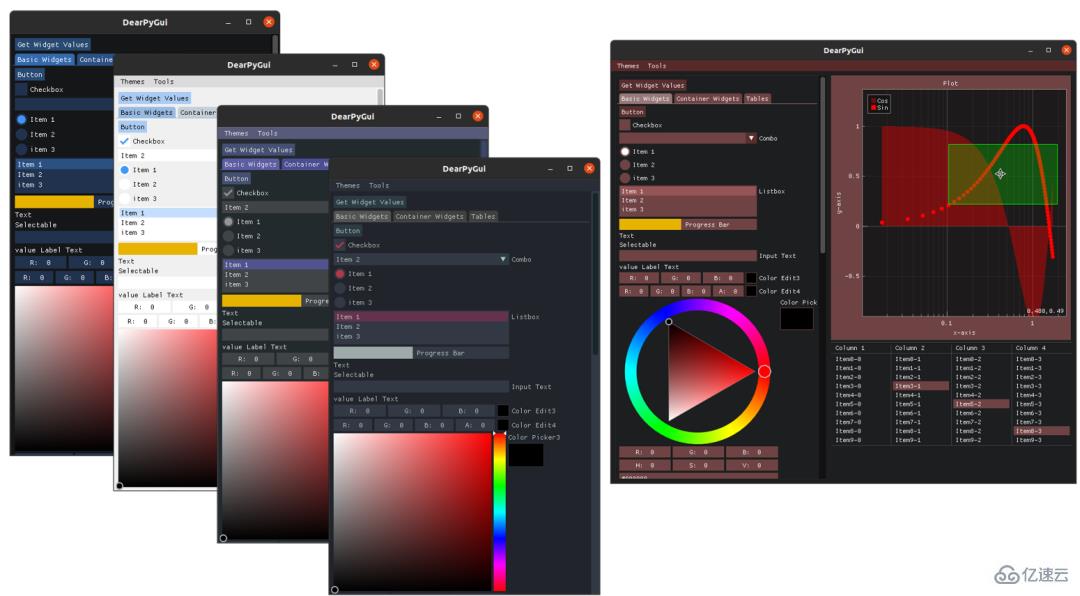
Dear PyGui可以在沒有陡峭的學習曲線的情況下使用,并且可以在Windows 10(DirectX 11),Linux(OpenGL 3)和MacOS(Metal)上運行。
大道至簡,這是一個值得讓您思考的庫:以前沒人想過這是怎么回事?
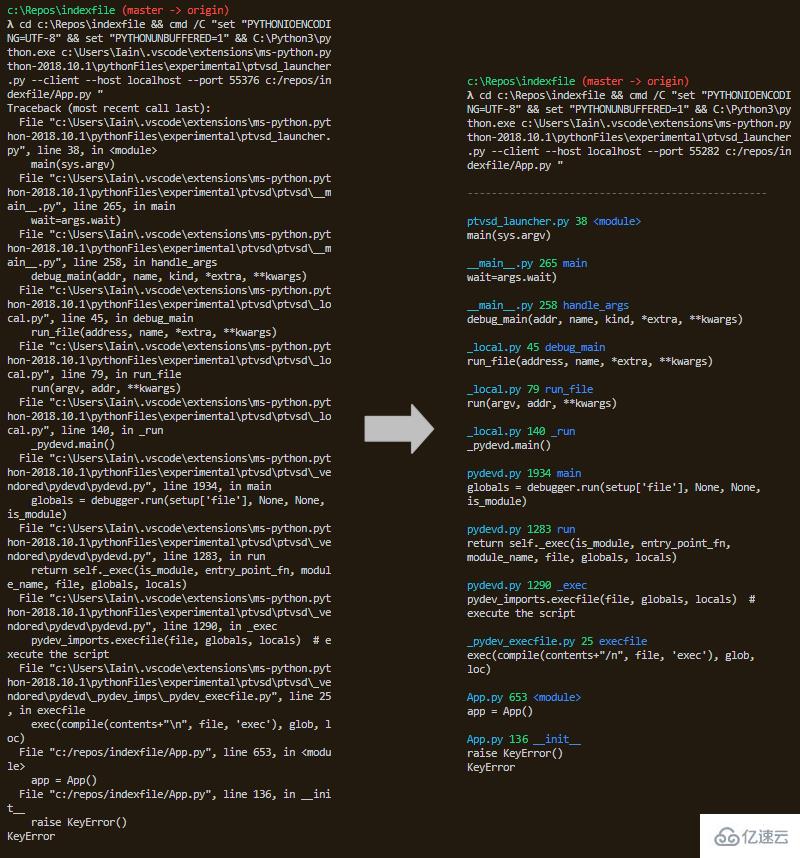
PrettyErrors只做一件事并且做得很好。在支持彩色輸出的終端中,它將隱秘的堆棧軌跡轉換成更適合用微弱的人眼解析的東西。無需再掃描整個屏幕來查找異常的原因……您現在就可以一目了然!
我們程序員喜歡用代碼解決問題。但是有時,我們需要向其他同事解釋復雜的架構設計。傳統上,我們使用GUI工具,在其中我們可以處理圖表和可視化以放入演示文稿和文檔。但這不是唯一的方法。
Diagrams使您無需任何設計工具即可直接在Python代碼中繪制云系統架構。它包含的圖標支持多個云提供商(包括AWS,Azure,GCP)。這使創建箭頭和組非常容易。真的,只有幾行代碼!
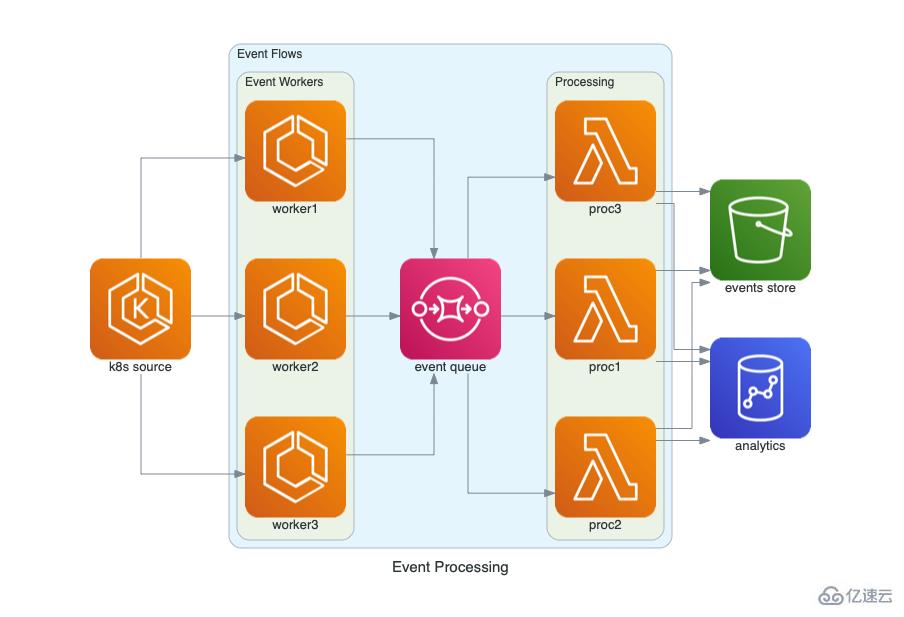
基于代碼的圖表的最好之處是什么?您可以通過git使用版本控制來掌控進度!
在進行機器學習項目的研究和實驗時,總是有無數的設置可以嘗試。在非平凡解的應用程序中,配置管理會變得相當復雜,非常快。有一種結構化的方式來處理這種復雜性不是很好嗎?
Hydra是一種工具,可讓您以可組合的方式構建配置,并從命令行或配置文件覆蓋某些部分。
為了說明可以通過該庫簡化的一些常見任務,假設有一個我們正在嘗試的模型的基本體系結構,以及它的多種變體。使用Hydra,可以定義基本配置,然后運行多個作業,并進行以下更改:
python train_model.py variation=option_a,option_b
├── variation│ ├── option_a.yaml│ └── option_b.yaml├── base.yaml└── train_model.py
Hydra 的表親 OmegaConf 為分層配置系統的基礎提供了一致的API,并支持YAML,配置文件,對象和CLI參數等不同來源。
這是21世紀進行配置管理的必備條件!
每一種提高數據科學團隊生產力的工具都值得鼓勵。沒有理由讓從事數據科學項目的人每次都重新發明輪子,反復思考如何更好地組織其項目中的代碼,使用維護得不好的“ PyTorch 樣板”,或者使用更高級別的抽象功能。
PyTorch Lightning 通過將科學與工程分離而有助于提高生產率。從某種意義上說,它使您的代碼更簡潔,有點像 TensorFlow 的 Keras。但是它仍然是PyTorch,您可以訪問所有常用的API。
該庫可幫助團隊利用圍繞組織的軟件工程的良好實踐和明確的組件職責來構建可輕松擴展,以在多個GPU,TPU和CPU上進行訓練高質量代碼。
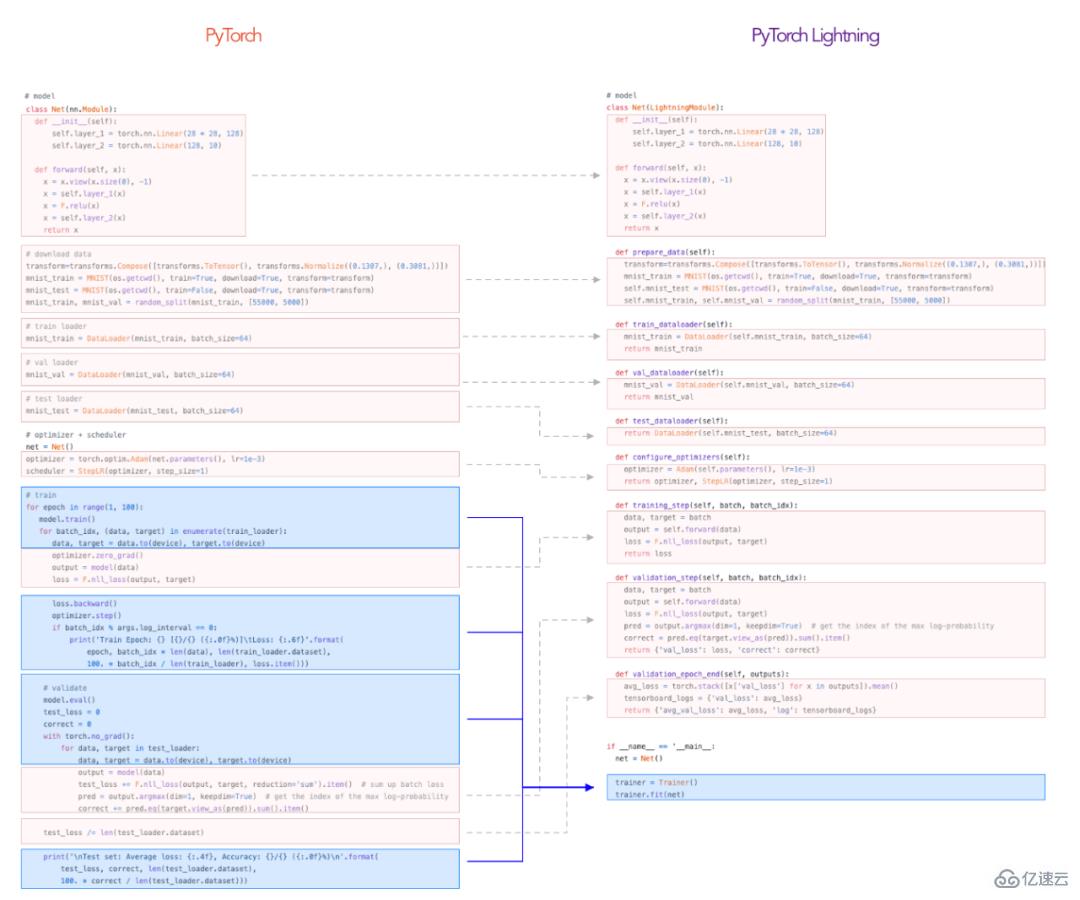
一個可以幫助數據科學團隊的初級成員產生更好結果的庫,但是,由于整體生產力的提高,而且沒有放棄控制權,更有經驗的成員會喜歡它。

并非所有的機器學習都是深度學習。通常,您的模型由scikit-learn中實現的更傳統的算法(例如,Random Forest)組成,或者您使用諸如流行的LightGBM和XGBoost之類的梯度增強方法。
但是,深度學習領域正在發生許多進步。像PyTorch這樣的框架正在以驚人的速度發展,并且硬件設備已經過優化,可以更快地運行張量計算并降低功耗。如果我們可以利用所有這些工作來更快、更高效地運行傳統方法,那豈不是很好嗎?
這是Hummingbird的用武之地。微軟提供的這個新庫可以將訓練有素的傳統ML模型編譯為張量計算。這很棒,因為它使您無需重新設計模型。
到目前為止,Hummingbird支持轉換為PyTorch,TorchScript,ONNX和TVM,以及各種ML模型和矢量化器。推理API也與Sklearn范例非常相似,可讓您重用現有代碼,但將實現更改為Hummingbird生成的代碼。這是一個值得關注的工具,因為它獲得了對模式模型和格式的支持!
幾乎每個數據科學家在職業生涯中的某個時候都曾處理過高維數據。不幸的是,人腦沒有足夠的連線直觀地處理這種數據,因此我們必須訴諸其他技術。
今年初,Facebook發布了HiPlot,這是一個庫,可使用并行繪圖和其他圖形方式來表示信息,從而幫助發現高維數據中的相關性和模式。該概念已在其發布博客文章中進行了解釋,但基本上,它是一種可視化和過濾高維數據的好方法。

HiPlot具有交互性,可擴展性,您可以從標準Jupyter筆記本電腦或通過其自己的服務器使用它。
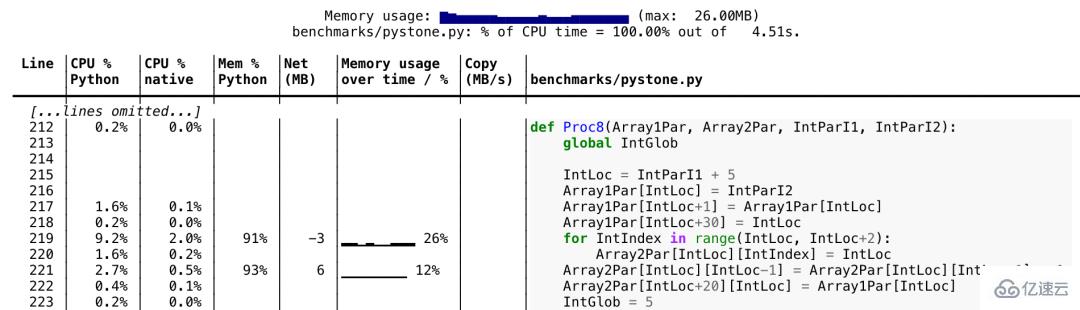
隨著Python庫生態系統變得越來越復雜,我們發現自己正在編寫越來越多的依賴C擴展和多線程的代碼。在衡量性能時,這成為一個問題,因為CPython內置的探查器無法正確處理多線程和本機代碼。
那就是Scalene進行救援的時候。Scalene是用于Python腳本的CPU和內存探查器,能夠正確處理多線程代碼并區分運行Python和本機代碼所花費的時間。無需修改代碼,只需要在命令行中使用scalene運行腳本,腳本就會為您生成文本或HTML報告,顯示代碼每一行的CPU和內存使用情況。
以上就是關于“有哪些好用的Python庫”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





