溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“PyTorch零基礎入門之有哪些構建模型基礎”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
PyTorch中神經網絡構造一般是基于 Module 類的模型來完成的,它讓模型構造更加靈活。Module 類是 nn 模塊里提供的一個模型構造類,是所有神經網絡模塊的基類,我們可以繼承它來定義我們想要的模型。
下面繼承 Module 類構造多層感知機。這里定義的 MLP 類重載了 Module 類的 init 函數和 forward 函數。它們分別用于創建模型參數和定義前向計算。前向計算也即正向傳播。
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 09:43:21 2021
@author: 86493
"""
import torch
from torch import nn
class MLP(nn.Module):
# 聲明帶有模型參數的層,此處聲明了2個全連接層
def __init__(self, **kwargs):
# 調用MLP父類Block的構造函數來進行必要的初始化
# 這樣在構造實例時還可以指定其他函數
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256, 10)
# 定義模型的前向計算
# 即如何根據輸入x計算返回所需要的模型輸出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
X = torch.rand(2, 784)
net = MLP()
print(net)
print('-' * 60)
print(net(X))結果為:
MLP(
(hidden): Linear(in_features=784, out_features=256, bias=True)
(act): ReLU()
(output): Linear(in_features=256, out_features=10, bias=True)
)
------------------------------------------------------------
tensor([[ 0.1836, 0.1946, 0.0924, -0.1163, -0.2914, -0.1103, -0.0839, -0.1274,
0.1618, -0.0601],
[ 0.0738, 0.2369, 0.0225, -0.1514, -0.3787, -0.0551, -0.0836, -0.0496,
0.1481, 0.0139]], grad_fn=<AddmmBackward>)
注意:
(1)上面的MLP類不需要定義反向傳播函數,系統將通過自動求梯度而自動生成反向傳播所需的backward函數。
(2)將數據X傳入實例化MLP類后得到的net對象,會做一次前向計算,并且net(X)會調用MLP類繼承自父類Module的call函數——該函數調用我們定義的子類MLP的forward函數完成前向傳播計算。
(3)這里沒將Module類命名為Layer(層)或者Model(模型)等,是因為該類是一個可供自由組建的部件, 它的子類既可以是一個層(如繼承父類nn的子類線性層Linear),也可以是一個模型(如此處的子類MLP),也可以是模型的一部分。
有全連接層、卷積層、池化層與循環層等,下面學習使用Module定義層。
下面構造的 MyLayer 類通過繼承 Module 類自定義了一個將輸入減掉均值后輸出的層,并將層的計算定義在了 forward 函數里。這個層里不含模型參數。
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 10:19:59 2021 @author: 86493 """ import torch from torch import nn class MyLayer(nn.Module): def __init__(self, **kwargs): # 調用父類的方法 super(MyLayer, self).__init__(**kwargs) def forward(self, x): return x - x.mean() # 測試,實例化該層,做前向計算 layer = MyLayer() layer1 = layer(torch.tensor([1, 2, 3, 4, 5], dtype = torch.float)) print(layer1)
結果為:
tensor([-2., -1., 0., 1., 2.])
可以自定義含模型參數的自定義層。其中的模型參數可以通過訓練學出。
Parameter 類其實是 Tensor 的子類,如果一個 Tensor 是 Parameter ,那么它會自動被添加到模型的參數列表里。所以在自定義含模型參數的層時,我們應該將參數定義成 Parameter ,除了直接定義成 Parameter 類外,還可以使用 ParameterList 和 ParameterDict 分別定義參數的列表和字典。
PS:下面出現torch.mm是將兩個矩陣相乘,如
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 10:56:03 2021 @author: 86493 """ import torch a = torch.randn(2, 3) b = torch.randn(3, 2) print(torch.mm(a, b)) # 效果相同 print(torch.matmul(a, b)) #tensor([[1.8368, 0.4065], # [2.7972, 2.3096]]) #tensor([[1.8368, 0.4065], # [2.7972, 2.3096]])
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 10:33:04 2021 @author: 86493 """ import torch from torch import nn class MyListDense(nn.Module): def __init__(self): super(MyListDense, self).__init__() # 3個randn的意思 self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)]) self.params.append(nn.Parameter(torch.randn(4, 1))) def forward(self, x): for i in range(len(self.params)): # mm是指矩陣相乘 x = torch.mm(x, self.params[i]) return x net = MyListDense() print(net)
打印得:
MyListDense(
(params): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 4x4]
(1): Parameter containing: [torch.FloatTensor of size 4x4]
(2): Parameter containing: [torch.FloatTensor of size 4x4]
(3): Parameter containing: [torch.FloatTensor of size 4x1]
)
)
這回用變量字典:
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 11:03:29 2021
@author: 86493
"""
import torch
from torch import nn
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
# 新增
self.params.update({'linear3':
nn.Parameter(torch.randn(4, 2))})
def forward(self, x, choice = 'linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net)打印得:
MyDictDense(
(params): ParameterDict(
(linear1): Parameter containing: [torch.FloatTensor of size 4x4]
(linear2): Parameter containing: [torch.FloatTensor of size 4x1]
(linear3): Parameter containing: [torch.FloatTensor of size 4x2]
)
)
二維卷積層將輸入和卷積核做互相關運算,并加上一個標量偏差來得到輸出。卷積層的模型參數包括了卷積核和標量偏差。在訓練模型的時候,通常我們先對卷積核隨機初始化,然后不斷迭代卷積核和偏差。
卷積窗口形狀為 p × q p \times q p×q 的卷積層稱為 p × q p \times q p×q 卷積層。同樣, p × q p \times q p×q 卷積或 p × q p \times q p×q 卷積核說明卷積核的高和寬分別為 p p p 和 q q q。
(1)填充可以增加輸出的高和寬。這常用來使輸出與輸入具有相同的高和寬。
(2)步幅可以減小輸出的高和寬,例如輸出的高和寬僅為輸?入的高和寬的 ( 為大于1的整數)。
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 11:20:57 2021 @author: 86493 """ import torch from torch import nn # 卷積運算(二維互相關) def corr2d(X, K): h, w = K.shape X, K = X.float(), K.float() Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): Y[i, j] = (x[i: i + h, j: j + w] * K).sum() return Y # 二維卷積層 class Conv2D(nn.Module): def __init__(self, kernel_size): super(Conv2D, self).__init__() self.weight = nn.Parameter(torch.randn(kernel_size)) self.bias = nn.Parameter(torch.randn(1)) def forward(self, x): return corr2d(x, self.weight) + self.bias conv2d = nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = 3, padding = 1) print(conv2d)
得:
Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
填充(padding)是指在輸入高和寬的兩側填充元素(通常是0元素)。
下個栗子:創建一個高和寬為3的二維卷積層,設輸入高和寬兩側的填充數分別為1。給定一高和寬都為8的input,輸出的高和寬會也是8。
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 11:54:29 2021 @author: 86493 """ import torch from torch import nn # 定義一個函數計算卷積層 # 對輸入和輸出左對應的升維和降維 def comp_conv2d(conv2d, X): # (1, 1)代表批量大小和通道數 X = X.view((1, 1) + X.shape) Y = conv2d(X) # 排除不關心的前2維:批量和通道 return Y.view(Y.shape[2:]) # 注意這里是兩側分別填充1行或列,所以在兩側共填充2行或列 conv2d = nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = 3, padding = 1) X = torch.rand(8, 8) endshape = comp_conv2d(conv2d, X).shape print(endshape) # 使用高為5,寬為3的卷積核,在高和寬兩側填充數為2和1 conv2d = nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = (5, 3), padding = (2, 1)) endshape2 = comp_conv2d(conv2d, X).shape print(endshape2)
結果為:
torch.Size([8, 8])
torch.Size([8, 8])
在二維互相關運算中,卷積窗口從輸入數組的最左上方開始,按從左往右、從上往下 的順序,依次在輸?數組上滑動。我們將每次滑動的行數和列數稱為步幅(stride)。
# 步幅stride conv2d = nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = (3, 5), padding = (0, 1), stride = (3, 4)) endshape3 = comp_conv2d(conv2d, X).shape print(endshape3) # torch.Size([2, 2])
池化層每次對輸入數據的一個固定形狀窗口(又稱池化窗口)中的元素計算輸出。不同于卷積層里計算輸入和核的互相關性,池化層直接計算池化窗口內元素的最大值或者平均值。該運算也 分別叫做最大池化或平均池化。
在二維最大池化中,池化窗口從輸入數組的最左上方開始,按從左往右、從上往下的順序,依次在輸入數組上滑動。當池化窗口滑動到某?位置時,窗口中的輸入子數組的最大值即輸出數組中相應位置的元素。
下面把池化層的前向計算實現在pool2d函數里。
最大池化:
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 18:49:27 2021 @author: 86493 """ import torch from torch import nn def pool2d(x, pool_size, mode = 'max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y X = torch.Tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) end = pool2d(X, (2, 2)) # 默認是最大池化 # end = pool2d(X, (2, 2), mode = 'avg') print(end)
tensor([[4., 5.],
[7., 8.]])
平均池化:
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 18:49:27 2021 @author: 86493 """ import torch from torch import nn def pool2d(x, pool_size, mode = 'max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y X = torch.FloatTensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) # end = pool2d(X, (2, 2)) # 默認是最大池化 end = pool2d(X, (2, 2), mode = 'avg') print(end)
結果如下,注意上面如果mode是avg模式(平均池化)時,不能寫X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]),否則會報錯Can only calculate the mean of floating types. Got Long instead.。把tensor改成Tensor或FloatTensor后就可以了(Tensor是FloatTensor的縮寫)。
tensor([[2., 3.],
[5., 6.]])
一個神經網絡的典型訓練過程如下:
1 定義包含一些可學習參數(或者叫權重)的神經網絡
2. 在輸入數據集上迭代
3. 通過網絡處理輸入
4. 計算 loss (輸出和正確答案的距離)
5. 將梯度反向傳播給網絡的參數
6. 更新網絡的權重,一般使用一個簡單的規則:weight = weight - learning_rate * gradient

# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 19:21:19 2021
@author: 86493
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
# 需要把網絡中具有可學習參數的層放在構造函數__init__
def __init__(self):
super(LeNet, self).__init__()
# 輸入圖像channel:1;輸出channel:6
# 5*5卷積核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation:y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2 * 2 最大池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方陣,則可以只使用一個數字進行定義
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# 做一次flatten
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
# 除去批處理維度,得到其他所有維度
size = x.size()[1:]
num_features = 1
# 將剛才得到的維度之間相乘起來
for s in size:
num_features *= s
return num_features
net = LeNet()
print(net)
# 一個模型的可學習參數可以通過`net.parameters()`返回
params = list(net.parameters())
print("params的len:", len(params))
# print("params:\n", params)
print(params[0].size()) # conv1的權重
print('-' * 60)
# 隨機一個32×32的input
input = torch.randn(1, 1, 32, 32)
out = net(input)
print("網絡的output為:", out)
print('-' * 60)
# 隨機梯度的反向傳播
net.zero_grad() # 清零所有參數的梯度緩存
end = out.backward(torch.randn(1, 10))
print(end) # Noneprint的結果為:
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
params的len: 10
torch.Size([6, 1, 5, 5])
------------------------------------------------------------
網絡的output為: tensor([[ 0.0904, 0.0866, 0.0851, -0.0176, 0.0198, 0.0530, 0.0815, 0.0284,
-0.0216, -0.0425]], grad_fn=<AddmmBackward>)
------------------------------------------------------------
None
(1)只需要定義 forward 函數,backward函數會在使用autograd時自動定義,backward函數用來計算導數。我們可以在 forward 函數中使用任何針對張量的操作和計算。
(2)在backward前最好net.zero_grad(),即清零所有參數的梯度緩存。
(3)torch.nn只支持小批量處理 (mini-batches)。整個 torch.nn 包只支持小批量樣本的輸入,不支持單個樣本的輸入。比如,nn.Conv2d 接受一個4維的張量,即nSamples x nChannels x Height x Width如果是一個單獨的樣本,只需要使用input.unsqueeze(0) 來添加一個“假的”批大小維度。
torch.Tensor:一個多維數組,支持諸如backward()等的自動求導操作,同時也保存了張量的梯度。
nn.Module:神經網絡模塊。是一種方便封裝參數的方式,具有將參數移動到GPU、導出、加載等功能。
nn.Parameter:張量的一種,當它作為一個屬性分配給一個Module時,它會被自動注冊為一個參數。
autograd.Function:實現了自動求導前向和反向傳播的定義,每個Tensor至少創建一個Function節點,該節點連接到創建Tensor的函數并對其歷史進行編碼。
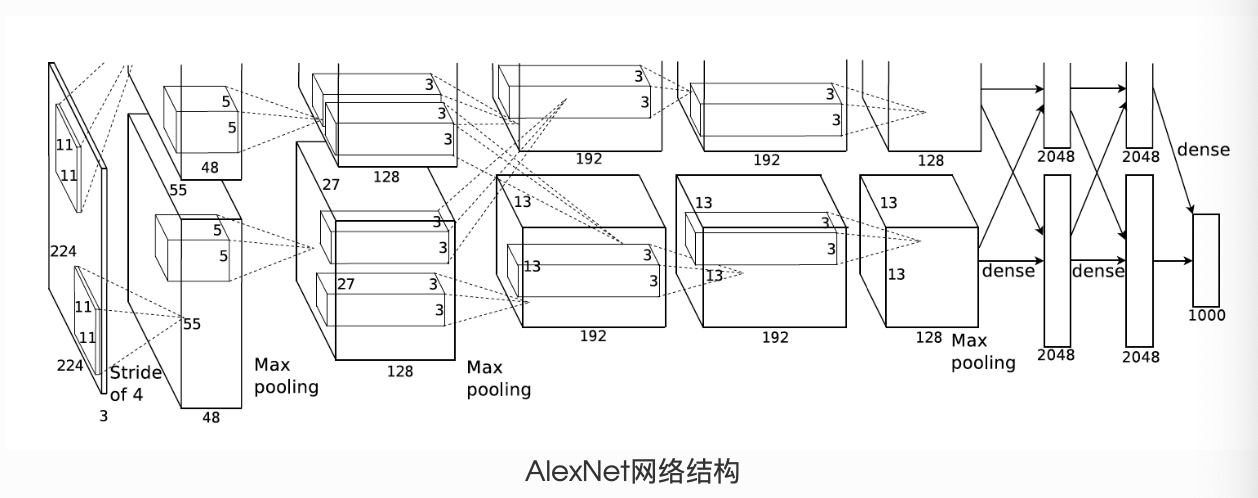
# -*- coding: utf-8 -*- """ Created on Sat Oct 16 21:00:39 2021 @author: 86493 """ import torch from torch import nn class AlexNet(nn.Module): def __init__(self): super(AlexNet, self).__init__() self.conv = nn.Sequential( # in_channels,out_channels,kernel_size,stride,padding nn.Conv2d(1, 96, 11, 4), nn.ReLU(), # kernel_size, stride nn.MaxPool2d(3, 2), # 見笑卷積窗口,但使用padding=2來使輸入和輸出的高寬相同 # 且增大輸出通道數 nn.Conv2d(96, 256, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(3, 2), # 連續3個卷積層,且后面使用更小的卷積窗口 # 除了最后的卷積層外,進一步增大了輸出 # 注:前2個卷積層后不使用池化層來減少輸入的高和寬 nn.Conv2d(256, 384, 3, 1, 1), nn.ReLU(), nn.Conv2d(384, 383, 3, 1, 1), nn.ReLU(), nn.Conv2d(384, 256, 3, 1, 1), nn.ReLU(), nn.MaxPool2d(3, 2) ) # 這里的全連接層的輸出個數比LeNet中的大數倍。 # 使用丟棄層來緩解過擬合 self.fc = nn.Sequential( nn.Linear(256 *5 * 5, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4086), nn.ReLU(), nn.Dropout(0.5), # 輸出層,下次會用到Fash-MNIST,所以此處類別設為10, # 而非論文中的1000 nn.Linear(4096, 10), ) def forward(self, img): feature = self.conv(img) output = self.fc(feature.view(img.shape[0], -1)) return output net = AlexNet() print(net)
可以看到該網絡的結構:
AlexNet( (conv): Sequential( (0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4)) (1): ReLU() (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU() (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU() (8): Conv2d(384, 383, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU() (10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU() (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (fc): Sequential( (0): Linear(in_features=6400, out_features=4096, bias=True) (1): ReLU() (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4086, bias=True) (4): ReLU() (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=10, bias=True) ) )
“PyTorch零基礎入門之有哪些構建模型基礎”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





