溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python中StatsModels如何實現線性回歸”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python中StatsModels如何實現線性回歸”這篇文章吧。
插值、擬合、回歸和預測,都是數學建模中經常提到的概念,而且經常會被混為一談。
插值,是在離散數據的基礎上補插連續函數,使得這條連續曲線通過全部給定的離散數據點。 插值是離散函數逼近的重要方法,利用它可通過函數在有限個點處的取值狀況,估算出函數在其他點處的近似值。
擬合,是用一個連續函數(曲線)靠近給定的離散數據,使其與給定的數據相吻合。
因此,插值和擬合都是根據已知數據點求變化規律和特征相似的近似曲線的過程,但是插值要求近似曲線完全經過給定的數據點,而擬合只要求近似曲線在整體上盡可能接近數據點,并反映數據的變化規律和發展趨勢。插值可以看作是一種特殊的擬合,是要求誤差函數為 0的擬合。由于數據點通常都帶有誤差,誤差為 0 往往意味著過擬合,過擬合模型對于訓練集以外的數據的泛化能力是較差的。因此在實踐中,插值多用于圖像處理,擬合多用于實驗數據處理。
回歸,是研究一組隨機變量與另一組隨機變量之間關系的統計分析方法,包括建立數學模型并估計模型參數,并檢驗數學模型的可信度,也包括利用建立的模型和估計的模型參數進行預測或控制。
預測是非常廣泛的概念,在數模中是指對獲得的數據、信息進行定量研究,據此建立與預測目的相適應的數學模型,然后對未來的發展變化進行定量地預測。通常認為,插值和擬合都是預測類的方法。
回歸是一種數據分析方法,擬合是一種具體的數據處理方法。擬合側重于曲線參數尋優,使曲線與數據相符;而回歸側重于研究兩個或多個變量之間的關系。
回歸分析(Regression analysis)是一種統計分析方法,研究是自變量和因變量之間的定量關系,經常用于預測分析、時間序列模型以及發現變量之間的因果關系。按照變量之間的關系類型,回歸分析可以分為線性回歸和非線性回歸。
線性回歸(Linear regression) 假設給定數據集中的目標(y)與特征(X)存在線性關系,即滿足一個多元一次方程 。 回歸分析中,只包括一個自變量和一個因變量,且二者的關系可用一條直線近似表示,稱為一元線性回歸;如果包括兩個或多個的自變量,且因變量和自變量之間是線性關系,則稱為多元線性回歸。
根據樣本數據,采用最小二乘法可以得到線性回歸模型參數的估計量,并使根據估計參數計算的模型數據與給定的樣本數據之間誤差的平方和為最小。
進一步地,還需要分析對于樣本數據究竟能不能采用線性回歸方法,或者說線性相關的假設是否合理、線性模型是否具有良好的穩定性?這就需要使用統計分析進行顯著性檢驗,檢驗因變量與自變量之間的線性關系是否顯著,用線性模型來描述它們之間的關系是否恰當。
本節結合 Statsmodels 統計分析包 的使用介紹線性擬合和回歸分析。線性模型可以表達為如下公式:
import statsmodels.api as sm from statsmodels.sandbox.regression.predstd
import wls_prediction_std
樣本數據通常保存在數據文件中,因此要讀取數據文件獲得樣本數據。為便于閱讀和測試程序,本文使用隨機數生成樣本數據。讀取數據文件導入數據的方法,將在后文介紹。
# 生成樣本數據: nSample = 100 x1 = np.linspace(0, 10, nSample) # 起點為 0,終點為 10,均分為 nSample個點 e = np.random.normal(size=len(x1)) # 正態分布隨機數 yTrue = 2.36 + 1.58 * x1 # y = b0 + b1*x1 yTest = yTrue + e # 產生模型數據
本案例是一元線性回歸問題,(yTest,x)是導入的樣本數據,我們需要通過線性回歸獲得因變量 y 與自變量 x 之間的定量關系。yTrue 是理想模型的數值,yTest 模擬實驗檢測的數據,在理想模型上加入了正態分布的隨機誤差。
一元線性回歸模型方程為:
y = β0 + β1 * x + e
先通過 sm.add_constant() 向矩陣 X 添加截距列后,再用 sm.OLS() 建立普通最小二乘模型,最后用 model.fit() 就能實現線性回歸模型的擬合,并返回擬合與統計分析的結果摘要。
X = sm.add_constant(x1) # 向 x1 左側添加截距列 x0=[1,…1]
statsmodels.OLS 是 statsmodels.regression.linear_model 的函數,有 4個參數 (endog, exog, missing, hasconst)。
model = sm.OLS(yTest, X) # 建立最小二乘模型(OLS)
results = model.fit() # 返回模型擬合結果
第一個參數 endog 是回歸模型中的因變量 y(t), 是1-d array 數據類型。
第二個輸入 exog 是自變量 x0(t),x1(t),…,xm(t),是(m+1)-d array 數據類型。
需要注意的是,statsmodels.OLS 的回歸模型沒有常數項,其形式為:
y = B*X + e = β0*x0 + β1*x1 + e, x0 = [1,…1]
而之前導入的數據 (yTest,x1) 并不包含 x0,因此需要在 x1 左側增加一列截距列 x0=[1,…1],將自變量矩陣轉換為 X = (x0, x1)。函數 sm.add_constant() 實現的就是這個功能。
參數 missing 用于數據檢查, hasconst 用于檢查常量,一般情況不需要。
Statsmodels 進行線性回歸分析的輸出結果非常豐富,results.summary() 返回了回歸分析的摘要。
print(results.summary()) # 輸出回歸分析的摘要
摘要所返回的內容非常豐富,這里先討論最重要的一些結果,在 summary 的中間段落。
============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 2.4669 0.186 13.230 0.000 2.097 2.837 x1 1.5883 0.032 49.304 0.000 1.524 1.652 ==============================================================================
coef:回歸系數(Regression coefficient),即模型參數 β0、β1、…的估計值。
std err :標準差( Standard deviation),也稱標準偏差,是方差的算術平方根,反映樣本數據值與回歸模型估計值之間的平均差異程度 。標準差越大,回歸系數越不可靠。
t:t 統計量(t-Statistic),等于回歸系數除以標準差,用于對每個回歸系數分別進行檢驗,檢驗每個自變量對因變量的影響是否顯著。如果某個自變量 xi的影響不顯著,意味著可以從模型中剔除這個自變量。
P>|t|:t檢驗的 P值(Prob(t-Statistic)),反映每個自變量 xi 與因變量 y 的相關性假設的顯著性。如果 p<0.05,可以理解為在0.05的顯著性水平下變量xi與y存在回歸關系,具有顯著性。
[0.025,0.975]:回歸系數的置信區間(Confidence interval)的下限、上限,某個回歸系數的置信區間以 95%的置信度包含該回歸系數 。注意并不是指樣本數據落在這一區間的概率為 95%。
此外,還有一些重要的指標需要關注:
R-squared:R方判定系數(Coefficient of determination),表示所有自變量對因變量的聯合的影響程度,用于度量回歸方程擬合度的好壞,越接近于 1說明擬合程度越好。
F-statistic:F 統計量(F-Statistic),用于對整體回歸方程進行顯著性檢驗,檢驗所有自變量在整體上對因變量的影響是否顯著。
Statsmodels 也可以通過屬性獲取所需的回歸分析的數據,例如:
print(“OLS model: Y = b0 + b1 * x”) # b0: 回歸直線的截距,b1: 回歸直線的斜率
print('Parameters: ', results.params) # 輸出:擬合模型的系數
yFit = results.fittedvalues # 擬合模型計算出的 y值
ax.plot(x1, yTest, ‘o', label=“data”) # 原始數據
ax.plot(x1, yFit, ‘r-', label=“OLS”) # 擬合數據
# LinearRegression_v1.py
# Linear Regression with statsmodels (OLS: Ordinary Least Squares)
# v1.0: 調用 statsmodels 實現一元線性回歸
# 日期:2021-05-04
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.sandbox.regression.predstd import wls_prediction_std
def main(): # 主程序
# 生成測試數據:
nSample = 100
x1 = np.linspace(0, 10, nSample) # 起點為 0,終點為 10,均分為 nSample個點
e = np.random.normal(size=len(x1)) # 正態分布隨機數
yTrue = 2.36 + 1.58 * x1 # y = b0 + b1*x1
yTest = yTrue + e # 產生模型數據
# 一元線性回歸:最小二乘法(OLS)
X = sm.add_constant(x1) # 向矩陣 X 添加截距列(x0=[1,...1])
model = sm.OLS(yTest, X) # 建立最小二乘模型(OLS)
results = model.fit() # 返回模型擬合結果
yFit = results.fittedvalues # 模型擬合的 y值
prstd, ivLow, ivUp = wls_prediction_std(results) # 返回標準偏差和置信區間
# OLS model: Y = b0 + b1*X + e
print(results.summary()) # 輸出回歸分析的摘要
print("\nOLS model: Y = b0 + b1 * x") # b0: 回歸直線的截距,b1: 回歸直線的斜率
print('Parameters: ', results.params) # 輸出:擬合模型的系數
# 繪圖:原始數據點,擬合曲線,置信區間
fig, ax = plt.subplots(figsize=(10, 8))
ax.plot(x1, yTest, 'o', label="data") # 原始數據
ax.plot(x1, yFit, 'r-', label="OLS") # 擬合數據
ax.plot(x1, ivUp, '--',color='orange',label="upConf") # 95% 置信區間 上限
ax.plot(x1, ivLow, '--',color='orange',label="lowConf") # 95% 置信區間 下限
ax.legend(loc='best') # 顯示圖例
plt.title('OLS linear regression ')
plt.show()
return
if __name__ == '__main__': #YouCans, XUPT
main()OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.961 Model: OLS Adj. R-squared: 0.961 Method: Least Squares F-statistic: 2431. Date: Wed, 05 May 2021 Prob (F-statistic): 5.50e-71 Time: 16:24:22 Log-Likelihood: -134.62 No. Observations: 100 AIC: 273.2 Df Residuals: 98 BIC: 278.5 Df Model: 1 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 2.4669 0.186 13.230 0.000 2.097 2.837 x1 1.5883 0.032 49.304 0.000 1.524 1.652 ============================================================================== Omnibus: 0.070 Durbin-Watson: 2.016 Prob(Omnibus): 0.966 Jarque-Bera (JB): 0.187 Skew: 0.056 Prob(JB): 0.911 Kurtosis: 2.820 Cond. No. 11.7 ============================================================================== OLS model: Y = b0 + b1 * x Parameters: [2.46688389 1.58832741]
# LinearRegression_v2.py
# Linear Regression with statsmodels (OLS: Ordinary Least Squares)
# v2.0: 調用 statsmodels 實現多元線性回歸
# 日期:2021-05-04
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.sandbox.regression.predstd import wls_prediction_std
# 主程序
def main(): # 主程序
# 生成測試數據:
nSample = 100
x0 = np.ones(nSample) # 截距列 x0=[1,...1]
x1 = np.linspace(0, 20, nSample) # 起點為 0,終點為 10,均分為 nSample個點
x2 = np.sin(x1)
x3 = (x1-5)**2
X = np.column_stack((x0, x1, x2, x3)) # (nSample,4): [x0,x1,x2,...,xm]
beta = [5., 0.5, 0.5, -0.02] # beta = [b1,b2,...,bm]
yTrue = np.dot(X, beta) # 向量點積 y = b1*x1 + ...+ bm*xm
yTest = yTrue + 0.5 * np.random.normal(size=nSample) # 產生模型數據
# 多元線性回歸:最小二乘法(OLS)
model = sm.OLS(yTest, X) # 建立 OLS 模型: Y = b0 + b1*X + ... + bm*Xm + e
results = model.fit() # 返回模型擬合結果
yFit = results.fittedvalues # 模型擬合的 y值
print(results.summary()) # 輸出回歸分析的摘要
print("\nOLS model: Y = b0 + b1*X + ... + bm*Xm")
print('Parameters: ', results.params) # 輸出:擬合模型的系數
# 繪圖:原始數據點,擬合曲線,置信區間
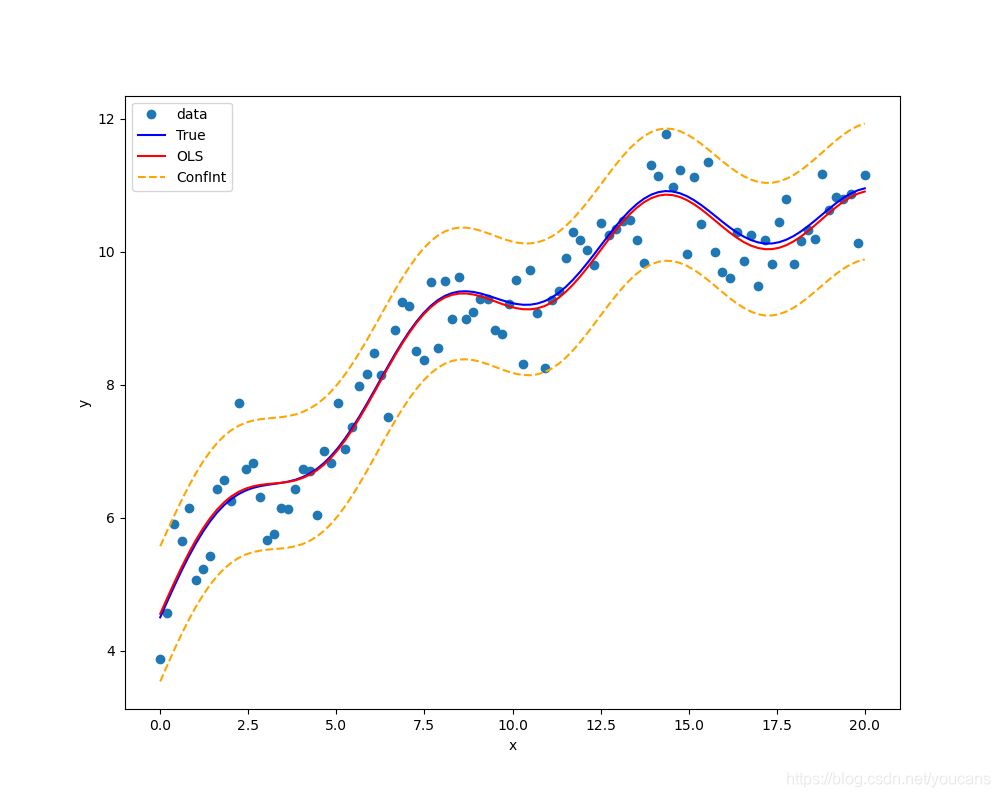
prstd, ivLow, ivUp = wls_prediction_std(results) # 返回標準偏差和置信區間
fig, ax = plt.subplots(figsize=(10, 8))
ax.plot(x1, yTest, 'o', label="data") # 實驗數據(原始數據+誤差)
ax.plot(x1, yTrue, 'b-', label="True") # 原始數據
ax.plot(x1, yFit, 'r-', label="OLS") # 擬合數據
ax.plot(x1, ivUp, '--',color='orange', label="ConfInt") # 置信區間 上屆
ax.plot(x1, ivLow, '--',color='orange') # 置信區間 下屆
ax.legend(loc='best') # 顯示圖例
plt.xlabel('x')
plt.ylabel('y')
plt.show()
return
if __name__ == '__main__':
main()OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.932 Model: OLS Adj. R-squared: 0.930 Method: Least Squares F-statistic: 440.0 Date: Thu, 06 May 2021 Prob (F-statistic): 6.04e-56 Time: 10:38:51 Log-Likelihood: -68.709 No. Observations: 100 AIC: 145.4 Df Residuals: 96 BIC: 155.8 Df Model: 3 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 5.0411 0.120 41.866 0.000 4.802 5.280 x1 0.4894 0.019 26.351 0.000 0.452 0.526 x2 0.5158 0.072 7.187 0.000 0.373 0.658 x3 -0.0195 0.002 -11.957 0.000 -0.023 -0.016 ============================================================================== Omnibus: 1.472 Durbin-Watson: 1.824 Prob(Omnibus): 0.479 Jarque-Bera (JB): 1.194 Skew: 0.011 Prob(JB): 0.551 Kurtosis: 2.465 Cond. No. 223. ============================================================================== OLS model: Y = b0 + b1*X + ... + bm*Xm Parameters: [ 5.04111867 0.4893574 0.51579806 -0.01951219]
Dep.Variable: y 因變量
Model:OLS 最小二乘模型
Method: Least Squares 最小二乘
No. Observations: 樣本數據的數量
Df Residuals:殘差自由度(degree of freedom of residuals)
Df Model:模型自由度(degree of freedom of model)
Covariance Type:nonrobust 協方差陣的穩健性
R-squared:R 判定系數
Adj. R-squared: 修正的判定系數
F-statistic: 統計檢驗 F 統計量
Prob (F-statistic): F檢驗的 P值
Log likelihood: 對數似然 coef:自變量和常數項的系數,b1,b2,...bm,b0
std err:系數估計的標準誤差
t:統計檢驗 t 統計量
P>|t|:t 檢驗的 P值
[0.025, 0.975]:估計參數的 95%置信區間的下限和上限
Omnibus:基于峰度和偏度進行數據正態性的檢驗
Prob(Omnibus):基于峰度和偏度進行數據正態性的檢驗概率
Durbin-Watson:檢驗殘差中是否存在自相關
Skewness:偏度,反映數據分布的非對稱程度
Kurtosis:峰度,反映數據分布陡峭或平滑程度
Jarque-Bera(JB):基于峰度和偏度對數據正態性的檢驗
Prob(JB):Jarque-Bera(JB)檢驗的 P值。
Cond. No.:檢驗變量之間是否存在精確相關關系或高度相關關系。
以上是“Python中StatsModels如何實現線性回歸”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





