溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python如何安裝spark,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
Java JDK 1.8.0_111
Python 3.9.6
Spark 3.1.2
Hadoop 3.2.2
從官網下載相應JDK的版本安裝,并進行環境變量的配置
(1)在系統變量新建JAVA_HOME,根據你安裝的位置填寫變量值
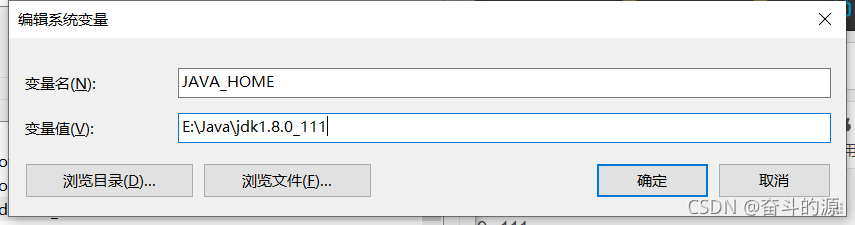
(2)新建CLASSPATH
變量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意前面所需的符號)
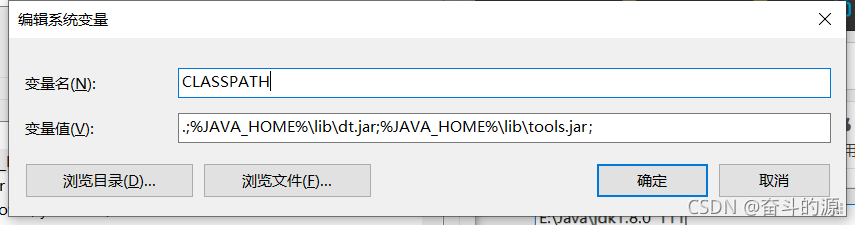
(3)點擊Path

在其中進行新建:%JAVA_HOME%\bin
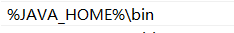
(4)配置好后進行確定
(5)驗證,打開cmd,輸入java -version和javac進行驗證


此上說明jdk環境變量配置成功
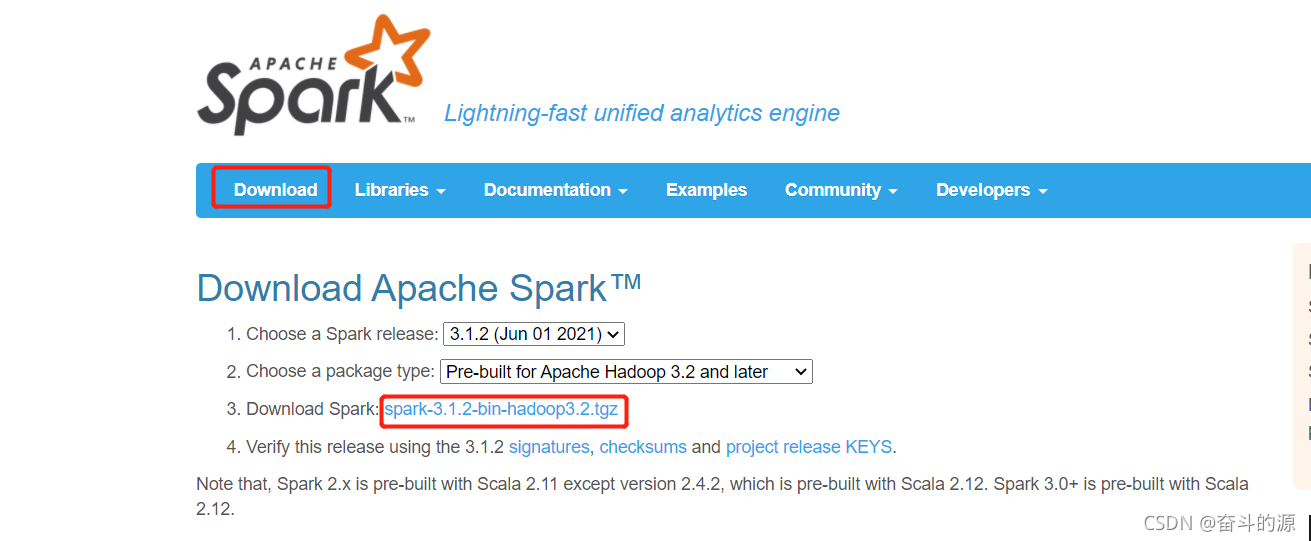
(1)下載安裝:
Spark官網:spark-3.1.2-bin-hadoop3.2下載地址
(2)解壓,配置環境
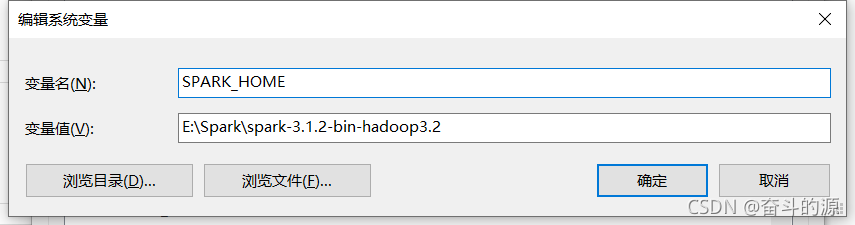
(3)點擊Path,進行新建:%SPARK_HOME%\bin,并確認
(4)驗證,cmd中輸入pyspark
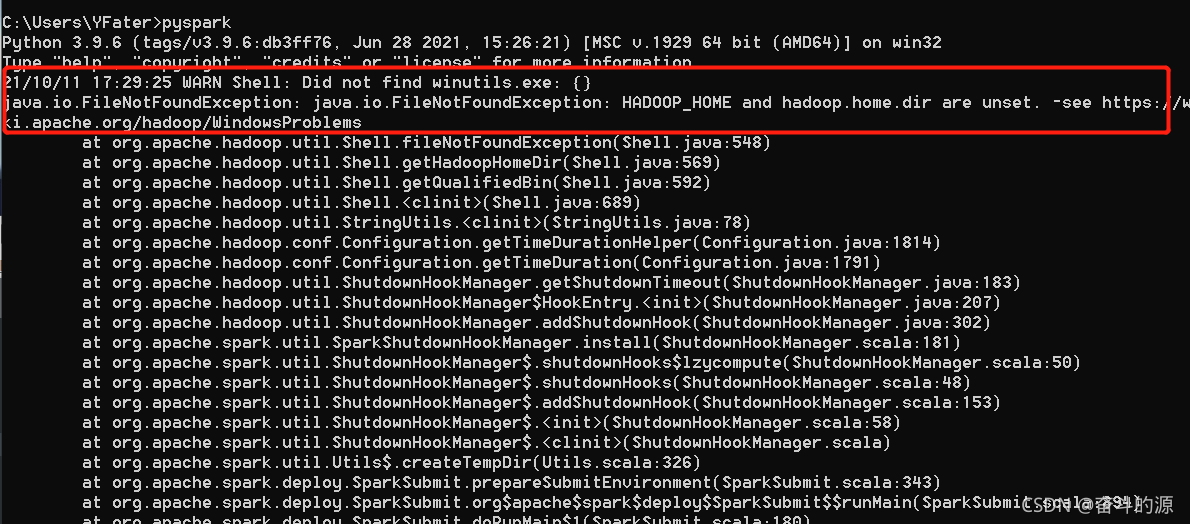
這里提醒我們要安裝Hadoop
(1)下載:
Hadoop官網:Hadoop 3.2.2下載地址

(2)解壓,配置環境
注意:解壓文件后,bin文件夾中可能沒有以下兩個文件:

下載地址:https://github.com/cdarlint/winutils
配置環境變量CLASSPATH:%HADOOP_HOME%\bin\winutils.exe
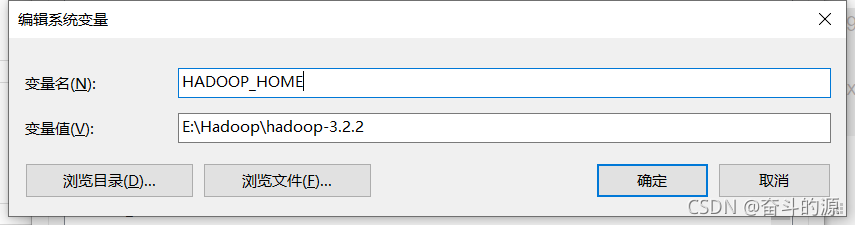
(3)點擊Path,進行新建:%HADOOP_HOME%\bin,并確認
(4)驗證,cmd中輸入pyspark
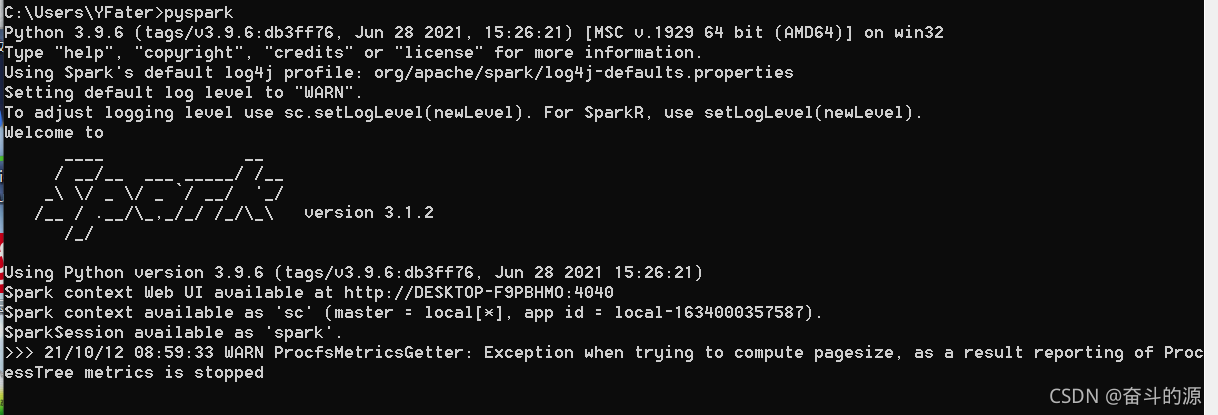
由上可以看出spark能運行成功,但是會出現如下警告:
WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
這里因為spark為3.x版本有相關改動,使用spar2.4.6版本不會出現這樣的問題。
不改版本解決方式(因是警告,未嘗試):
方式一:解決方法一
方式二:解決方法二
(1)Run–>Edit Configurations

(2)對Environment Variables進行配置
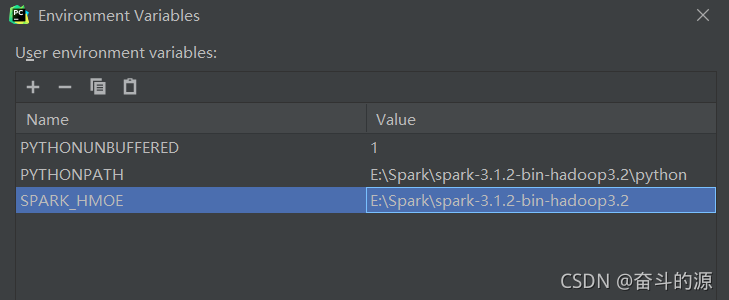
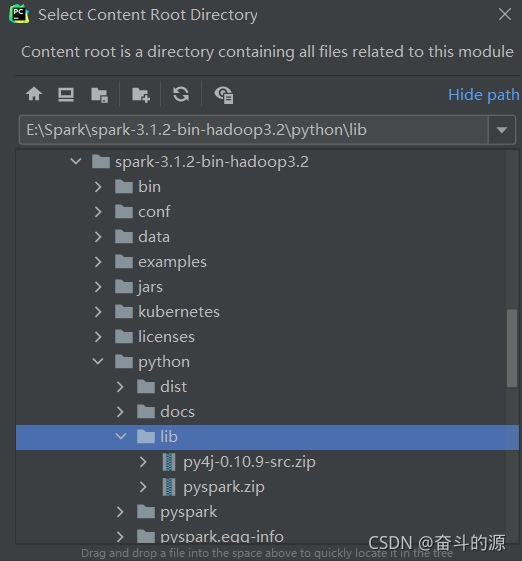
(3)File–>Settings–>Project Structure–>Add Content Root
找到spark-3.1.2-bin-hadoop3.2\python\lib下兩個包進行添加
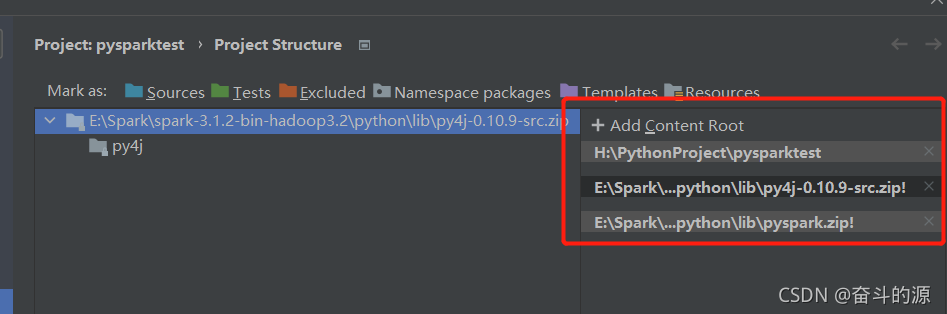
選擇結果:
(4)測試
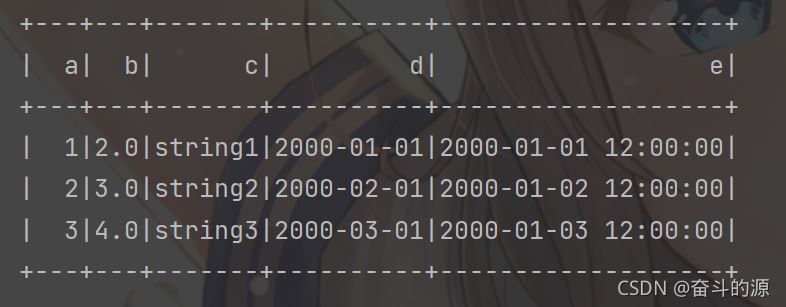
# 添加此代碼,進行spark初始化 import findspark findspark.init() from datetime import datetime, date from pyspark.sql import SparkSession spark = SparkSession.builder.getOrCreate() rdd = spark.sparkContext.parallelize([ (1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)), (2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)), (3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0)) ]) df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e']) df.show()
運行結果:
conda create -n pyspark_env python==3.9.6
查看環境:
conda env list
運行結果:

切換到pyspark_env并進行安裝pyspark
pip install pyspark

運行上面的實例,會出現以下錯誤:

這說明我們需要配置py4j,SPARK_HOME
SPARK_HOME:
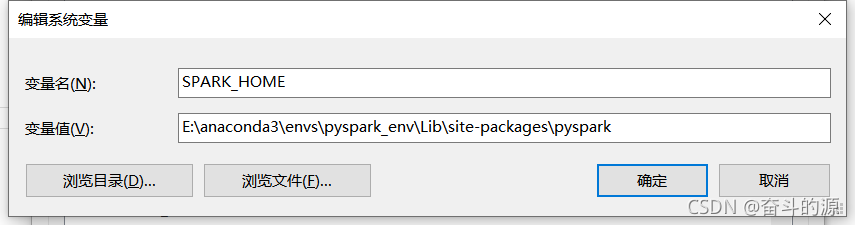
PYTHONPATH設置:
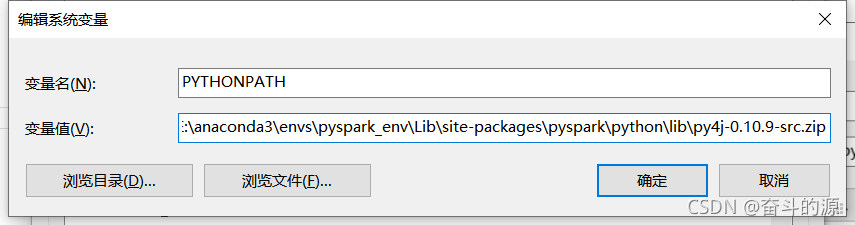
HADOOP_HOME設置:
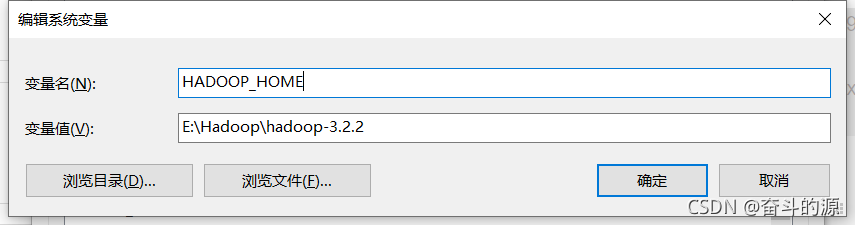
path中設置:


# 添加此代碼,進行spark初始化 import findspark findspark.init() from datetime import datetime, date from pyspark.sql import SparkSession spark = SparkSession.builder.getOrCreate() rdd = spark.sparkContext.parallelize([ (1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)), (2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)), (3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0)) ]) df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e']) df.show()
運行結果同上
以上是“Python如何安裝spark”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





