溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Spark如何安裝及環境配置,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
1、Apache spark下載
在瀏覽器輸入網址
https://spark.apache.org/downloads.html進入spark的下載頁面,如下圖所示:
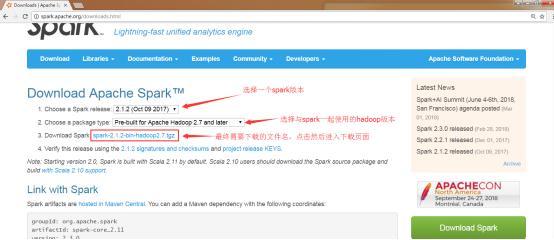
下載時需要注意的是在第1步選擇完spark版本之后的第2步“choose a package type ”時,spark與hadoop版本必須配合使用。因為spark會讀取hdfs文件內容而且spark程序還會運行在HadoopYARN上。所以必須按照我們目前安裝的hadoop版本來選擇package type。我們目前使用的hadoop版本為hadoop2.7.5,所以選擇Pre-built for Apache Hadoop 2.7 and later。
點擊第3步Download Spark后的連接
spark-2.1.2-bin-hadoop2.7.tgz進入下圖所示的頁面。在國內我們一般選擇清華的服務器下載,這下載速度比較快,連接地址
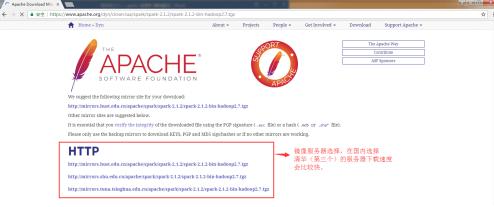
2、安裝spark
通過WinSCP將
spark-2.1.2-bin-hadoop2.7.tgz上傳到master虛擬機的Downloads目錄下,然后解壓到用戶主目錄下并更改解壓后的文件名(改文件名目的是名字變短,容易操作)。解壓過程需要一點時間,耐心等待哈。
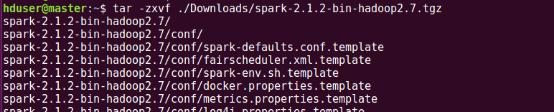
解壓完成后通過ls命令查看當前用戶主目錄,如下圖所示增加了spark-2.1.2-bin-hadoop2.7文件目錄

通過mv命令更改spark-2.1.2-bin-hadoop2.7名為spark

3、配置spark環境變量
通過命令vim .bashrc編輯環境變量

在文件末尾增加如下內容,然后保存并退出

重新加載環境變量配置文件,使新的配置生效(僅限當前終端,如果退出終端新的環境變量還是不能生效,重啟虛擬機系統后變可永久生效)

通過spark-shell展示spark是否正確安裝,Spark-shell是添加了一些spark功能的scala REPL交互式解釋器,啟動方式如下圖所示。啟動過程中會打印spark相關信息如版本。
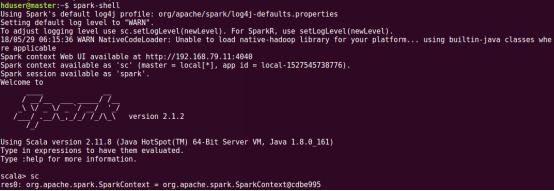
退出spark-shell使用命令:quit

4、在其他節點安裝spark
在master節點安裝完成后只需復制spark文件目錄及.bashrc文件到其他節點即可,具體操作命令可按下圖操作



最后重啟slave1、slave2即可使配置文件生效。到這里spark安裝完成,接下來就是根據spark運行模式來配置spark相關配置文件使集群正常工作。
5、配置spark相關文件
第一步:spark-env.sh文件
通過環境變量配置確定的Spark設置。環境變量從Spark安裝目錄下的conf/spark-env.sh腳本讀取。
可以在spark-env.sh中設置如下變量:
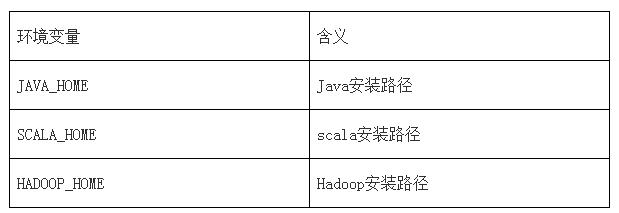
Spark相關配置
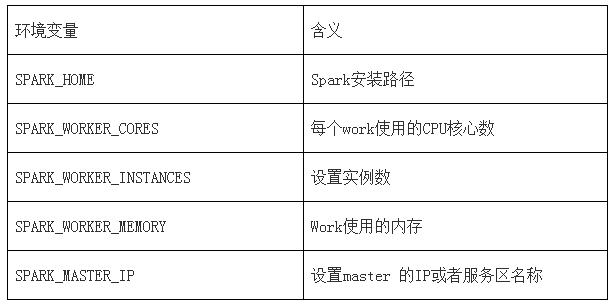
首先開啟三個虛擬機master 、slave1、slave2,接下來在master主機上配置,配置完成之后將spark/conf發送到其他節點即可。
我們先跳轉到spark/conf目錄下看看我們需要配置哪些文件。如下圖所示通過ls命令查看文件列表,我們今天主要用到的有spark-env.sh.template、slaves.template,我們還可以用log4j.properties.template來修改輸出信息。

注意,當Spark安裝時,conf/spark-env.sh默認是不存在的。你可以復制
conf/spark-env.sh.template創建它。

通過vim編輯器編輯spark-env.sh,在終端中我們可以只輸入前幾個字母然后按tab鍵來給我們自動補全。

在文件末尾添加如下內容,保存并退出
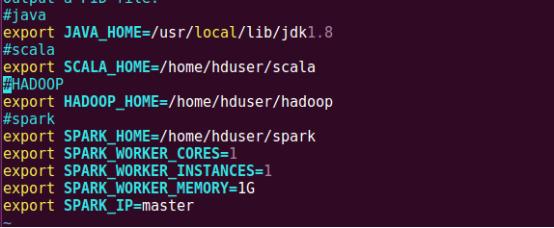
第二步:log4j.properties
spark在啟動過程中會有大量日志信息打印出來,如果我們只想看警告或者錯誤,而不是一般信息可以在log4j.properties中設置,同樣的spark為我們提供了一個模板文件,需要通過模板復制出log4j.properties

設置方法為將文件第二行INFO改為WARN

更改完成后文件內容如下圖所示,記得保存并退出。

第三步:slaves文件
slaves文件主要作用是告訴spark集群哪些節點是工作節點worker,這里slaves文件也需要由模板文件復制過來,操作如下圖所示

使用vim編輯器編輯slaves

文件中輸入如下內容,表示工作節點為slave1和slave2,保存并退出。
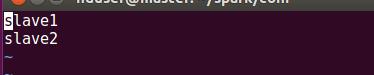
最后將spark/conf目錄移動到slave1 slave2節點spark目錄下,操作如下圖所示
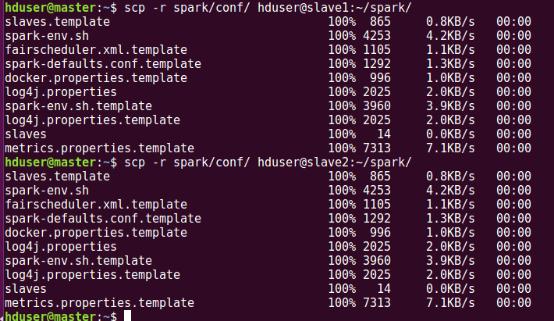
現在就可以啟動集群了,先啟動hadoop集群(也可以不用hadoop,但是在實際應用中大部分spark還是會用到hadoop的資源管理YARN)再啟動spark集群,操作如下所示。
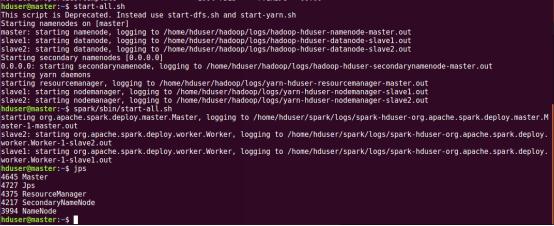
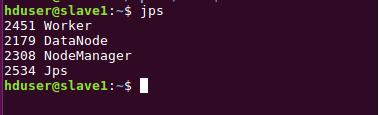
通過jps查看啟動的進程,在master節點上spark的進程是Master,在slave節點上spark相關進程是Worker。
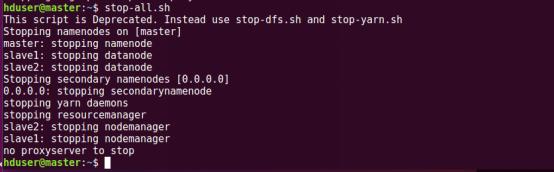
停止集群時要先停止spark集群

再停止hadoop集群
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Spark如何安裝及環境配置”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





