溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“python數據解析中XPath有什么用”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“python數據解析中XPath有什么用”這篇文章吧。
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言。
xpath是最常用且最便捷高效的一種解析方式,通用型強,其不僅可以用于python語言中,還可以用于其他語言中,數據解析建議首先xpath。
xpath解析原理:
實例化一個etree的對象,且需要將被解析的頁面源代碼數據加載到該對象中
調用etree對象中的xpath方法結合著xpath表達式實現標簽的定位和內容的捕獲
安裝lxml
pip install -i https://mirrors.aliyun.com/pypi/simple/ lxml
from lxml import etree
tree = etree.parse('./tree.html') #從本地加載源碼,實例化一個etree對象。必須是本地的文件,不能是字符串
tree = etree.HTML(源碼) #從互聯網加載源碼,實例化etree對象
# / 表示從從根節點開始,一個 / 表示一個層級,//表示多個層級
r = tree.xpath('//div//a') #以列表的形式返回div下的所有的a標簽對象的地址
r = tree.xpath('//div//a')[1] #返回div下的第二個a標簽對象地址
r = tree.xpath('//div[@class="tang"]') #以列表的形式返回tang標簽地址
r = tree.xpath('//div[@class="tang"]//a') #以列表的形式返回tang標簽下所有的a標簽地址
#獲取標簽中的文本內容
r = tree.xpath('//div[@class="tang"]//a/text()') #以列表的形式返回所有a標簽中的文本
#獲取標簽中屬性值
r = tree.xpath('//div//a/@href') ##以列表的形式返回所有a標簽中href屬性值tree.html
<html lang="en"> <head> <meta charset="utf-8" /> <meta name="theme-color" content="#ffffff"></meta> <title>xpaht測試</title> </head> <body> <div> <p>百里守約</p> </div> <div class="song"> <p>前程似錦</p> </div> <div class="song"> <p>前程似錦2</p> </div> <div class="ming"> #后面改了名字 <p>以夢為馬</p> </div> <div class="tang"> <ul> <li><a href='http://123.com' title='qing'>清明時節</a></li> <li><a href='http://ws.com' title='qing'>秦時明月</a></li> <li><a href='http://xzc.com' title='qing'>漢時關</a></li> </ul> </div> <flink-root></flink-root> <script type="text/javascript" src="runtime.0dcf16aad31edd73d8e8.js"></script> <script type="text/javascript" src="es2015-polyfills.923637a8e6d276e6f6df.js"></script> <script type="text/javascript" src="polyfills.bb2456cce5322b484b77.js"></script> <script type="text/javascript" src="main.8128365baee3dc30e607.js"></script> </body> </html>
將頁面中的房源名稱解析出來,即將title值解析出來就行
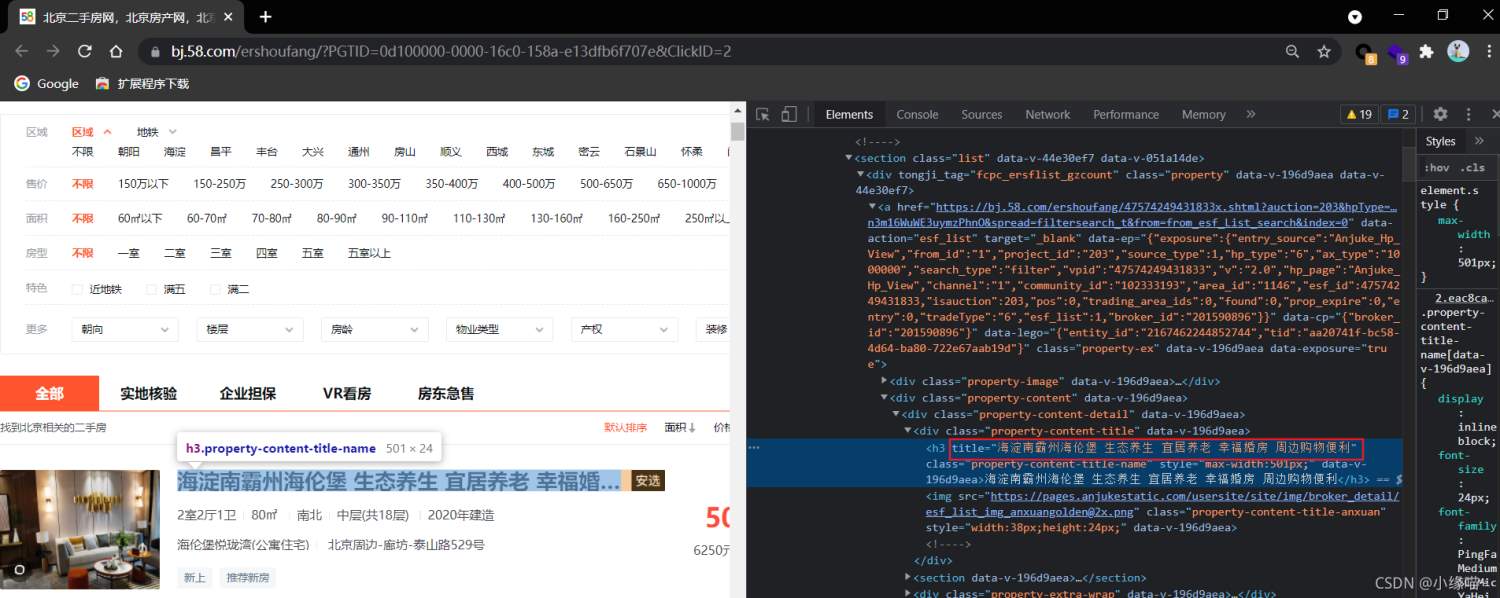
思路
獲取房源名稱所在的url,并獲取其響應數據
數據解析,構造xpath表達式。提取目標數據
import requests
from lxml import etree
url = "https://bj.58.com/ershoufang/p1/"
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
pag_response = requests.get(url,headers=headers,timeout=3).text
#實例化一個etree對象
tree = etree.HTML(pag_response)
r = tree.xpath('//span[@class="content-title"]/text()') #獲取所有//span標簽為"content-title"的文本內容
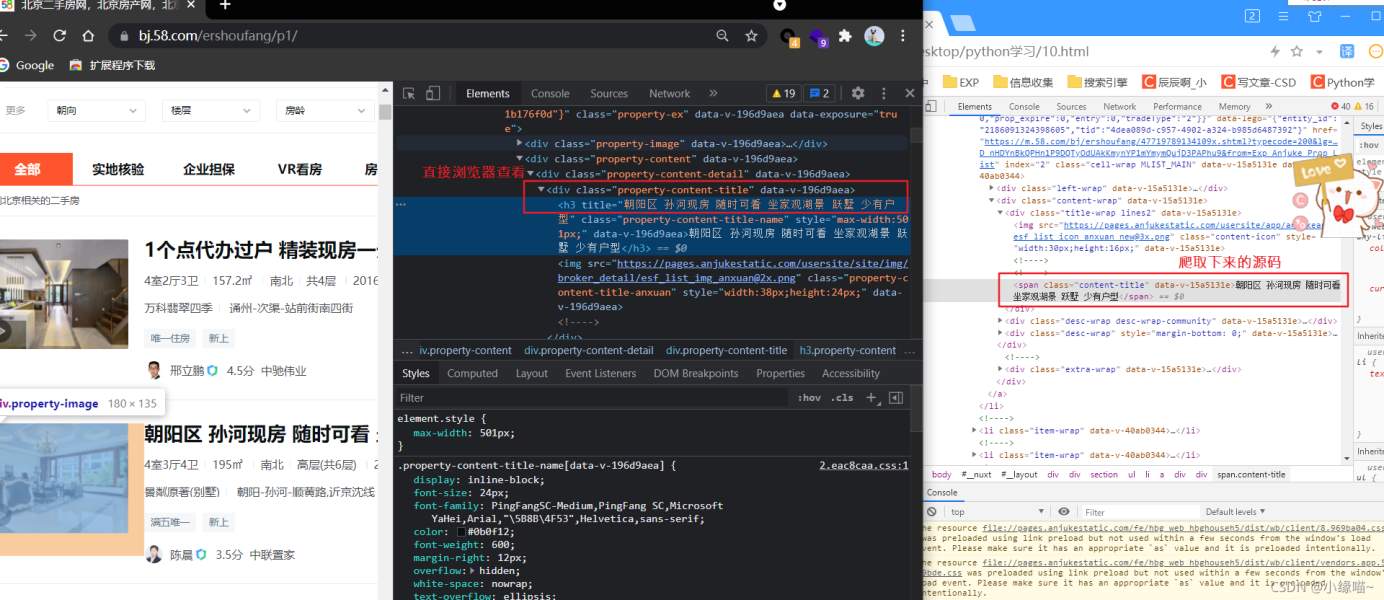
print(r)Tips:我們使用xpath進行數據解析時,不能直接看元素就進行構造xpath表達式,以為很多情況下從瀏覽中看的元素結構和爬取下來的源碼結構不一樣。所以正確方法是先將源碼爬下來再觀察進行構造xpath。
如下瀏覽器中的元素結構和爬取的元素結構就不一樣。如果按照瀏覽器匯總的元素來構造xpath表達式,則不會解析成功!
以上是“python數據解析中XPath有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





