溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark中最重要的機制有那些?
1.RDD,2.Spark調度機制,3Shuffle過程
什么是RDD?
可以這么說,你懂了RDD,基本上就可以對Hadoop和Spark的一半給吃透了,那么到底是RDD
RDD(彈性分布式數據集)首先體現數據集,RDD是對原始數據的封裝,該種數據結構內部可以對數據進行邏輯分區,其次分布式體現是并行計算以及需要解決容錯問題,也就是根據依賴,找到第一層RDD,最后根據RDD編號與分區編號,可以唯一確定該分區對應的塊編號,就能從存儲介質中提取出分區對應的數據。在就是彈性,RDD在可以不改變內部存儲數據記錄的前提下,去調整并行計算單元的劃分結構(這個可能就是Stage)
基本概念
(1)應用程序:用戶構建的Spark應用程序,包含驅動程序(一個Driver功能的代碼)和在集群的多個工作結點上運行的Executor代碼。
(2)驅動程序:包含main入口函數并在main函數內實例化SparkContext對象的應用程序稱為驅動應用程序。不說了,直接上代碼如下:
Var logFile="YOUR_SPARK_HOME/README.md"http://本地文件目錄
val conf=new SparkConf().setAppName("Simple Application");//給Application命名
val sc=new SparkContext(conf);
(3)Master(ClusterManager)管理者整個集群,目前Spark主要支持三種類型:Standlone模式,Mesos模式,Yarn模式。
(4)Worker節點:運行Worker守護進程的集群結點。
(5)任務執行器(Executor):一個Worker節點上可能有多個Executor, 每個Executor都擁有固定的核心數量和堆棧大小。
(6)作業(job)::包含多個Task(任務)組成的并行計算(并排的那些分區)),往往由Spark的action觸發產生。在Spark中通過runJob方法向Spark集群中提交Job
(7)階段(Stage):每個job會因為RDD之間的依賴關系被拆分成多個Task集合,其名稱稱為Stage,每一個Task集合,也可以叫TaskSet(任務集)
補充:
每個Application中可能有多個job,相互獨立。
每個Worker可以起一個或多個Executor。
每個Executor由若干core組成,每個Executor的每個core一次只能執行一個Task。
每個Task執行的結果就是生成了目標RDD的一個partiton。
依賴于并行計算如何理解?
4.1分區是并行計算的基本單位:一個原始數據分成了10個分區,那么就可以同時并行這個10分區,是不是可以這樣去理解?不一定,如果都是窄依賴,沒有問題,但其中會涉及到寬依賴,這其中就會產生分區與分區之間的數據進行交叉,反正不像同時完這10個分區數據這么快。
4.2每個分區內數據的計算當成一個并行任務,每個并行任務包含一個計算鏈,每一個CPU核心就去執行這些計算連。直接,簡單,干脆,不玩虛的,上代碼理解計算鏈:
rdd.map(line=>line.length).filter().等等之類的。
如果這些計算鏈之間都是獨立的,而且互不影響,那么我們可以并行計算。我們可以將這些鏈條之間的關系定義為窄依賴(一對一依賴和范圍依賴)
RDD為什么要劃分Stage,怎么劃分stage?
如果子RDD一個分區內的數據依賴于多個父RDD中分區的數據,這個叫做寬依賴,或者叫做Shuffle依賴,那么如果有多個子RDD,每個子RDD都依賴多個父RDD中分區的數據,我們是不是要想辦法把RDD數據保存起來,提供給這些子分區計算使用,否則是不是每個分區都要重新計算多個父RDD數據,也在這個地方開始劃分Stage的原因。凡是遇到寬依賴,就劃分stage。
Spark如何管理資源?
Spark集群管理器分為三種,Standlone模式,Mesos模式,Yarn模式。這是重點,但又不是很重要,所以這地方不是十分了解,也沒有多大損失。
Spark內部如何調度?
DAGScheduler是面向Stage的任務調度器,負責接收Spark應用提交的Job,根據RDD的依賴關系劃分Stage,并提交Stage給TaskScheduler
TaskScheduler是面向Task的任務調度器,它接受DAGScheduler提交過來的TaskSets,然后把一個個Task提交到Work結點運行,每個Executor運行什么Task也是在此處分配的。
最重要的就是這張圖了:
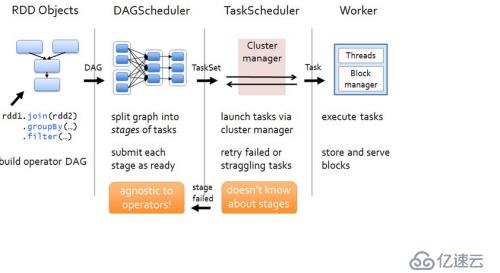
(1)任何的Spark應用程序都包含Driver和Executor代碼。Spark應用程序首先在Driver初始化SparkContext。因為SparkContext是Spark應用程序通往集群的唯一途徑。在SparkContext里面包含了兩個調度器,一個是DAGScheduler和TaskScheduler,在創建SparkContext對象的同時也自動創建了這兩個類。
(2)SparkContext初始化完成后,首先根據Spark的相關配置,想Cluster Master申請所需要的資源,然后在各個Worker結點初始化相應的Executor。Executor初始化完成后,Driver將通過對Spark應用程序中的RDD代碼進行解析,生成相應的RDD graph(RDD圖),該圖描述了RDD的相關信息及彼此之間的依賴關系。即是圖中第一個部分,這些RDD Objects
(3)RDD圖構建完畢后,Driver將提交給DAGScheduler進行解析。DAGScheduler在解析RDD圖的過程中,當遇到Action算子后將進行逆向解析,根據RDD之間的依賴關系,以及是否存在Shuffle,將RDD圖解析成一系列具有先后依賴關系的Stage。Stage以shuffle進行劃分,即如果兩個RDD之間存在依賴關系,DAGScheduler將會在這RDD之間拆分為兩個Stage進行執行,且只有前一個Stage執行完畢之后,才執行后一個Stage。
(4)DAGScheduler將劃分的一系列的Stage(TaskSet),按照Stage的先后順序依次提交給底層的調度器TaskScheduler執行。
(5)TaskScheduler接收到DAGScheduler的stage任務后,將會在集群環境中構建一個TaskSetManager實例來管理Stage(TaskSet)的生命周期。
(6)TaskSetManager將會把相關的計算代碼,數據資源文件等發送到相應的Executor上,并在相應的Executor上啟動線程池執行。
(7)在Task執行的過程中,可能有部分應用程序涉及到I/0的輸入輸出,在每個Executor由相應的BlockManager進行管理,相關BlockManager的信息將會與Driver中的Blocktracker進行交互和同步。
(8)在TaskThreads執行的過程中,如果存在運行錯誤,或其他影響的問題導致失敗,TaskSetManager將會默認嘗試3次,嘗試均失敗后將上報TaskScheduler,TaskScheduler如果解決不了,在上報DAGScheduler,DAGScheduler將根據各個Worker結點的運行情況重新提交到別Executor中執行。
(9)TaksThread執行完畢后,將把執行的結果反饋給TaskSetManager,TaskSetManager反饋給TaskScheduler,TaskScheduler在上報DAGScheduler,DAGScheduler將根據是否還存在待執行的的Stage,將繼續循環迭代提交給TaskScheduler去執行。
(10)待所有的Stage都執行完畢后,將會最終達到應用程序的目標,或者輸出到文件,或者在屏幕顯示等,Driver的本次運行過程結束,等待用戶的其他指令或者關閉。
(11)在用戶顯示關閉SparkContext,整個運行過程結束,相關的資源或被釋放,或被回收。
Spark這種運行形式有利于不同Application之間的資源調度,同時也就意味著不同的Application無法做到相互通信和信息交互。
Driver負責所有任務調度,所以他應該盡可能地靠近Worker結點,能在同一個網絡中最后了。
10.Shuffle是怎么個過程?
只有當Shuffle依賴中父RDD所有分區的數據被計算和存儲完畢后,子RDD才會開始拉取需要的分區數據。這里將整個數據傳輸的過程稱為Spark的Shuffle過程。在Shuffle過程中,把一個分區數據計算完畢到數據被寫入到磁盤的過程,稱為Shuffle寫過程。對應的,在子RDD某個分區計算的過程中,把所需的數據從父RDD拉取過來的過程,稱為Shuffle讀過程。
不論是Spark還是Hadoop,在對待shuffle的過程中有著諸多類似,一些概念可以直接套用,例如shuffle過程中,提供數據的一端稱作map端, map端生成的任務稱為mapper.對應的,接受數據的一端稱作reduce端,reduce端每個拉取數據的任務稱為reducer。Shuffle過程的本質是將map端獲得的數據使用分區器進行劃分,并將數據發送給對應的reducer的過程。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





