溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何解決kafka消息堆積及分區不均勻的問題”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何解決kafka消息堆積及分區不均勻的問題”吧!
kafka消息堆積及分區不均勻的解決
1、先在kafka消息中創建
2、添加配置文件application.properties
3、創建kafka工廠
4、展示kafka消費者
kafka出現若干分區不消費的現象
定位過程
驗證
解決方法
我在環境中發現代碼里面的kafka有所延遲,查看kafka消息發現堆積嚴重,經過檢查發現是kafka消息分區不均勻造成的,消費速度過慢。這里由自己在虛擬機上演示相關問題,給大家提供相應問題的參考思路。
這篇文章有點遺憾并沒重現分區不均衡的樣例和Warning: Consumer group ‘testGroup1' is rebalancing. 這里僅將正確的方式展示,等后續重現了在進行補充。
主要有兩個要點:
1、一個消費者組只消費一個topic.
2、factory.setConcurrency(concurrency);這里設置監聽并發數為 部署單元節點*concurrency=分區數量
對應分區數目的topic(testTopic2,testTopic3)testTopic1由代碼創建
./kafka-topics.sh --create --zookeeper 192.168.25.128:2181 --replication-factor 1 --partitions 2 --topic testTopic2
kafka.test.topic1=testTopic1 kafka.test.topic2=testTopic2 kafka.test.topic3=testTopic3 kafka.broker=192.168.25.128:9092 auto.commit.interval.time=60000 #kafka.test.group=customer-test kafka.test.group1=testGroup1 kafka.test.group2=testGroup2 kafka.test.group3=testGroup3 kafka.offset=earliest kafka.auto.commit=false session.timeout.time=10000 kafka.concurrency=2
package com.yin.customer.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* @author yin
* @Date 2019/11/24 15:54
* @Method
*/
@Configuration
@Component
public class KafkaConfig {
@Value("${kafka.broker}")
private String broker;
@Value("${kafka.auto.commit}")
private String autoCommit;
// @Value("${kafka.test.group}")
//private String testGroup;
@Value("${session.timeout.time}")
private String sessionOutTime;
@Value("${auto.commit.interval.time}")
private String autoCommitTime;
@Value("${kafka.offset}")
private String offset;
@Value("${kafka.concurrency}")
private Integer concurrency;
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
//監聽設置兩個個分區
factory.setConcurrency(concurrency);
//打開批量拉取數據
factory.setBatchListener(true);
//這里設置的是心跳時間也是拉的時間,也就說每間隔max.poll.interval.ms我們就調用一次poll,kafka默認是300s,心跳只能在poll的時候發出,如果連續兩次poll的時候超過
//max.poll.interval.ms 值就會導致rebalance
//心跳導致GroupCoordinator以為本地consumer節點掛掉了,引發了partition在consumerGroup里的rebalance。
// 當rebalance后,之前該consumer擁有的分區和offset信息就失效了,同時導致不斷的報auto offset commit failed。
factory.getContainerProperties().setPollTimeout(3000);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
private ConsumerFactory<String,String> consumerFactory() {
return new DefaultKafkaConsumerFactory<String, String>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
//kafka的地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
//是否自動提交 Offset
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
// enable.auto.commit 設置成 false,那么 auto.commit.interval.ms 也就不被再考慮
//默認5秒鐘,一個 Consumer 將會提交它的 Offset 給 Kafka
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
//這個值必須設置在broker configuration中的group.min.session.timeout.ms 與 group.max.session.timeout.ms之間。
//zookeeper.session.timeout.ms 默認值:6000
//ZooKeeper的session的超時時間,如果在這段時間內沒有收到ZK的心跳,則會被認為該Kafka server掛掉了。
// 如果把這個值設置得過低可能被誤認為掛掉,如果設置得過高,如果真的掛了,則需要很長時間才能被server得知。
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionOutTime);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//組與組間的消費者是沒有關系的。
//topic中已有分組消費數據,新建其他分組ID的消費者時,之前分組提交的offset對新建的分組消費不起作用。
//propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, testGroup);
//當創建一個新分組的消費者時,auto.offset.reset值為latest時,
// 表示消費新的數據(從consumer創建開始,后生產的數據),之前產生的數據不消費。
// https://blog.csdn.net/u012129558/article/details/80427016
//earliest 當分區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,從頭開始消費。
// latest 當分區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,消費新產生的該分區下的數據。
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, offset);
//不是指每次都拉50條數據,而是一次最多拉50條數據()
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 5);
return propsMap;
}
}@Component
public class KafkaConsumer {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
@KafkaListener(topics = "${kafka.test.topic1}",groupId = "${kafka.test.group1}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition1(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic1 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p1 topic is:{} received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic2}",groupId = "${kafka.test.group2}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition2(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic2 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p2 topic :{},received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic3}",groupId = "${kafka.test.group3}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition3(List<ConsumerRecord<?, ?>> records, Acknowledgment ack) {
logger.info("testTopic3 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
logger.info("p3 topic :{},received message={}",topic, message);
Thread.sleep(300);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
}查看分區消費情況:
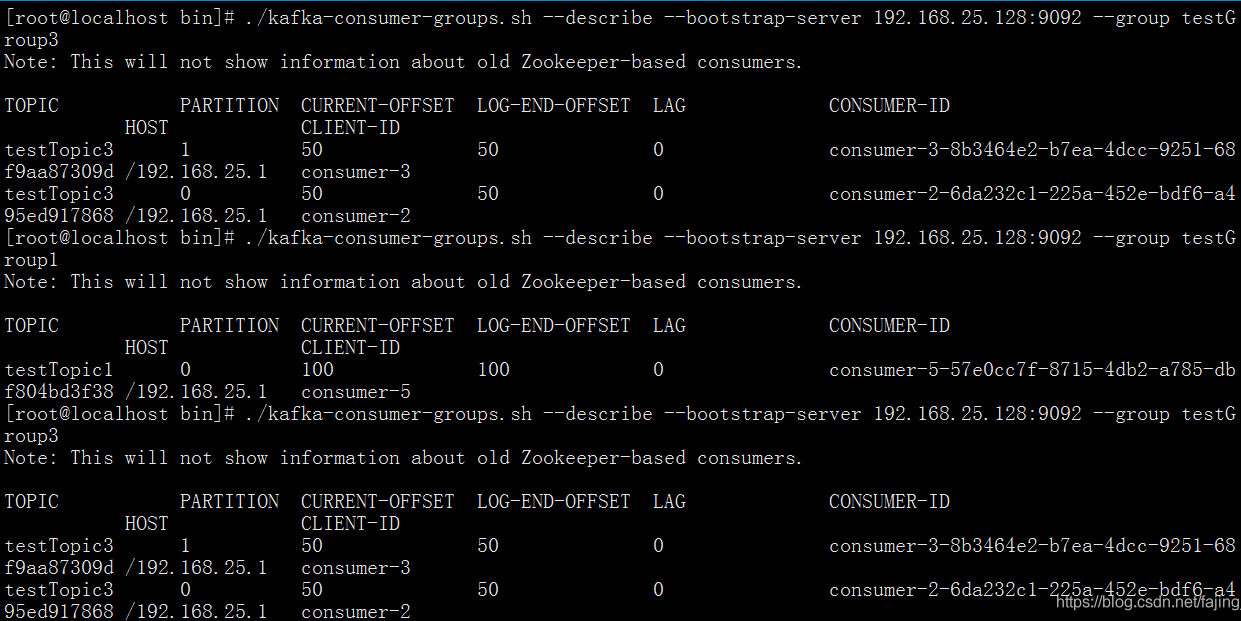
近日,有用戶反饋kafka有topic出現某個消費組消費的時候,有幾個分區一直不消費消息,消息一直積壓(圖1)。除了一直積壓外,還有一個現象就是消費組一直在重均衡,大約每5分鐘就會重均衡一次。具體表現為消費分區的owner一直在改變(圖2)。
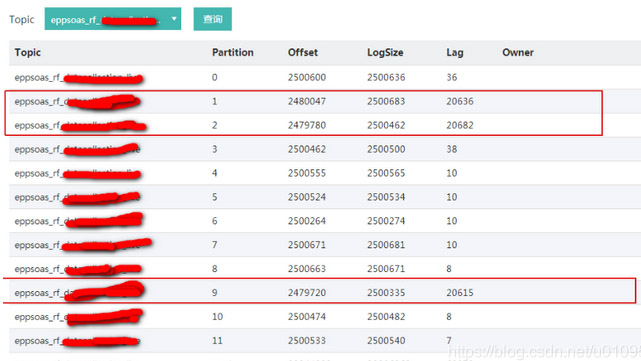
(圖1)
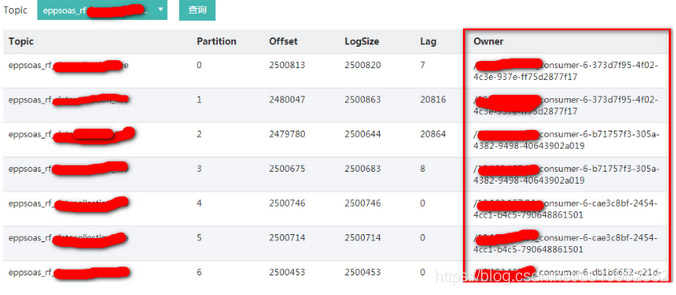
(圖2)
業務側沒有報錯,同時kafka服務端日志也一切正常,同事先將消費組的機器滾動重啟,仍然還是那幾個分區沒有消費,之后將這幾個不消費的分區遷移至別的broker上,依然沒有消費。
還有一個奇怪的地方,就是每次重均衡后,不消費的那幾個分區的消費owner所在機器的網絡都有流量變化。按理說不消費應該就是拉取不到分區不會有流量的。于是讓運維去拉了下不消費的consumer的jstack日志。一看果然發現了問題所在。
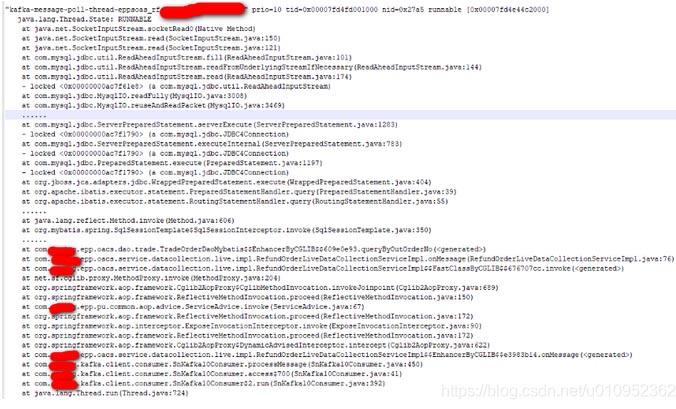
從堆棧看,consumer已經拉取到消息,然后就一直卡在處理消息的業務邏輯上。這說明kafka是沒有問題的,用戶的業務邏輯有問題。
consumer在拉取完一批消息后,就一直在處理這批消息,但是這批消息中有若干條消息無法處理,而業務又沒有超時操作或者異常處理導致進程一直處于消費中,無法去poll下一批數據。
又由于業務采用的是autocommit的offset提交方式,而根據源碼可知,consumer只有在下一次poll中才會自動提交上次poll的offset,所以業務一直在拉取同一批消息而無法更新offset。反映的現象就是該consumer對應的分區的offset一直沒有變,所以有積壓的現象。
至于為什么會一直在重均衡消費組的原因也很明了了,就是因為有消費者一直卡在處理消息的業務邏輯上,超過了max.poll.interval.ms(默認5min),消費組就會將該消費者踢出消費組,從而發生重均衡。
讓業務方去查證業務日志,驗證了積壓的這幾個分區,總是在循環的拉取同一批消息。
臨時解決方法就是跳過有問題的消息,將offset重置到有問題的消息之后。本質上還是要業務側修改業務邏輯,增加超時或者異常處理機制,最好不要采用自動提交offset的方式,可以手動管理。
到此,相信大家對“如何解決kafka消息堆積及分區不均勻的問題”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





