溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何解決Kafka丟了消息問題”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Broker
丟失消息是由于 Kafka 本身的原因造成的,Kafka 為了得到更高的性能和吞吐量,將數據異步批量的存儲在磁盤中。
消息的刷盤過程,為了提高性能,減少刷盤次數,Kafka 采用了批量刷盤的做法。即,按照一定的消息量,和時間間隔進行刷盤。
這種機制也是由于 Linux 操作系統決定的。將數據存儲到 Linux 操作系統種,會先存儲到頁緩存(Page cache)中,按照時間或者其他條件進行刷盤(從 Page Cache 到 file),或者通過 fsync 命令強制刷盤。
數據在Page Cache中時,如果系統掛掉,數據會丟失。
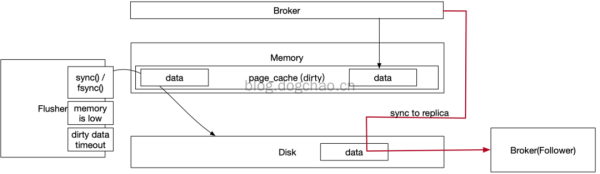
Broker 在 Linux 服務器上高速讀寫以及同步到 Replica
上圖簡述了 Broker 寫數據以及同步的一個過程。Broker 寫數據只寫到 Page Cache 中,而 Page Cache 位于內存。
這部分數據在斷電后是會丟失的。Page Cache 的數據通過 Linux 的 flusher 程序進行刷盤。
刷盤觸發條件有三:
主動調用 sync 或 fsync 函數。
可用內存低于閾值。
dirty data 時間達到閾值。dirty 是 Page Cache 的一個標識位,當有數據寫入到 Page Cache 時,Page Cache 被標注為 dirty,數據刷盤以后,dirty 標志清除。
Broker 配置刷盤機制,是通過調用 fsync 函數接管了刷盤動作。從單個 Broker 來看,Page Cache 的數據會丟失。
Kafka 沒有提供同步刷盤的方式。同步刷盤在 RocketMQ 中有實現,實現原理是將異步刷盤的流程進行阻塞,等待響應,類似 Ajax 的 callback 或者是 Java 的 future。
下面是一段 RocketMQ 的源碼:
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes()); service.putRequest(request); boolean flushOK = request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout()); // 刷盤
也就是說,理論上,要完全讓 Kafka 保證單個 Broker 不丟失消息是做不到的,只能通過調整刷盤機制的參數緩解該情況。
比如,減少刷盤間隔,減少刷盤數據量大小。時間越短,性能越差,可靠性越好(盡可能可靠)。這是一個選擇題。
為了解決該問題,Kafka 通過 Producer 和 Broker 協同處理單個 Broker 丟失參數的情況。
一旦 Producer 發現 Broker 消息丟失,即可自動進行 retry。除非 retry 次數超過閾值(可配置),消息才會丟失。
此時需要生產者客戶端手動處理該情況。那么 Producer 是如何檢測到數據丟失的呢?是通過 ack 機制,類似于 http 的三次握手的方式。
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
acks=0 If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won’t generally know of any failures). The offset given back for each record will always be set to -1.
acks=1 This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.
acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
http://kafka.apache.org/20/documentation.html
以上的引用是 Kafka 官方對于參數 acks 的解釋(在老版本中,該參數是 request.required.acks):
①acks=0,Producer 不等待 Broker 的響應,效率最高,但是消息很可能會丟。
②acks=1,leader broker 收到消息后,不等待其他 follower 的響應,即返回 ack。也可以理解為 ack 數為 1。
此時,如果 follower 還沒有收到 leader 同步的消息 leader 就掛了,那么消息會丟失。
按照上圖中的例子,如果 leader 收到消息,成功寫入 PageCache 后,會返回 ack,此時 Producer 認為消息發送成功。
但此時,按照上圖,數據還沒有被同步到 follower。如果此時 leader 斷電,數據會丟失。
③acks=-1,leader broker 收到消息后,掛起,等待所有 ISR 列表中的 follower 返回結果后,再返回 ack。
-1 等效與 all。這種配置下,只有 leader 寫入數據到 pagecache 是不會返回 ack 的,還需要所有的 ISR 返回“成功”才會觸發 ack。
如果此時斷電,Producer 可以知道消息沒有被發送成功,將會重新發送。如果在 follower 收到數據以后,成功返回 ack,leader 斷電,數據將存在于原來的 follower 中。在重新選舉以后,新的 leader 會持有該部分數據。
數據從 leader 同步到 follower,需要 2 步:
數據從 Page Cache 被刷盤到 disk。因為只有 disk 中的數據才能被同步到 replica。
數據同步到 replica,并且 replica 成功將數據寫入 Page Cache。在 Producer 得到 ack 后,哪怕是所有機器都停電,數據也至少會存在于 leader 的磁盤內。
上面第三點提到了 ISR 的列表的 follower,需要配合另一個參數才能更好的保證 ack 的有效性。
ISR 是 Broker 維護的一個“可靠的 follower 列表”,in-sync Replica 列表,Broker 的配置包含一個參數:min.insync.replicas。
該參數表示 ISR 中最少的副本數。如果不設置該值,ISR 中的 follower 列表可能為空。此時相當于 acks=1。
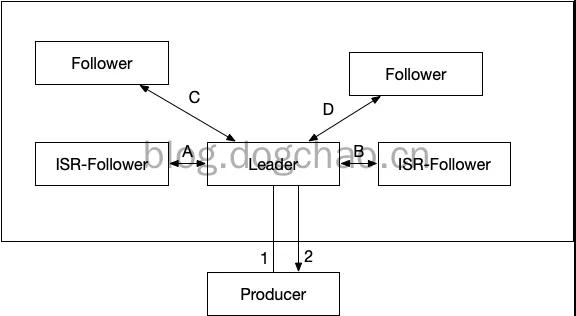
如上圖中:
acks=0,總耗時 f(t)=f(1)。
acks=1,總耗時 f(t)=f(1)+f(2)。
acks=-1,總耗時 f(t)=f(1)+max( f(A) , f(B) )+f(2)。
性能依次遞減,可靠性依次升高。
Producer
Producer丟失消息,發生在生產者客戶端。
為了提升效率,減少 IO,Producer 在發送數據時可以將多個請求進行合并后發送。被合并的請求咋發送一線緩存在本地 buffer 中。
緩存的方式和前文提到的刷盤類似,Producer 可以將請求打包成“塊”或者按照時間間隔,將 buffer 中的數據發出。
通過 buffer 我們可以將生產者改造為異步的方式,而這可以提升我們的發送效率。
但是,buffer 中的數據就是危險的。在正常情況下,客戶端的異步調用可以通過 callback 來處理消息發送失敗或者超時的情況。
但是,一旦 Producer 被非法的停止了,那么 buffer 中的數據將丟失,Broker 將無法收到該部分數據。
又或者,當 Producer 客戶端內存不夠時,如果采取的策略是丟棄消息(另一種策略是 block 阻塞),消息也會被丟失。
抑或,消息產生(異步產生)過快,導致掛起線程過多,內存不足,導致程序崩潰,消息丟失。
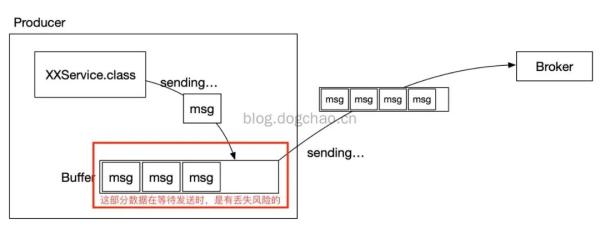
Producer 采取批量發送的示意圖

異步發送消息生產速度過快的示意圖
根據上圖,可以想到幾個解決的思路:
異步發送消息改為同步發送消。或者 service 產生消息時,使用阻塞的線程池,并且線程數有一定上限。整體思路是控制消息產生速度。
擴大 Buffer 的容量配置。這種方式可以緩解該情況的出現,但不能杜絕。
service 不直接將消息發送到 buffer(內存),而是將消息寫到本地的磁盤中(數據庫或者文件),由另一個(或少量)生產線程進行消息發送。相當于是在 buffer 和 service 之間又加了一層空間更加富裕的緩沖層。
Consumer
Consumer 消費消息有下面幾個步驟:
接收消息
處理消息
反饋“處理完畢”(commited)
Consumer的消費方式主要分為兩種:
自動提交 offset,Automatic Offset Committing
手動提交 offset,Manual Offset Control
Consumer 自動提交的機制是根據一定的時間間隔,將收到的消息進行 commit。commit 過程和消費消息的過程是異步的。
也就是說,可能存在消費過程未成功(比如拋出異常),commit 消息已經提交了。此時消息就丟失了。
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); // 自動提交開關 props.put("enable.auto.commit", "true"); // 自動提交的時間間隔,此處是1s props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("foo", "bar")); while (true) { // 調用poll后,1000ms后,消息狀態會被改為 committed ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) insertIntoDB(record); // 將消息入庫,時間可能會超過1000ms上面的示例是自動提交的例子。如果此時,insertIntoDB(record) 發生異常,消息將會出現丟失。
接下來是手動提交的例子:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); // 關閉自動提交,改為手動提交 props.put("enable.auto.commit", "false"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("foo", "bar")); final int minBatchSize = 200; List<ConsumerRecord<String, String>> buffer = new ArrayList<>(); while (true) { // 調用poll后,不會進行auto commit ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { buffer.add(record); } if (buffer.size() >= minBatchSize) { insertIntoDb(buffer); // 所有消息消費完畢以后,才進行commit操作 consumer.commitSync(); buffer.clear(); }將提交類型改為手動以后,可以保證消息“至少被消費一次”(at least once)。但此時可能出現重復消費的情況,重復消費不屬于本篇討論范圍。
上面兩個例子,是直接使用 Consumer 的 High level API,客戶端對于 offset 等控制是透明的。
也可以采用 Low level API 的方式,手動控制 offset,也可以保證消息不丟,不過會更加復雜。
try { while(running) { ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE); for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { System.out.println(record.offset() + ": " + record.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 精確控制offset consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1))); } } } finally { consumer.close(); }“如何解決Kafka丟了消息問題”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





