溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“JVM內存回收和內存分配方式”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
一、前言
1.1 計算機==>操作系統==>JVM
1.1.1 虛擬與實體(對上圖的結構層次分析)
1.1.2 Java程序執行(對上圖的箭頭流程分析)
二、JVM內存空間與參數設置
2.1 運行時數據區
2.2 關于StackOverflowError和OutOfMemoryError
2.2.1 StackOverflowError
2.2.2 OutOfMemoryError
2.3 JVM堆內存和非堆內存
2.3.1 堆內存和非堆內存
2.3.2 JVM堆內部構型(新生代和老年代)
2.4 JVM堆參數設置
2.4.1 JVM重要參數
2.4.2 JVM其他參數
2.5 從日志看JVM(開發實踐)
三、HotSpot VM
3.1 HotSpot VM相關知識
3.2 HotSpot VM的兩個實現與查看本機HotSpot
四、JVM內存回收
4.1 垃圾收集算法(內存回收理論)
4.1.1 標記-清除算法
4.1.2 復制算法
4.1.3 標志-整理算法(復制算法變更后在老年代的應用)
4.1.4 分代收集算法
4.2 垃圾收集器(內存回收實踐)
4.2.1 常用組合1:Serial + serial old 新生代和老年代都是單線程,簡單
4.2.2 常用組合2:ParNew+ serial old 新生代多線程,老年代單線程,簡單
4.2.3 常用組合3:Parallel scavenge + Parallel old 新生代和老年代都是多線程,該組合完成吞吐量優先虛擬機,適用于后臺計算
4.2.4 常用組合4:cms收集器 多線程,完成響應時間短虛擬機,適用于用戶交互
4.2.5 常用組合5:G1收集器 多線程,面向服務端的垃圾回收器
4.3 垃圾收集器常用參數
五、JVM內存分配
5.1 對象優先在Eden上分配
5.1.1 設置VM Options
5.1.2 程序輸出(給出附加解釋)
5.2 大對象直接進入老年代(使用-XX:PretenureSizeThreshold參數設置)
5.2.1 設置VM Options
5.2.2 程序輸出(給出附加解釋)
5.3 長期存活的對象應該進入老年代(使用-XX:MaxTenuringThreshold參數設置)
5.3.1 設置VM Options
5.3.2 程序輸出(給出附加解釋)
六、尾聲
對于Java虛擬機在內存分配與回收的學習,如果讀者大學時代沒有偷懶的話,操作系統和計算機組成原理這兩門功課學的比較好的話,理解起來JVM是比較容易的,只要底子還在,很多東西都可以觸類旁通。
JVM全稱為Java Virtual Machine,譯為Java虛擬機,讀者會問,虛擬機虛擬的是誰呢?即虛擬是對什么東西的虛擬,即實體是什么,是如何虛擬的?下面讓我們來看看“虛擬與實體”。
關于計算機、操作系統、JVM三者關系,如下圖:
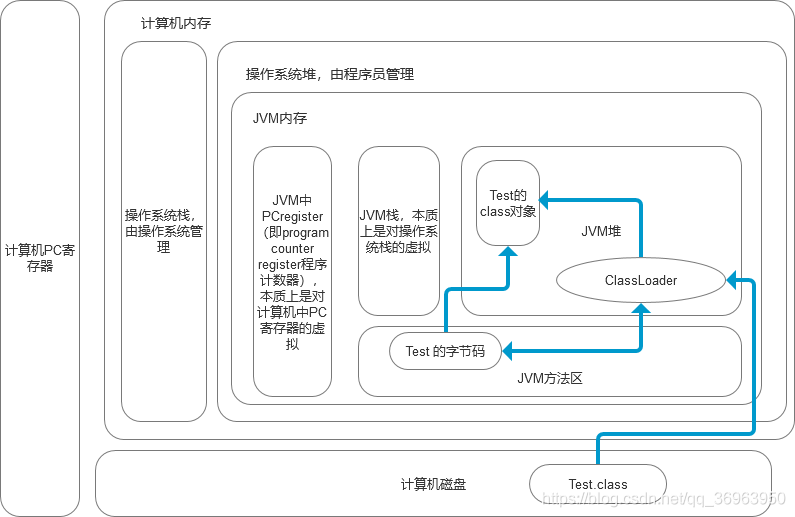
JVM之所以稱為之虛擬機,是因為它是實現了計算機的虛擬化。下表展示JVM位于操作系統堆內存中,分別實現的了對操作系統和計算機的虛擬化。
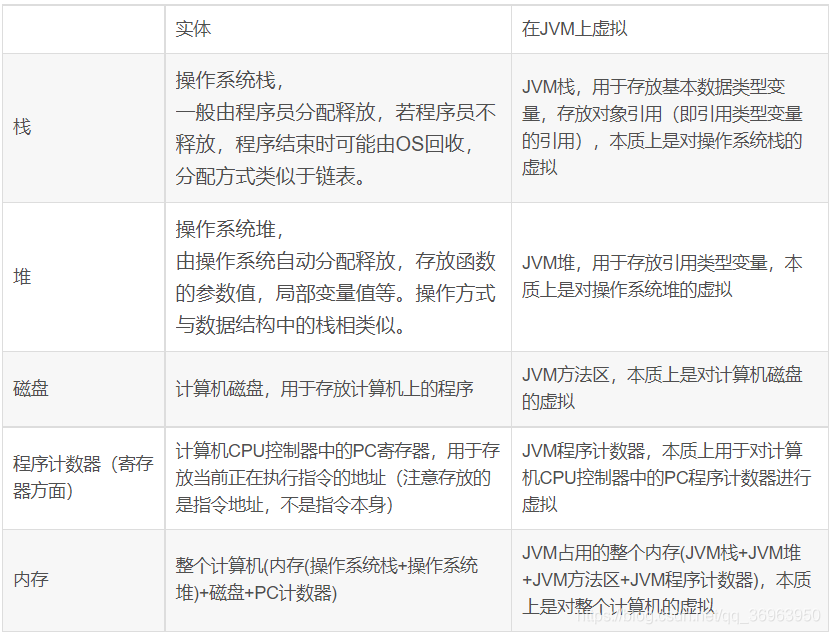
操作系統棧對應JVM棧,操作系統堆對應JVM堆,計算機磁盤對應JVM方法區,存放字節碼對象,計算機PC寄存器對應JVM程序計數器(注意:計算機PC寄存器是下一條指令地址,JVM程序計數器是當前指令的地址),
唯一不同的是,整個計算機(內存(操作系統棧+操作系統堆)+磁盤+PC計數器)對應JVM占用的整個內存(JVM棧+JVM堆+JVM方法區+JVM程序計數器)。
上圖中不僅是結構圖,展示JVM的虛擬和實體的關系,也是一個流程圖,上圖中的箭頭展示JVM對一個對象的編譯執行。
程序員寫好的類加載到虛擬機執行的過程是:當一個classLoder啟動的時候,classLoader的生存地點在JVM中的堆,首先它會去主機硬盤上將Test.class裝載到JVM的方法區,方法區中的這個字節文件會被虛擬機拿來new Test字節碼(),然后在堆內存生成了一個Test字節碼的對象,最后Test字節碼這個內存文件有兩個引用一個指向Test的class對象,一個指向加載自己的classLoader。整個過程上圖用箭頭表示,這里做說明。
就像本文開始時說過的,有了計算機組成原理和操作系統兩門課的底子,學起JVM的時候會容易許多,因為JVM本質上就是對計算機和操作系統的虛擬,就是一個虛擬機。
Java正是有了這一套虛擬機的支持,才成就了跨平臺(一次編譯,永久運行)的優勢。
這樣一來,前言部分我們成功引入JVM,接下來,本文要講述的重點是JVM自動內存管理,先給出總述:
JVM自動內存管理=分配內存(指給對象分配內存)+回收內存(回收分配給對象的內存)
上面公式告訴我們,JVM自動內存管理分為兩塊,分配內存和回收內存
JVM在執行Java程序的過程中會把它所管理的內存劃分為若干個不同的運行時數據區域。這些運行時數據區包括方法區、堆、虛擬棧、本地方法棧、程序計數器,如圖:
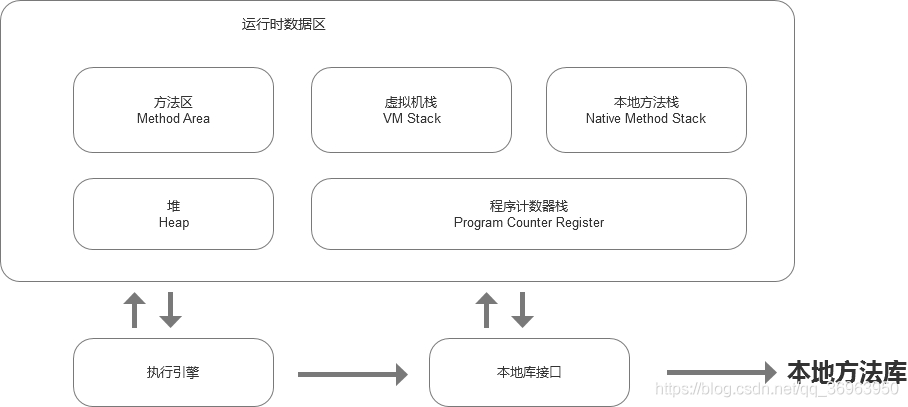
讓我們一步步介紹,對于運行時數據區,很多博客都是使用順序介紹的方式,不利于讀者對比比較學習,這里筆者以表格的方式呈現:
| 程序計數器 | Java虛擬機棧 | 本地方法棧 | Java 堆 | 方法區 | |
|---|---|---|---|---|---|
| 存放內容 | JVM字節碼指令的地址或Undefined(如果線程正在執行一個 Java 方法,這個計數器記錄的是正在執行的虛擬機字節碼指令的地址;如果正在執行的是 Native 方法,這個計數器的值則為 (Undefined)) | 局部變量表、操作數棧、動態鏈接、方法出口 | Native方法(本地方法) | 對象實例、數組 | 類信息、常量、靜態變量、即時編譯器編譯后的代碼 |
| 用途 | 字節碼解釋器工作是就是通過改變這個計數器的值來選取下一條需要執行指令的字節碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴計數器完成 | 每個方法在執行時都會創建一個棧幀(Stack Frame)用于存儲局部變量表、操作數棧、動態鏈接、方法出口等信息。每一個方法從調用直至執行結束,就對應著一個棧幀從虛擬機棧中入棧到出棧的過程。 | 每一個本地方法的調用執行過程,就對應著一個棧幀從本地方法棧中入棧到出棧的過程。 | 用于存放對象實例,被對象引用所指向 | 存儲一個類型所使用到的所有類型,域和方法的符號引用,在java程序的動態鏈接中起核心作用 |
| 線程共享還是私有 | 線程私有 | 線程私有 | 線程私有 | 線程間共享 | 線程間共享 |
| StackOverflowError棧溢出 | 線程請求的棧深度大于虛擬機所允許的深度。報錯信息:java.lang.StackOverflowError | 線程請求的棧深度大于虛擬機所允許的深度。報錯信息:java.lang.StackOverflowError | 線程請求的棧深度大于虛擬機所允許的深度。報錯信息:java.lang.StackOverflowError | 無 | 無 |
| OutOfMemoryError內存泄露 | 無 | 如果虛擬機棧可以動態擴展,而擴展時無法申請到足夠的內存。報錯信息:java.lang.OutOfMemoryError:unable to create new native thread | 如果虛擬機棧可以動態擴展,而擴展時無法申請到足夠的內存。報錯信息:java.lang.OutOfMemoryError:unable to create new native thread | 如果堆中沒有內存完成實例分配,并且堆也無法再擴展時,拋出該異常。報錯信息:java.lang.OutOfMemoryError: Java heap space | 當方法區無法滿足內存分配需求,拋出該異常。報錯信息:java.lang.OutOfMemoryError: PermGen space |
| 特點 | 是五個區域中唯一一個沒有OutOfMemoryError | Java虛擬機棧和本地方法棧都是方法調用棧,不同之處在于是一個是程序員編寫的Java方法,一個是自帶Native方法。 | Java虛擬機棧和本地方法棧都是方法調用棧,不同之處在于是一個是程序員編寫的Java方法,一個是自帶Native方法。 | 1、可以位于物理上不連續的空間,但是邏輯上要連續。2、Java堆又稱為CG堆,分為新生區和老年區,新生區又分為Eden區、From Survivor區和To Survivor | 又稱為Non-Heap,非堆,與Java堆區分開來, |
讓我們對上表繼續深入,講述上表中的StackOverflowError和OutOfMemoryError。
對于運行時數據區的五個區域,如果討論生命周期,一般討論 堆 和 方法區,因為其他三個是線程私有的,生命周期很簡單;
如果討論垃圾回收算法和垃圾收集器,一般只討論 堆,因為方法區里面存放的是要存活比較久的數據,其他兩個棧和一個程序計數器僅保存了引用,只有堆中才是實際分配對象的,而要回收的就是對象;
如果討論 棧溢出,只討論本地方法棧和虛擬機棧,還有程序計數器;如果討論 內存泄漏,討論后面四個,唯獨不討論程序計數器。
方法區 是 堆 邏輯的一部分,存放一些 類信息、常量、靜態變量、即時編譯器編譯后的代碼 ,為什么這些東西放到 方法區 里面而不是放到堆里面,因為這些是用很久的,不用回收的,所以這里沒有放到堆上(堆分為年輕代和老年代),經常要回收,所以里面只能放經常要回收的對象,又按照對象存活時間分為年輕代和老年代。
方法區JDK8之后變為直接內存,理由在于
運行時數據區中,拋出棧溢出的就是虛擬機棧和本地方法棧,
產生原因:線程請求的棧深度大于虛擬機所允許的深度。因為JVM棧深度是有限的而不是無限的,但是一般的方法調用都不會超過JVM的棧深度,如果出現棧溢出,基本上都是代碼層面的原因,如遞歸調用沒有設置出口或者無限循環調用。
解決方法:程序員檢查代碼是否有無限循環即可。
容易發生OutOfMemoryError內存溢出問題的內存空間包括:Permanent Generation space和Heap space。
1、第一種java.lang.OutOfMemoryError: PermGen space(方法區拋出)
產生原因:發生這種問題的原意是程序中使用了大量的jar或class,使java虛擬機裝載類的空間不夠,與Permanent Generation space有關。所以,根本原因在于jar或class太多,方法區堆溢出,則解決方法有兩個種,要么增大方法區,要么減少jar、class文件,且看解決方法。
解決方法:
從增大方法區方面入手:
增加java虛擬機中的XX:PermSize和XX:MaxPermSize參數的大小,其中XX:PermSize是初始永久保存區域大小,XX:MaxPermSize是最大永久保存區域大小。
如web應用中,針對tomcat應用服務器,在catalina.sh 或catalina.bat文件中一系列環境變量名說明結束處增加一行:
JAVA_OPTS=" -XX:PermSize=64M -XX:MaxPermSize=128m"
可有效解決web項目的tomcat服務器經常宕機的問題。
從減少jar、class文件入手:
清理應用程序中web-inf/lib下的jar,如果tomcat部署了多個應用,很多應用都使用了相同的jar,可以將共同的jar移到tomcat共同的lib下,減少類的重復加載。
2、第二種OutOfMemoryError: Java heap space(堆拋出)
產生原因:發生這種問題的原因是java虛擬機創建的對象太多,在進行垃圾回收之間,虛擬機分配的到堆內存空間已經用滿了,與Heap space有關。所以,根本原因在于對象實例太多,Java堆溢出,則解決方法有兩個種,要么增大堆內存,要么減少對象示例,且看解決方法。
解決方法:
1.從增大堆內存方面入手:
增加Java虛擬機中Xms(初始堆大小)和Xmx(最大堆大小)參數的大小。如:set JAVA_OPTS= -Xms256m -Xmx1024m
2.從減少對象實例入手:
一般來說,正常程序的對象,堆內存時絕對夠用的,出現堆內存溢出一般是死循環中創建大量對象,檢查程序,看是否有死循環或不必要地重復創建大量對象。找到原因后,修改程序和算法。
3、第三種OutOfMemoryError:unable to create new native thread(Java虛擬機棧、本地方法棧拋出)
產生原因:這個異常問題本質原因是我們創建了太多的線程,而能創建的線程數是有限制的,導致了異常的發生。能創建的線程數的具體計算公式如下:
(MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize) = Number of threads
注意:MaxProcessMemory 表示一個進程的最大內存,JVMMemory 表示JVM內存,ReservedOsMemory 表示保留的操作系統內存,ThreadStackSize 表示線程棧的大小。
在java語言里, 當你創建一個線程的時候,虛擬機會在JVM內存創建一個Thread對象同時創建一個操作系統線程,而這個系統線程的內存用的不是JVMMemory,而是系統中剩下的內存(MaxProcessMemory - JVMMemory - ReservedOsMemory)。由公式得出結論:你給JVM內存越多,那么你能創建的線程越少,越容易發生 java.lang.OutOfMemoryError: unable to create new native thread
解決方法:
1.如果程序中有bug,導致創建大量不需要的線程或者線程沒有及時回收,那么必須解決這個bug,修改參數是不能解決問題的。
2.如果程序確實需要大量的線程,現有的設置不能達到要求,那么可以通過修改MaxProcessMemory,JVMMemory,ThreadStackSize這三個因素,來增加能創建的線程數:MaxProcessMemory 表示使用64位操作系統,VMMemory 表示減少 JVMMemory 的分配,ThreadStackSize 表示減小單個線程的棧大小。
JVM內存劃分為堆內存和非堆內存,堆內存分為年輕代(Young Generation)、老年代(Old Generation),非堆內存就一個永久代(Permanent Generation)。
年輕代又分為Eden和Survivor區。Survivor區由FromSpace和ToSpace組成。Eden區占大容量,Survivor兩個區占小容量,默認比例是8:1:1。
堆內存用途:存放的是對象,垃圾收集器就是收集這些對象,然后根據GC算法回收。
非堆內存用途:永久代,也稱為方法區,存儲程序運行時長期存活的對象,比如類的元數據、方法、常量、屬性等。
在JDK1.8版本廢棄了永久代,替代的是元空間(MetaSpace),元空間與永久代上類似,都是方法區的實現,他們最大區別是:永久代使用的是JVM的堆內存空間,而元空間使用的是物理內存,直接受到本機的物理內存限制。在后面的實踐中,因為筆者使用的是JDK8,所以打印出的GC日志里面就有MetaSpace。
Jdk8中已經去掉永久區,這里為了與時俱進,不再贅余。

上圖演示Java堆內存空間,分為新生代和老年代,分別占Java堆1/3和2/3的空間,新生代中又分為Eden區、Survivor0區、Survivor1區,分別占新生代8/10、1/10、1/10空間。
問題1:什么是Java堆?
回答1:JVM規范中說到:”所有的對象實例以及數組都要在堆上分配”。Java堆是垃圾回收器管理的主要區域,百分之九十九的垃圾回收發生在Java堆,另外百分之一發生在方法區,因此又稱之為”GC堆”。根據JVM規范規定的內容,Java堆可以處于物理上不連續的內存空間中。
問題2:為什么Java堆要分為新生代和老年代?
回答2:當前JVM對于堆的垃圾回收,采用分代收集的策略。根據堆中對象的存活周期將堆內存分為新生代和老年代。在新生代中,每次垃圾回收都有大批對象死去,只有少量存活。而老年代中存放的對象存活率高。這樣劃分的目的是為了使 JVM 能夠更好的管理堆內存中的對象,包括內存的分配以及回收。
問題3:為什么新生代要分為Eden區、Survivor0區、Survivor1區?
回答3:這是結構與策略相適應的原則,新生代垃圾收集使用的是復制算法(一種垃圾收集算法,Serial收集器、ParNew收集器、Parallel scavenge收集器都是用這種算法),復制算法可以很好的解決垃圾收集的內存碎片問題,但是有一個天然的缺陷,就是要犧牲一半的內存(即任意時刻只有一半內存用于工作),這對于寶貴的內存資源來說是極度奢侈的。新生代在使用復制算法作為其垃圾收集算法的時候,對其做了優化,拿出2/10的新生代的內存作為交換區,稱為Survivor0區和Survivor1區(注意:有的博客上稱為From Survivor Space和To Survivor Space,這樣闡述也是對的,但是容易對初學者形成誤導,因為在復制算法中,復制是雙向的,沒有固定的From和To,這一次是由這一邊到另一邊,下次就是從另一邊到這一邊,使用From Survivor Space和To Survivor Space容易讓后來學習者誤以為復制只能從一邊到另一邊,當然有的博客中會附加不管從哪邊到哪邊,起始就是From,終點就是To,即From Survivor Space和To Survivor Space所對應的區循環對調,但是讀者不一定想的明白。所以筆者這里使用Survivor0、Survivor1,減少誤解)
所以說,新生代在結構上分為Eden區、Survivor0區、Survivor1區,是與其使用的垃圾收集算法(復制算法)相適應的結果。
問題4:關于永久區Permanent Space?
回答4:Jdk8中取消了永久區Permanent Space,使用 元數據空間metaspace,使用直接內存…
問題:什么是老年代擔保機制?
回答:因為新生代和老年代是1:2,如果在eden區放不下,會放到老年區,如果minor gc的時候,survivor區放不下,也會放到老年區,所有,有時候會在老年區里面有 不少gc年齡比較小 的大對象,就是因為年輕代放不下了,老年代擔保機制多次觸發會增加老年代負擔,過早地觸發major gc,說明當前的 eden survivor 比例設置不太好。
問題:為什么eden:survivor1:survivor2=8:1:1?
回答:這個可以設置的,VM Options: -XX:SurvivorRatio=8 新生代中Eden區域與Survivor區域的容量比值,默認為8,代表Eden:Survivor=8:1。如果eden區域占比小,那么minor gc會比較頻繁,gc線程是占用cpu資源的,是stop the world的,不好;如果eden區域占比大,則survivor區域變小了,survivor區滿了也會觸發老年代擔保機制。
Minor GC觸發條件:eden區滿時,觸發MinorGC。即申請一個對象時,發現eden區不夠用,則觸發一次MinorGC。在MinorGC時,將小于 to space大小的存活對象復制到 to space(如果to space區域不夠,則利用擔保機制進入老年代區域),然后to space和from space換位置,所以我們看到的to space一直是空的。
問題:為什么年輕代age是0~15,到了16就移動到老年代?
回答:對象頭中用四個bit位存放分代年齡,所以就是 0~15。
無論是對象大小還是對象年輕,進入老年代的閾值都是可以用參數設置的,VM Options: -XX:PretenureSizeThreshold=3145728,表示大于3MB都到老年代中去;VM Options: -XX:MaxTenuringThreshold=2,表示經歷兩次Minor GC,就到老年代中去。
問題:虛擬機怎么知道哪個對象要回收,哪個對象不回收?
回答:兩種方式:要么 引用計數 ,要么 根節點+可達性分析。
引用計數:這種方式有循環引用的問題,Java中不使用,python是使用。
解釋一下引用計數,一般來說,java要回收的對象要求是沒有引用指向的,就是程序中沒有了用的對象,才可以回收,要求gc不影響程序。看一個循環引用的問題:
public class Main1 {
public static void main(String[] args) {
A a = new A();
B b = new B(); // 這個時候 new A()對象和new B()對象引用計數為1,就是a b
a.instance = b;
b.instance = a; // 這個時候 new A()對象和new B()對象引用計數為2,就是a b a.instance b.instance
a = null;
b = null; // 這個時候 new A()對象和new B()對象已經沒有引用了,但是引用計數仍然為1,instance還在指向
}
}
class A {
B instance;
}
class B {
A instance;
}對于 根節點+可達性分析,確定若干個根節點,從根節點出發,可以達到的就是可達的引用,所指向的對象不可回收,反之可以回收。如圖:
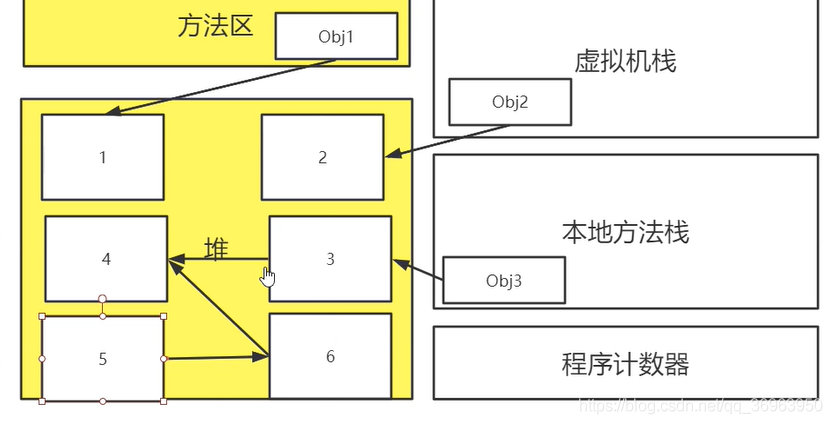
obj1 引用指向對象1,obj2 引用指向對象2,obj3 引用指向對象3,而對象3 中又引用 對象4,對象5 不是 gc root,所以 對象5 和 對象6 都在可達性鏈 中。最終,對象1 對象2 對象3 對象4 都是可達的,不會被垃圾收集器回收,對象5 對象6 是不可達的,要被垃圾收集器回收。
這些都是和堆內存分配有關的參數,所以我們放在第二部分了,和垃圾收集器有關的參數放在第四部分。
舉例:java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m
因為整個堆大小=年輕代大小(新生代大小) + 年老代大小 + 持久代大小,
-Xmn2g:表示年輕代大小為2G。持久代一般固定大小為64m,所以增大年輕代后,將會減小年老代大小。此值對系統性能影響較大,Sun官方推薦配置為整個堆的3/8。
-XX:NewRatio=4:設置年輕代(包括Eden和兩個Survivor區)與年老代的比值(除去持久代)。這里設置為4,表示年輕代與年老代所占比值為1:4,又因為上面設置年輕代為2G,則老年代大小為8G
-XX:SurvivorRatio=8:設置年輕代中Eden區與Survivor區的大小比值。這里設置為8,則兩個Survivor區與一個Eden區的比值為2:8,一個Survivor區占整個年輕代的1/10
則Eden:Survivor0:Survivor1=8:1:1
-XX:MaxPermSize=16m:設置持久代大小為16m。
所有整個堆大小=年輕代大小 + 年老代大小 + 持久代大小= 2G+ 8G+ 16M=10G+6M=10246MB
-Xmx3550m:設置JVM最大可用內存為3550M。
-Xms3550m:設置JVM促使內存為3550m,此值可以設置與-Xmx相同。
-Xss128k:設置每個線程的堆棧大小。JDK5.0以后每個線程堆棧大小為1M,以前每個線程堆棧大小為256K。更具應用的線程所需內存大小進行調整。在相同物理內存下,減小這個值能生成更多的線程。但是操作系統對一個進程內的線程數還是有限制的,不能無限生成,經驗值在3000~5000左右。
關于為什么-xmx與-xms的大小設置為一樣的?
首先,在Java堆內存分配中,-xmx用于指定JVM最大分配的內存,-xms用于指定JVM初始分配的內存,所以,-xmx與-xms相等表示JVM初次分配的內存的時候就把所有可以分配的最大內存分配給它(指JVM),這樣的做的好處是:
避免JVM在運行過程中、每次垃圾回收完成后向OS申請內存:因為所有的可以分配的最大內存第一個就給它(JVM)了。
延后啟動后首次GC的發生時機、減少啟動初期的GC次數:因為第一次給它分配了最大的;
盡可能避免使用swap space:swap space為交換空間,當web項目部署到linux上時,有一條調優原則就是“盡可能使用內存而不是交換空間”
設置堆內存為不可擴展和收縮,避免在每次GC 后調整堆的大小
影響堆內存擴展與收縮的兩個參數
| MaxHeapFreeRadio | MinHeapFreeRadio |
|---|---|
| 默認值為70 | 默認值為40 |
| 當xmx值比xms值大,堆可以動態收縮與擴展,這個參數控制當堆空間大于指定比例時會自動收縮,默認表示堆空間大于70%會自動收縮 | 當xmx值比xms值大,堆可以動態收縮與擴展,這個參數控制當堆空間小于指定比例時會自動擴展,默認表示堆空間小于40%會自動擴展 |
由上表可知,堆內存默認是自動擴展和收縮的,但是有一個前提條件,就是到xmx比xms大的時候,當我們將xms設置為和xmx一樣大,堆內存就不可擴展和收縮了,即整個堆內存被設置為一個固定值,避免在每次GC 后調整堆的大小。
附加:在Java非堆內存分配中,一般是用永久區內存分配:
JVM 使用 -XX:PermSize 設置非堆內存初始值,由 -XX:MaxPermSize 設置最大非堆內存的大小。
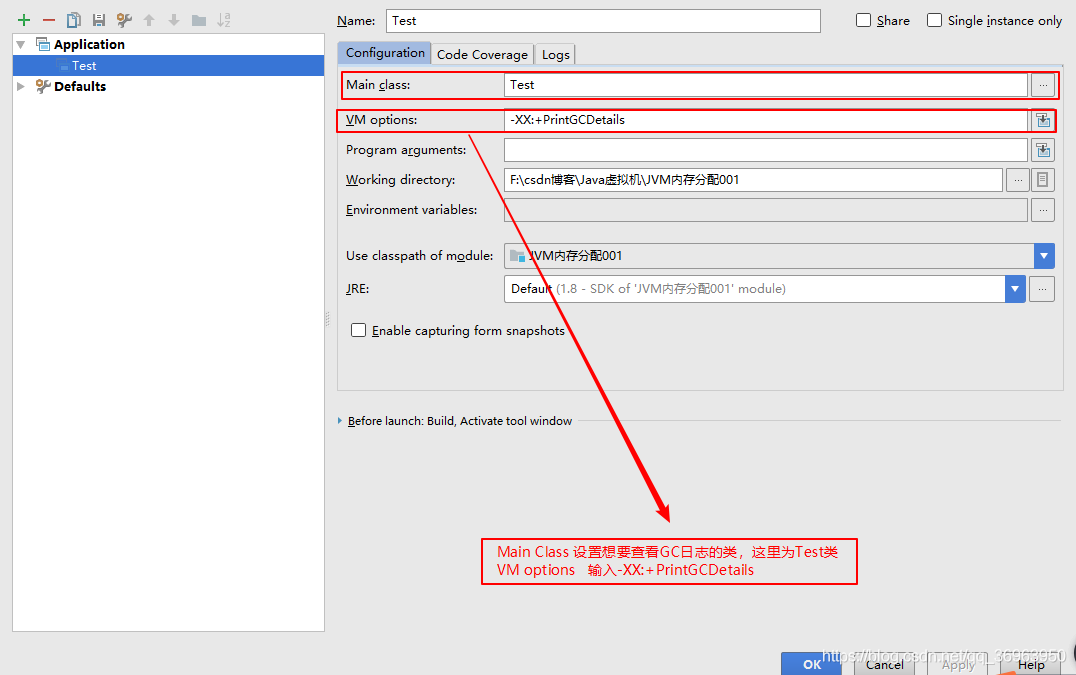
這里了設置GC日志關聯的類和將GC日志打印
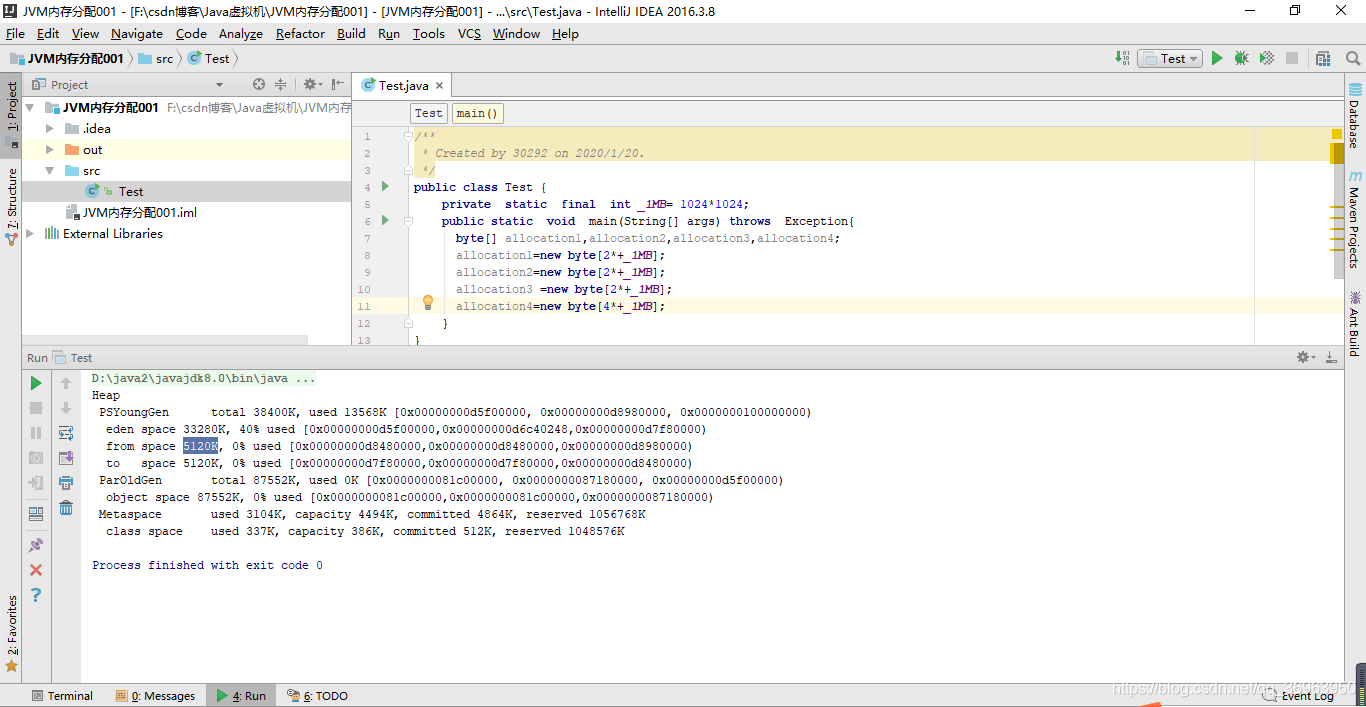
如程序所述,申請了10MB的空間,allocation1 2MB+allocation2 2MB+allocation3 2MB+allocation4 4MB=10MB
接下來我們開始閱讀GC日志,這里筆者以自己電腦上打印的GC日志為例,講述閱讀GC日志的方法:
heap表示堆,即下面的日志是對JVM堆內存的打印;
因為使用的是jdk8,所以默認使用ParallelGC收集器,也就是在新生代使用Parallel Scavenge收集器,老年代使用ParallelOld收集器
PSYoungGen 表示使用Parallel scavenge收集器作為年輕代收集器,ParOldGen表示使用Parallel old收集器作為老年代收集器,即筆者電腦上默認是使用Parallel scavenge+Parallel old收集器組合。
其中,PSYoungGen總共38400K(37.5MB),被使用了13568K(13.25MB),PSYoungGen又分為Eden Space 33280K(32.5MB) 被使用了40% 13MB,from space 5120K(5MB)和to space 5120K(5MB),這就是一個eden區和兩個survivor區。
此處注意,因為使用的是jdk8,所以沒有永久區了,只有MetaSpace,見上圖。
問題一:什么是HotSpot虛擬機?HotSpot VM的前世今生?
回答一:HotSpot VM是由一家名為“Longview Technologies”的公司設計的一款虛擬機,Sun公司收購Longview Technologies公司后,HotSpot VM成為Sun主要支持的VM產品,Oracle公司收購Sun公司后,即在HotSpot的基礎上,移植JRockit的優秀特性,將HotSpot VM與JRockit VM整合到一起。
問題二:HotSpot VM有何優點?
回答二:HotSpot VM的熱點代碼探測能力可以通過執行計數器找出最具有編譯價值的代碼,然后通知JIT編譯器以方法為單位進行編譯。如果一個方法被頻繁調用,或方法中有效循環次數很多,將會分別觸發標準編譯和OSR(棧上替換)編譯動作。 通過編譯器與解釋器恰當地協同工作,可以在最優化的程序響應時間與最佳執行性能中取得平衡,而且無須等待本地代碼輸出才能執行程序,即時編譯的時間壓力也相對減小,這樣有助于引入更多的代碼優化技術,輸出質量更高的本地代碼。
問題三:HotSpot VM與JVM是什么關系?
回答三:今天的HotSpot VM,是Sun JDK和OpenJDK中所帶的虛擬機,也是目前使用范圍最廣的Java虛擬機。
HotSpot VM包括兩個實現,不同的實現適合不同的場景:
Java HotSpot Client VM:通過減少應用程序啟動時間和內存占用,在客戶端環境中運行應用程序時可以獲得最佳性能。此經過專門調整,可縮短應用程序啟動時間和內存占用,使其特別適合客戶端環境。此jvm實現比較適合我們平時用作本地開發,平時的開發不需要很大的內存。
Java HotSpot Server VM:旨在最大程度地提高服務器環境中運行的應用程序的執行速度。此jvm實現經過專門調整,可能是特別調整堆大小、垃圾回收器、編譯器那些。用于長時間運行的服務器程序,這些服務器程序需要盡可能快的運行速度,而不是快速啟動時間。
只要電腦上安裝jdk,我們就可以看到hotspot的具體實現:
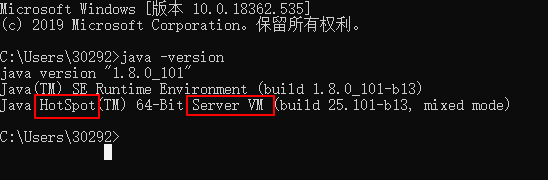
我們知道,Java中是沒有析構函數的,既然沒有析構函數,那么如何回收對象呢,答案是自動垃圾回收。Java語言的自動回收機制可以使程序員不用再操心對象回收問題,一切都交給JVM就好了。那么JVM又是如何做到自動回收垃圾的呢,且看本節,本節分為兩個部分——垃圾收集算法和垃圾收集器,其中,收集算法是內存回收的理論,而垃圾回收器是內存回收的實踐。
垃圾收集策略兩個目的:gc次數少,gc時間短,不同的收集算法和收集器側重不同。
標記-清除算法分為兩個階段,“標記”和“清除”,
標記:首先標記出所有需要回收的對象;
清除:在標記完成后統一回收所有被標記的對象。
“標記-清除”算法的不足:第一,效率問題,標記和清除兩個過程的效率都不會太高;第二,空間問題,標記清除后產生大量不連續的內存碎片,這些內存空間碎片可能會導致以后程序運行過程中需要分配較大對象時,無法找到足夠的連續內存而不得不提前觸發一次垃圾收集動作,如果很容易出現這樣的空間碎片多、無法找到大的連續空間的情況,垃圾收集就會較為頻繁。
為了解決“標記-清除算法”的效率問題,一種復制算法產生了,它將當前可用內存按容量劃分為大小相等的兩塊,每次只使用其中一塊。當一塊的內存用完了,就將還活著的對象復制到另一塊上面,然后再把已使用的內存空間一次清除掉。這樣使得每次都對整個半區進行內存回收,內存分配時就不用考慮內存碎片等復雜情況,只要移動堆頂指針,按順序分配內存即可。
這種算法處理內存碎片的核心在于將整個半塊中活的的對象復制到另一整個半塊上面去,所以稱為復制算法。
附:關于復制算法的改進
復制算法合理的解決了內存碎片問題,但是卻要以犧牲一半的寶貴內存為代價,這是非常讓人心疼的。令人愉快地是,現代虛擬機中,早就有了關于復制算法的改進:
對于Java堆中新生代中的對象來說,99%的對象都是“朝升夕死”的,就是說很多的對象在創建出來后不久就會死掉了,所有我們可以大膽一點,不需要按照1:1的比例來劃分內存空間,而是將新生代的內存劃分為一塊較大的Eden區(一般占新生代8/10的大小)和兩塊較小的Survivor區(用于復制,一般每塊占新生代1/10的大小,兩塊占新生代2/10的大小)。當回收時,將Eden區和Survivor里面當前還活著的對象全部都復制到另一塊Survivor中(關于另一個塊Survivor是否會溢出的問題,答案是不會,這里將新生代90%的容量里的對象復制到10%的容量里面,確實是有風險的,但是JVM有一種內存的分配擔保機制,即當目的Survivor空間不夠,會將多出來的對象放到老年代中,因為老年代是足夠大的),最后清理Eden區和源Survivor區的空間。這樣一來,每次新生代可用內存空間為整個新生代90%,只有10%的內存被浪費掉,
正是因為這一特性,現代虛擬機中采用復制算法來回收新生代,如Serial收集器、ParNew收集器、Parallel scavenge收集器均是如此。
對于新生代來說,由于具有“99%的對象都是朝生夕死的”這一特點,所以我們可以大膽的使用10%的內存去存放90%的內存中活著的對象,即使是目的Survivor的容量不夠,也可以將多余的存放到老年代中(擔保機制),所有對于新生代,我們使用復制算法是比較好的(Serial收集器、ParNew收集器、Parallel scavenge收集器)。
但是對于老年代,沒有大多數對象朝生夕死這一特點,如果使用復制算法就要浪費一半的寶貴內存,所有我們用另一種辦法來處理它(指老年代)——標志-整理算法。
標記-整理算法分為兩個階段,“標記”和“整理”,
標記:首先標記出所有需要回收的對象(和標記-清除算法一樣);
整理:在標記完成后讓所有存活的對象都向一端移動,然后直接清理掉端邊界以外的內存(向一端移動類似復制算法)。
區別:標志-清除算法包括先標志,后清除兩個過程,標志-整理算法包括先標志,后清除,再整理三個過程。
當前商業虛擬機都是的垃圾收集都使用“分代收集”算法,這種算法并沒有什么新的思想,只是根據對象存活周期的不同將內存劃分為幾塊。一般是把Java堆分為新生代和老年代,這樣就可以根據各個年代的特點采取最適當的收集算法。
在新生代中,每次垃圾收集時都發現有大批對象死去,只有少量對象存活,就是使用復制算法,這樣只需要付出少量存活對象的復制成本就可以完成收集。而老年代中因為對象的存活率高、沒有額外空間對其分配擔保(新生代復制算法如果目的Survivor容量不夠會將多余對象放到老年代中,這就是老年代對新生代的分配擔保),必須使用“標記-清除算法”或“標記-整理算法”來回收。
新生代的minor gc頻率較高,復制算法正好浪費一半空間,不用整理內存空間碎片,以空間換時間;
老年代的major gc頻率較低,“標記-整理算法”包括先標志、再清除,最后整理,整理內存碎片需要時間,但是整個算法不浪費空間,以時間換空間。
四種常用算法優缺點比較、用途比較
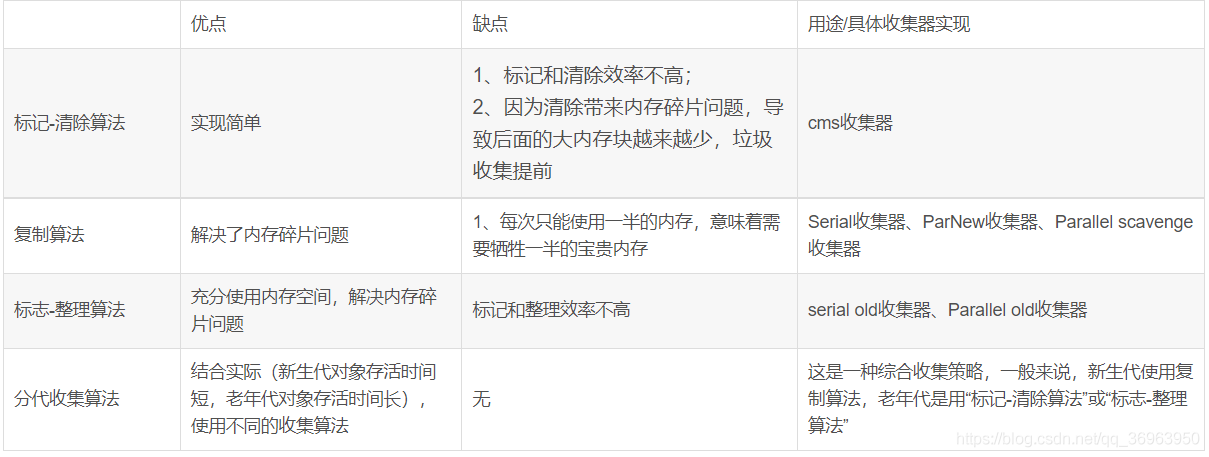
有了上面的垃圾回收算法,就有了很多的垃圾回收器。對于垃圾回收器,很少有表格對比,筆者以表格對比的方式呈現:
| 單線程or多線程 | 新生代or老年代 | 基于的收集算法 | 備注 | |
|---|---|---|---|---|
| Serial收集器 | 單線程 | 新生代 | 復制算法 | 優點:簡單; 缺點:Stop the world,垃圾收集時要停掉所有其他線程; 常用組合:Serial + serial old 新生代和老年代都是單線程,簡單 |
| ParNew收集器(是Serial收集器的多線程版本) | 多線程 | 新生代 | 復制算法 | 優點:相對于Serial收集器,使用了多線程; 缺點:除了多線程,其他所有和Serial收集器一樣; 常用組合:ParNew+ serial old 新生代多線程,老年代單線程,簡單(新生代ParNew收集器僅僅是Serial收集器的多線程版本,所有該組合相對于Serial + serial old 只是新生代是多線程而已,其余不變) |
| Parallel scavenge收集器(吞吐量優先收集器) | 多線程 | 新生代 | 復制算法 | 設計目標:盡可能達到一個可控制的吞吐量; 吞吐量=運行用戶代碼時間/(運行用戶代碼時間+來及收集時間); 優點:吞吐量高,可以高效率地利用CPU時間,盡快完成程序的計算任務,適合后臺運算; 缺點:沒有太大缺陷; 常用組合:Parallel scavenge + Parallel old 該組合完成吞吐量優先虛擬機,適用于后臺計算; |
| serial old收集器(是Serial收集器的老年代版本) | 單線程 | 老年代 | 標記-整理算法 | 優點:簡單; 缺點:Stop the world,垃圾收集時要停掉所有其他線程; 常用組合:Serial + serial old 新生代和老年代都是單線程,簡單; |
| Parallel old收集器(是Parallel scavenge收集器的老年代版本) | 多線程 | 老年代 | 標記-整理算法 | 優點:吞吐量高,可以高效率地利用CPU時間,盡快完成程序的計算任務,適合后臺運算; 缺點:沒有太大缺陷; 常用組合:Parallel scavenge + Parallel old 該組合完成吞吐量優先虛擬機,適用于后臺計算; |
| cms收集器(并發低停頓收集器) | 多線程 | 老年代 | 標記-清除算法 | 優點:停頓時間短,適合與用戶交互的程序;四個步驟:初始標記 CMS initial mark、并發標記 CMS concurrent mark、重新標記 CMS remark、并發清除 CMS concurrent sweep;常用組合:cms收集器 完成響應時間短虛擬機,適用于用戶交互; |
| G1收集器 | 多線程 | 新生代+老年代 | 標記-整理算法 | 面向服務端的垃圾回收器。特點:并行與并發、分代收集、空間整合、可預測的停頓;四個步驟:初始標記 Initial Marking、并發標記 Concurrent Marking、最終篩選 Final Marking 、篩選回收 Live Data Counting and Evacuation;常用組合:G1收集器 面向服務端的垃圾回收器注意:G1收集器的收集算法加粗了,這里做出說明,G1收集器從整體上來看是基于“標記-整理”算法實現的收集器,從局部(兩個region之間)上看來是基于“復制”算法實現的。 |
注意:G1收集器的收集算法加粗了,這里做出說明,G1收集器從整體上來看是基于“標記-整理”算法實現的收集器,從局部(兩個region之間)上看來是基于“復制”算法實現的。
從上表可以得到的收集常用組合包括:
常用組合1:Serial + serial old 新生代和老年代都是單線程,簡單
常用組合2:ParNew+ serial old 新生代多線程,老年代單線程,簡單
常用組合3:Parallel scavenge + Parallel old 該組合完成吞吐量優先虛擬機,適用于后臺計算
常用組合4:cms收集器 完成響應時間短虛擬機,適用于用戶交互
常用組合5:G1收集器 面向服務端的垃圾回收器
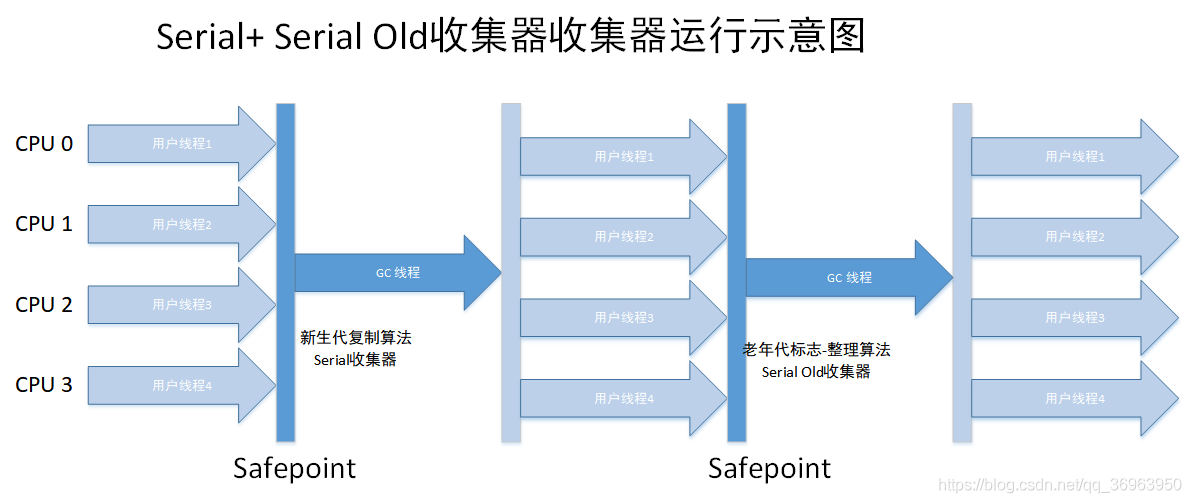
附:圖上有一個safepoint,譯為安全點(有的博客上寫成了savepoint,是錯誤的,至少是不準確的),這個safepoint干什么的呢?如何確定這個safepoint的位置?
這個safepoint是干什么的?
safepoint的定義是“A point in program where the state of execution is known by the VM”,譯為程序中一個點就是虛擬機所知道的一個執行狀態。
JVM中safepoint有兩種,分別為GC safepoint、Deoptimization safepoint:
GC safepoint:用在垃圾收集操作中,如果要執行一次GC,那么JVM里所有需要執行GC的Java線程都要在到達GC safepoint之后才可以開始GC;
Deoptimization safepoint:如果要執行一次deoptimization,那么JVM里所有需要執行deoptimization的Java線程都要在到達deoptimization safepoint之后才可以開始deoptimize
我們上圖中的safepoint自然是GC safepoint,所以上圖中的兩個safepoint都是指執行GC線程前的狀態。
對于上圖的理解是(很多博客上都有這種運行示意圖,但是沒有加上解釋,筆者這里加上):
1、多個用戶線程(圖中是四個)要開始執行新生代GC操作,所以都要達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
2、四個線程都執行新生代的GC操作,因為使用的是Serial收集器,所以是基于復制算法的單線程GC,而且要Stop the world,所以只有GC線程在執行,四個用戶線程都停止了。
3、新生代GC操作完成,四個線程繼續執行,過了一會兒,要開始執行老年代的GC操作了,所以四個線程都要再次達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
4、四個線程都執行老年代的GC操作,因為使用的是Serial Old收集器,所以是基于標志-整理算法的單線程GC,而且要Stop the world,所以只有GC線程在執行,四個用戶線程都停止了。
5、老年代GC操作完成,四個線程繼續執行。
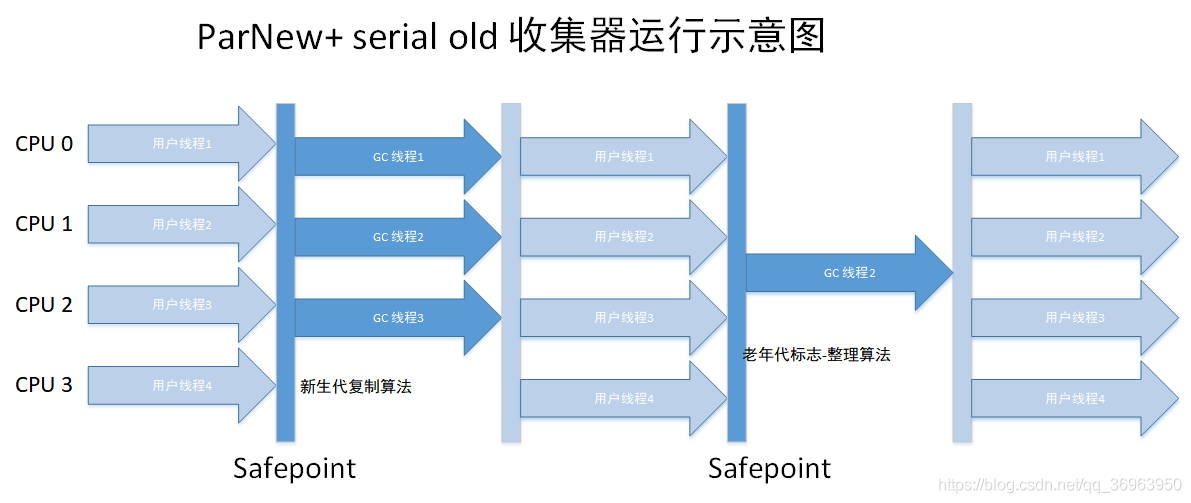
該組合中新生代ParNew收集器僅僅是Serial收集器的多線程版本,所有該組合相對于Serial + serial old 只是新生代是多線程而已,其余不變
對于上圖的理解是(很多博客上都有這種運行示意圖,但是沒有加上解釋,筆者這里加上):
1、多個用戶線程(圖中是四個)要開始執行新生代GC操作,所以都要達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
2、四個線程都執行新生代的GC操作,因為使用的是Parnew收集器,所以是基于復制算法的多線程GC(注意,這里的多線程GC,是指多個GC線程并發,用戶線程還是要停止的)所以還是要Stop the world,所以只有GC線程在執行,四個用戶線程都停止了。
3、新生代GC操作完成,四個線程繼續執行,過了一會兒,要開始執行老年代的GC操作了,所以四個線程都要再次達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
4、四個線程都執行老年代的GC操作,因為使用的是Serial Old收集器,所以是基于標志-整理算法的單線程GC,而且要Stop the world,所以只有GC線程在執行,四個用戶線程都停止了。
5、老年代GC操作完成,四個線程繼續執行。
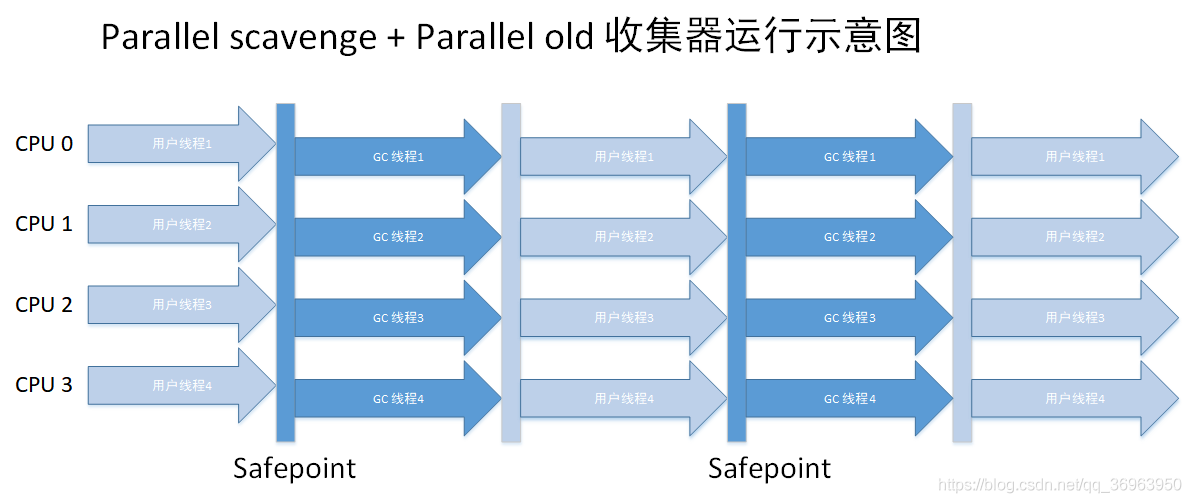
對于上圖的理解是:
1、多個用戶線程(圖中是四個)要開始執行新生代GC操作,所以都要達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
2、四個線程都執行新生代的GC操作,因為使用的是Parallel scavenge收集器,所以是基于復制算法的多線程GC(注意,這里的多線程GC,是指多個GC線程并發,用戶線程還是要停止的)所以只有GC線程在執行,四個用戶線程都停止了。
3、新生代GC操作完成,四個線程繼續執行,過了一會兒,要開始執行老年代的GC操作了,所以四個線程都要再次達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
4、四個線程都執行老年代的GC操作,因為使用的是Parallel Old收集器,所以是基于標志-整理算法的多線程GC,(注意,這里的多線程GC,是指多個GC線程并發,用戶線程還是要停止的)所以只有GC線程在執行,四個用戶線程都停止了。
5、老年代GC操作完成,四個線程繼續執行。
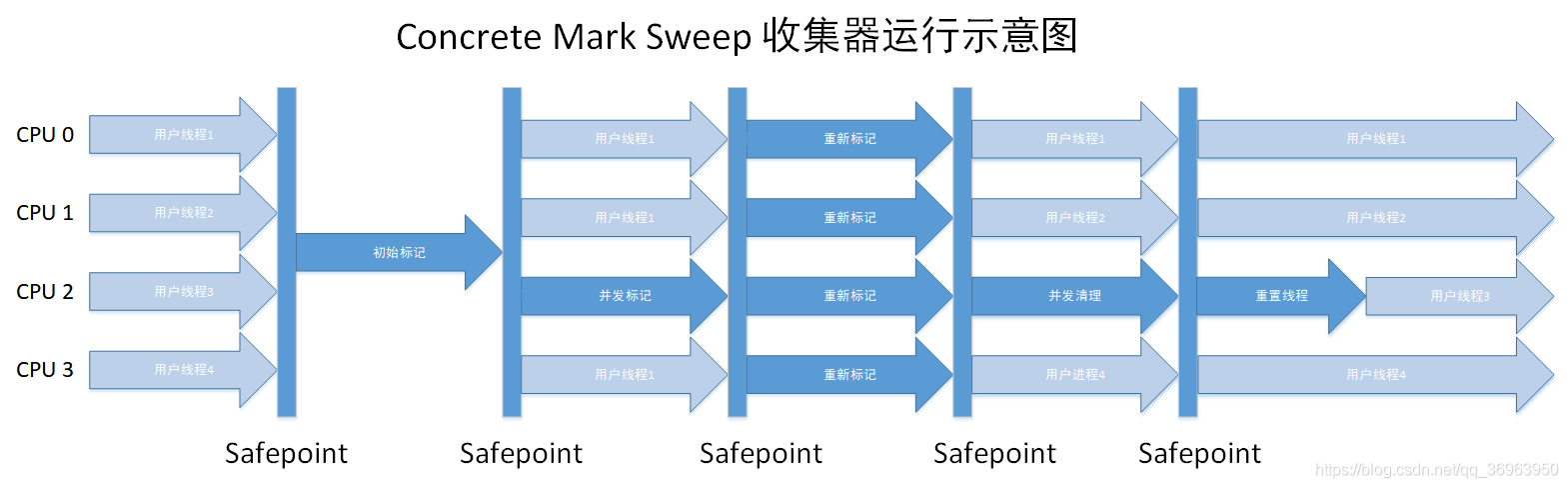
對于上圖的理解是:
CMS收集包括四個步驟:初始標記、并發標記、重新標記、并發清除(CMS作為標記-清除收集器,三個標記一個清除)
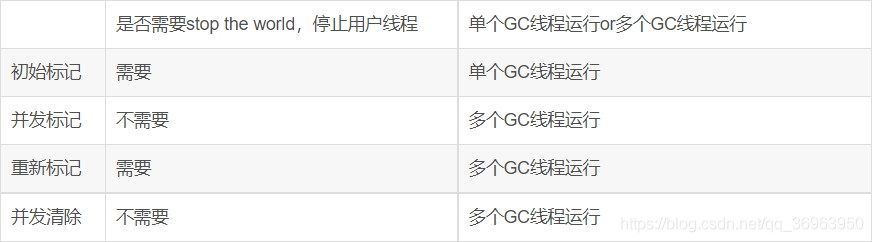
1、多個用戶線程(圖中是四個)要開始執行新生代GC操作,所以都要達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
2、四個線程都執行GC操作,因為使用的是CMS收集器,第一步驟是初始標記,初始標記僅僅只是標記一下GC Roots能直接關聯到的對象,GC的標記階段需要stop the world,讓所有Java線程掛起,這樣JVM才可以安全地來標記對象。所以只有“初始標記”在執行,四個用戶線程都停止了。初始標記完成后,達到第二個GC safepoint,圖中達到了;
3、開始執行并發標記,并發標記是GCRoot開始對堆中的對象進行可達性分析,找出存活的對象,并發標記可以與用戶線程一起執行,并發標記完成后,所有線程達到下一個GC safepoint,圖中達到了;
4、開始執行重新標記,重新標記是為了修正在并發標記期間因用戶程序繼續運作而導致標記產生變動的那部分標記記錄,
重新標記完成后,所有線程達到下一個GC safepoint,圖中達到了;
5、開始執行并發清理,并發清理可以與用戶線程一起執行,并發清理完成后,所有線程達到下一個GC safepoint,圖中達到了;
6、開始重置線程,就是對剛才并發標記操作的對象,圖中是線程3(注意:重置線程針對的是并發標記的線程,沒有被并發標記的線程不需要重置線程操作),重置操作線程3的時候,與其他三個用戶線程無關,它們可以一起執行。
CMS為什么是多線程收集器?
因為CMS收集器整個過程中耗時最長的第二并發標記和第四并發清除過程中,GC線程都可以與用戶線程一起工作,初始標記和重新標記時間忽略不計,所以,從總體上來說,cms收集器的內存回收過程與用戶線程是并發執行的,所以上表中CMS為多線程收集器。
G1收集器是一款比CMS更優秀的收集器,所以取代了cms,成為現在虛擬機的內置收集器,它將整個Java堆劃分為多個大小相等的獨立區域,即Region,雖然還保留新生代和老年代的概念,但新生代和老年代已不再物理隔離,僅僅是邏輯分區,它們都是一部分Region的集合,如下圖:
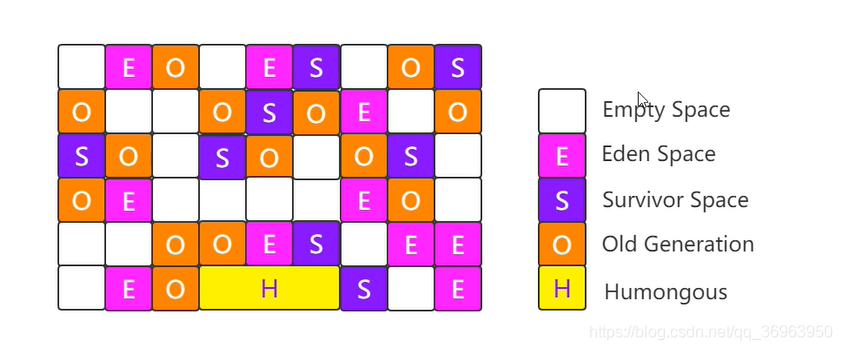
每個region內部必須是邏輯連續的,一個大小限制為 1M ~ 32M 之間,數量為 2048 個region,所以整個收集器 大小為 2G ~ 64G 。region 分為五種,Empty就是空白region,eden 和 survivor 都是年輕代,使用復制算法,old 是老年代,使用 標志-整理算法(先標記,再清除,最后整理),還有一個 Humongous region,是用來存放大對象的。
G1收集器的精髓1:G1 英文全名為 Garage First,就是 垃圾優先 的意思,內置 region 價值分析算法,垃圾收集的時候,會跟蹤各個Region里面的垃圾堆積的價值大小(回收所獲得的空間大小以及回收所需時間的經驗值),在后臺維護一個優先列表,每次依據允許的收集時間,優先收集回收價值最大的Region。正是這種使用Region劃分內存空間以及有優先級的區域回收方式,保證了G1收集器在有限時間內可以獲取盡可能高的效率,就是 垃圾優先 的精髓。
G1收集器的精髓2:不僅如此,在 G1 收集器中,各個region不是物理分區,僅僅邏輯分區,region的身份是可以切換的,比如一個 old region 經過價值分析被選中后,就會被收集,收集之后就變成了 empty region,然后下一次就可以和旁邊的 eden region 連續起來,就可以分配 新對象 或 大對象了,這種 region 身份切換 讓 G1 收集器不受固定分區的影響,更靈活的處理垃圾收集,這個其他的垃圾收集器所不具備的。
region 一共八個身份/角色
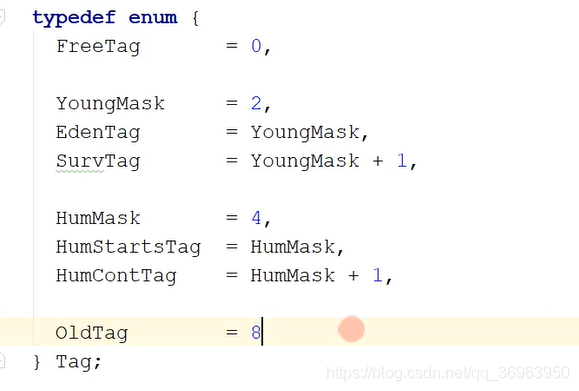
FreeTag 空閑區域
Young Eden SurvTag 年輕代區域,分為Eden 和 Surv 兩種
HumStartTag 大對象頭部區域
HumContTag 大對象連續區域
OldTag 老年代對象
注意:單個region大小范圍為 1M ~ 32M,當對象大小超過單個region大小的一半,則會被認為是大對象,放到Humongous里面,大對象有 HumStartTag + N 個 HumContTag 構成,所以用兩種標記。
G1收集器運行示意圖如下:
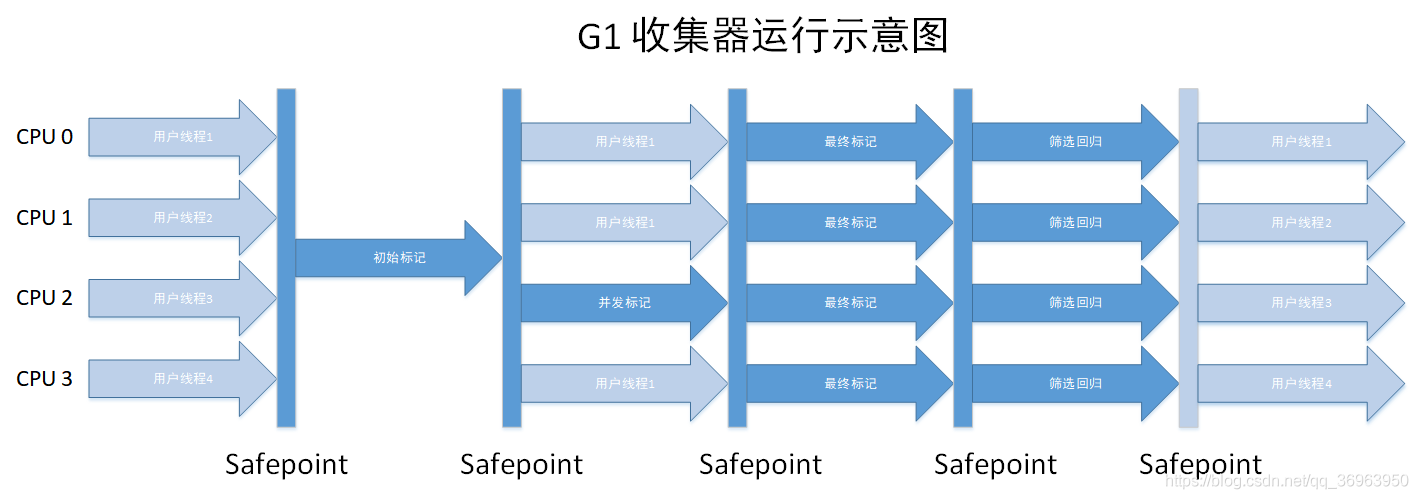
對于上圖的理解是:
G1收集包括四個步驟:初始標記、并發標記、最終篩選、篩選回收
1、多個用戶線程(圖中是四個)要開始執行新生代GC操作,所以都要達到GC safepoint點,先到的要等待晚到的,圖中都達到了;
2、開始執行初始標記,初始標記僅僅只是標記一下GC Roots能直接關聯到的對象,并且修改TAMS(Next Top at Mark Start)的值,讓下一個階段用戶程序并發標記時,能在正確可用的Region上創建新對象,整個標記階段需要stop the world,讓所有Java線程掛起,這樣JVM才可以安全地來標記對象。所以只有“初始標記”在執行,四個用戶線程都停止了。初始標記完成后,達到第二個GC safepoint,圖中達到了;
3、開始執行并發標記,并發標記是GCRoot開始對堆中的對象進行可達性分析,找出存活的對象,并發標記可以與用戶線程一起執行,并發標記完成后,所有線程(GC線程、用戶線程)達到下一個GC safepoint,圖中達到了;
4、開始執行最終標記,最終標記是為了修正在并發標記期間因用戶程序繼續運作而導致標記產生變動的那部分標記記錄,最終標記完成后,所有線程達到下一個GC safepoint,圖中達到了;
5、開始執行篩選回收,篩選回歸首先對各個Region的回收價值和成本排序, 根據用戶期待的GC停頓時間來制定回收計劃,篩選回收過程中,因為停頓用戶線程將大幅提高收集效率,所以一般篩選回歸是停止用戶線程的,篩選回歸完成后,所有線程達到下一個GC safepoint,圖中達到了;
6、G1收集器收集結束,繼續并發執行用戶線程。
(筆者這里加上idea上如何使用這些參數,這些是垃圾收集器的參數,所以這里放到第四部分,在本文第五部分內存分配我們會用到)
| 參數 | idea中使用方式 | 描述 |
|---|---|---|
| UseSerialGC | VM Options:-XX:+UseSerialGC | 虛擬機運行在Client模式下的默認值,打開此開關之后,使用Serial+Serial Old的收集器組合進行內存回收 |
| UseParNewGC | VM Options: -XX:+UseParNewGC | 打開此開關之后,使用ParNew+ Serial Old的收集器組合進行內存回收 |
| UseConcMarkSweepGC | VM Options: -XX:+UseConcMarkSweepGC | 打開此開關之后,使用ParNew + CMS+ Serial Old的收集器組合進行內存回收。Serial Old收集器將作為CMS收集器出現Concurrent Mode Failure失敗后的后備收集器使用 |
| UseParallelGC | VM Options: -XX:+UseParallelGC | 虛擬機運行在Server模式下的默認值,打開此開關之后,使用Parallel Scavenge + Serial Old(PS MarkSweep)的收集器組合進行內存回收 |
| UseParallelOldGC | VM Options: -XX:UseParallelOldGC | 打開此開關后,使用Parallel Scavenge + Parallel Old 的收集器組合進行內存回收 |
| SurvivorRatio | VM Options: -XX:SurvivorRatio=8 | 新生代中Eden區域與Survivor區域的容量比值,默認為8,代表Eden:Survivor=8:1 |
| PretenureSizeThreshold | VM Options: -XX:PretenureSizeThreshold=3145728,表示大于3MB都到老年代中去 | 直接晉升到老年代的對象大小,設置這個參數后,這個參數以字節B為單位大于這個參數的對象將直接在老年代中分配 |
| MaxTenuringThreshold | VM Options: -XX:MaxTenuringThreshold=2,表示經歷兩次Minor GC,就到老年代中去 | 晉升到老年代的對象年齡,每個對象在堅持過一次Minor GC之后,年齡就增加1,當超過這個參數值就進入到老年代 |
| UseAdaptiveSizePolicy | VM Options: -XX:+UseAdaptiveSizePolicy | 動態調整Java堆中各個區域的大小以及進入老年代的年齡 |
| HandlePromotionFailure | jdk1.8下,HandlePromotionFailure會報錯,Unrecongnized VM option 是否允許分配擔保失敗,即老年代的剩余空間不足應應對新生代的整個Eden區和Survivor區的所有對象存活的極端情況 | |
| ParallelGCThreads | VM Options: -XX:ParallelGCThreads=10 | 設置并行GC時進入內存回收線程數 |
| GCTimeRadio | VM Options: -XX:GCTimeRadio=99 | GC占總時間的比率,默認值是99,即允許1%的GC時間,僅在使用Parallel Scavenge收集器時生效 |
| MaxGCPauseMillis | VM Options:-XX:MaxGCPauseMillis=100 | 設置GC的最大停頓時間,僅在使用Parallel Scavenge收集器時生效 |
| CMSInitiatingOccupanyFraction | VM Options:-XX:CMSInitiatingOccupanyFraction=68 | 設置CMS收集器在老年代空間被使用多少后觸發垃圾收集,默認值68%,僅在使用CMS收集器時生效 |
| UseCMSCompactAtFullCollection | VM Options: -XX:+UseCMSCompactAtFullCollection | 設置CMS收集器在完成垃圾收集后是否要進行一次內存碎片的整理,僅在使用CMS收集器時生效 |
| CMSFullGCsBeforeCompaction | VM Options:-XX:CCMSFullGCsBeforeCompaction=10 | 設置CMS收集在進行若干次垃圾收集后再啟動一次內存碎片整理,僅在使用CMS收集器時生效 |
新生代GC(Minor GC):發生在新生代的垃圾收集動作,因為Java對象大多具有朝生夕滅的特性,所有Minor GC非常頻繁,一般回收速度較快。
老年代GC(Major GC/):發生在老年代的GC,出現了major GC,經常會伴隨一個MinorGC(但是不絕對),Major GC速度一般比Minor GC慢10倍。
在JVM中,GC分為 full Gc 和 partition gc兩種,full gc是指新生代,老年代,永久區都gc,即全局gc,其他的所有的,minor gc 和 major gc 都是partion gc。
Major GC 是清理永久代。
Full GC 是清理整個堆空間—包括年輕代和永久代。
-XX:+PrintGCDetails //打印GC日志 -Xms20M //初始堆大小為20M -Xmx20M //最大堆大小為20M -Xmn10M //年輕代大小為10M,則老年代大小=堆大小20M-年輕代大小10M=10M -XX:SurvivorRatio=8 //年輕代 Eden:Survivor=8 則Eden為8M Survivor0為1M Survivor1為1M -XX:+UseSerialGC //筆者使用的jdk8默認為Parallel scavenge+Parallel old收集器組合,書上使用Serial+Serial Old的收集器組合,這里設置好
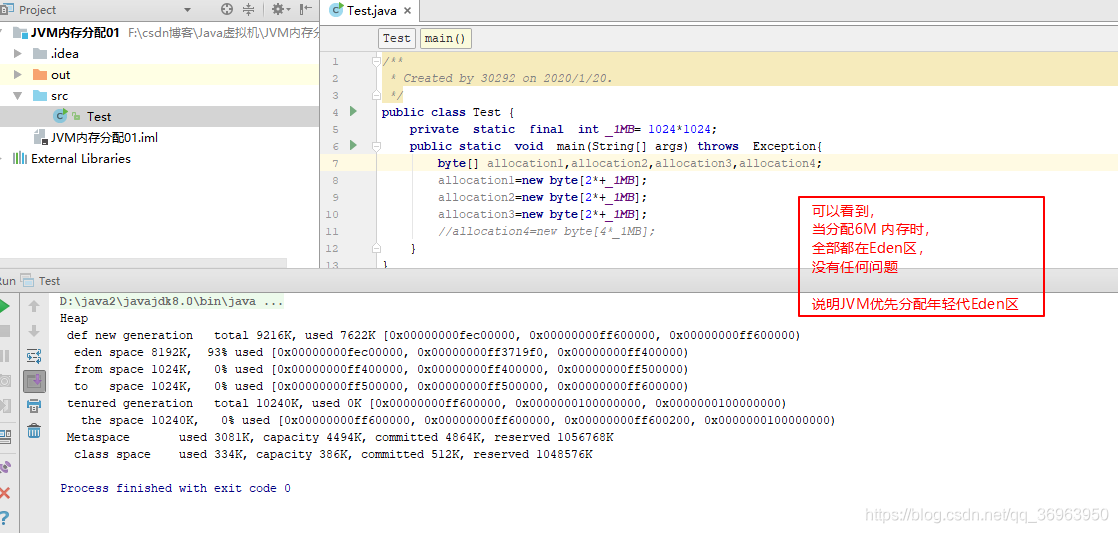
第一步:可以看到,當分配6M內存時,全部都在Eden區,沒有任何問題,說明JVM優先在Eden區上分配對象
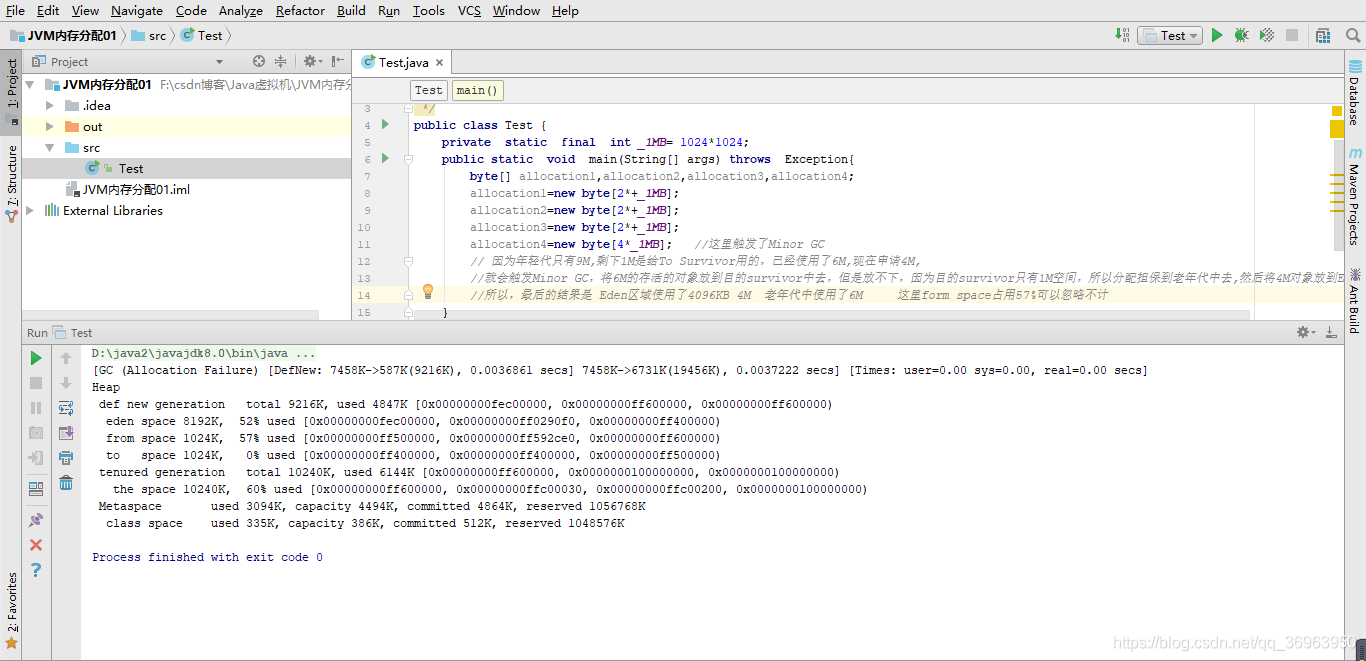
第二步:因為年輕代只有9M,剩下1M是給To Survivor用的,已經使用了6M,現在申請4M, 就會觸發Minor GC,將6M的存活的對象放到目的survivor中去,但是放不下,因為目的survivor只有1M空間,所以分配擔保到老年代中去,然后將4M對象放到Eden區中。所以,最后的結果是 Eden區域使用了4096KB 4M 老年代中使用了6M 這里form space占用57%可以忽略不計。
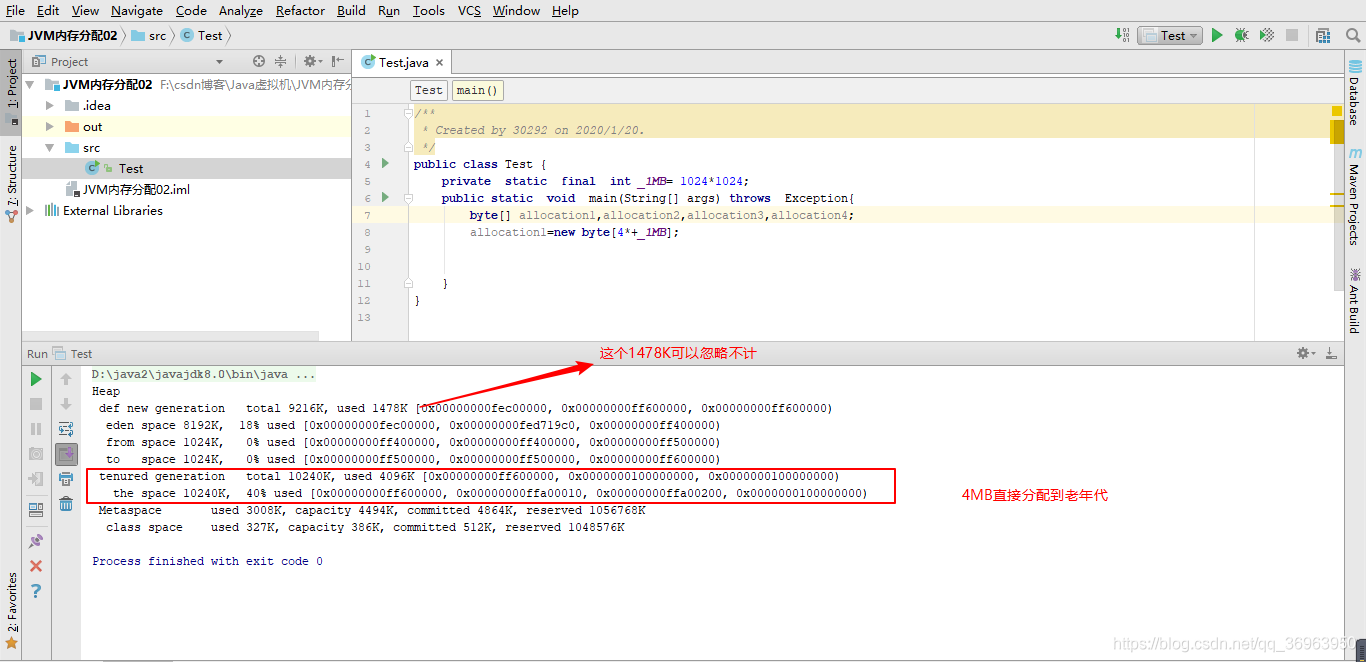
-XX:+PrintGCDetails //打印GC日志 -Xms20M //初始堆大小為20M -Xmx20M //最大堆大小為20M -Xmn10M //年輕代大小為10M,則老年代大小=堆大小20M-年輕代大小10M=10M -XX:SurvivorRatio=8 //年輕代 Eden:Survivor=8 則Eden為8M Survivor0為1M Survivor1為1M -XX:+UseSerialGC //筆者使用的jdk8默認為Parallel scavenge+Parallel old收集器組合,書上使用Serial+Serial Old的收集器組合,這里設置好 -XX:PretenureSizeThreshold=3145728 // 單位是字節 3145728/1024/1024=3MB 大于3M的對象直接進入老年代
-XX:+PrintGCDetails //打印GC日志 -Xms20M //初始堆大小為20M -Xmx20M //最大堆大小為20M -Xmn10M //年輕代大小為10M,則老年代大小=堆大小20M-年輕代大小10M=10M -XX:SurvivorRatio=8 //年輕代 Eden:Survivor=8 則Eden為8M Survivor0為1M Survivor1為1M -XX:+UseSerialGC //筆者使用的jdk8默認為Parallel scavenge+Parallel old收集器組合,書上使用Serial+Serial Old的收集器組合,這里設置好 -XX:MaxTenuringThreshold=1 //表示經歷一次Minor GC,就到老年代中去
第一步驟:只分配allocation1 allocation2,不會產生任何Minor GC,對象都在Eden區中
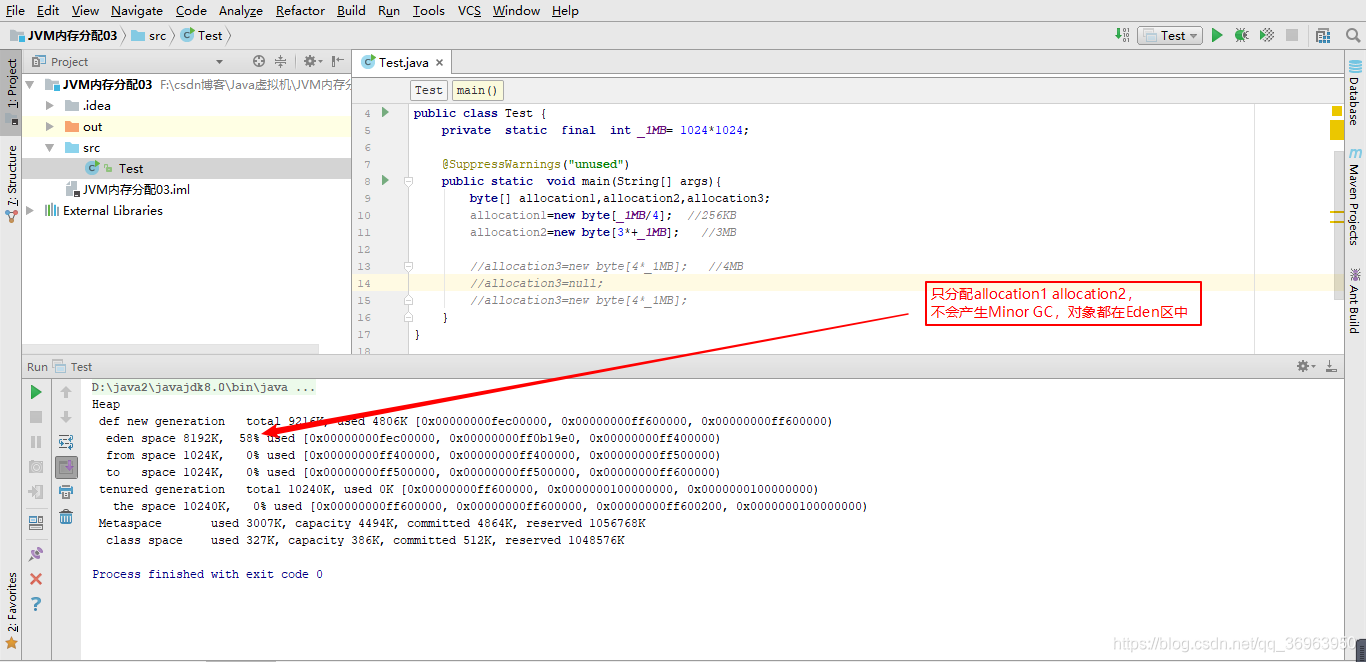
第二步驟:分配allocation3,產生Minor GC,allocation2移入老年區
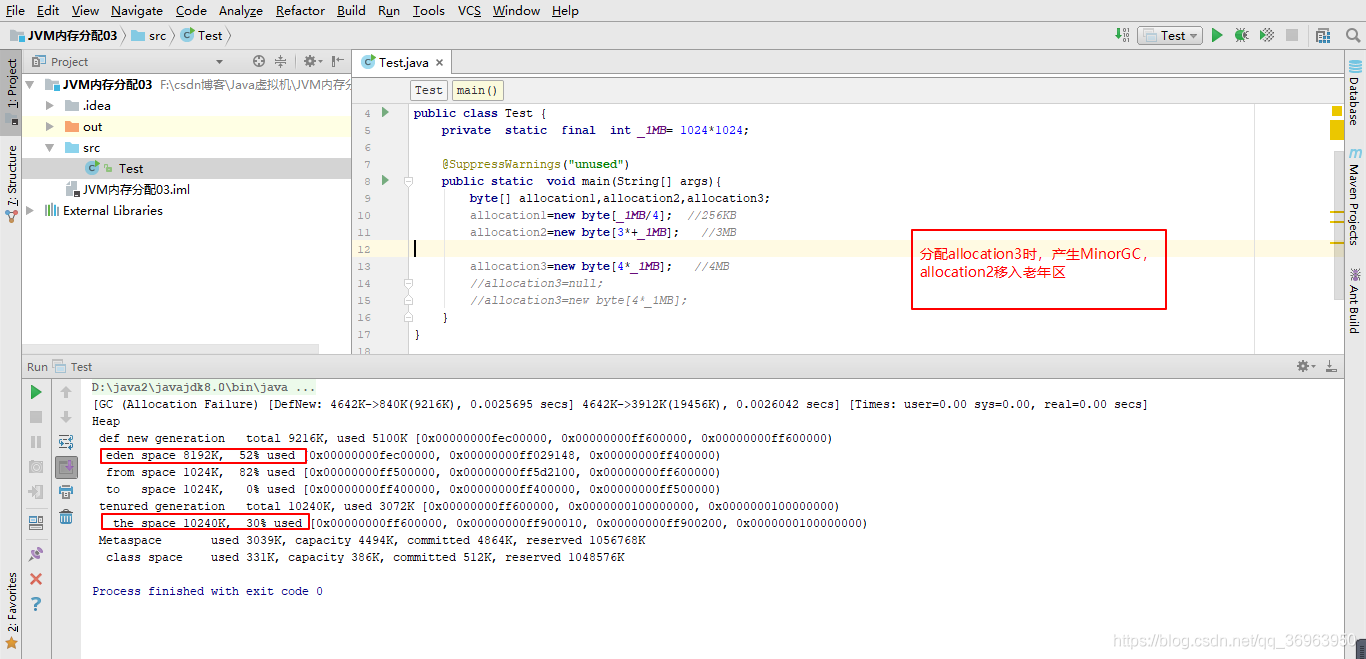
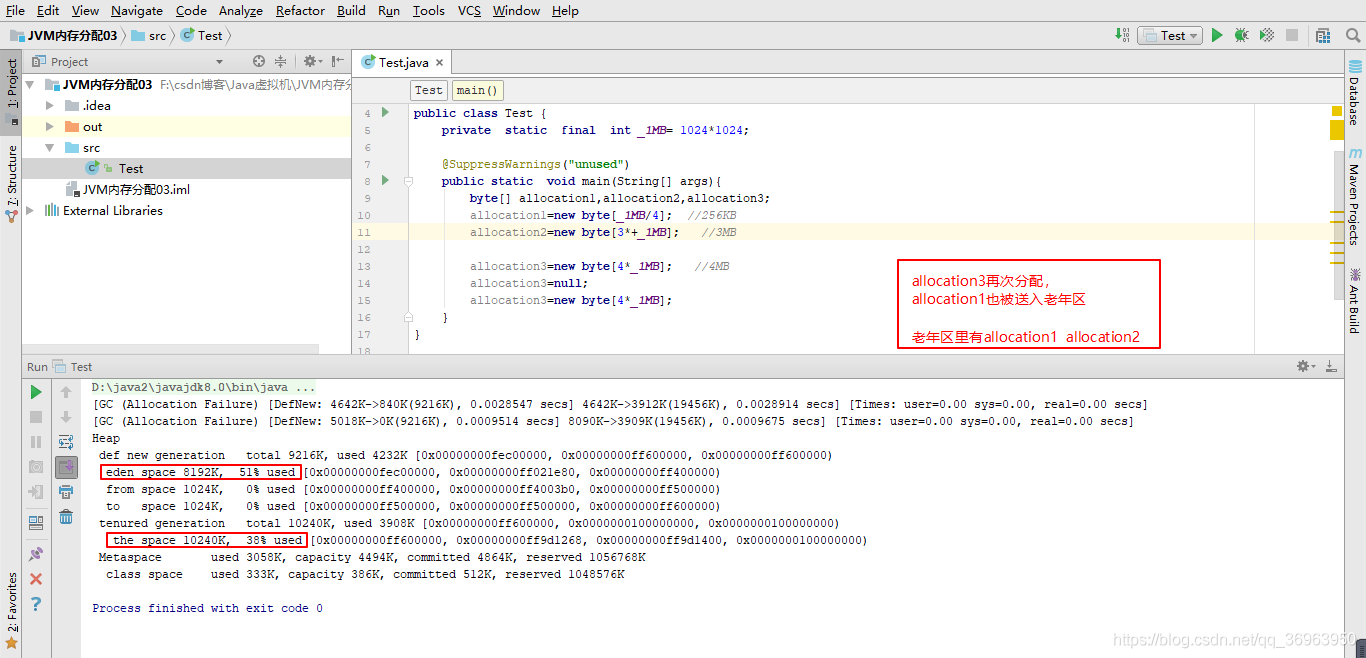
第三步驟:allocation3再次分配,allocation1也被送入老年區,老年區里有allocation1 allocation2
本文講述JVM自動內存管理(包括內存回收和內存),前言部分從操作系統引入JVM,第二部分介紹JVM空間結構(運行時數據區、堆內存和非堆內存),第三部分介紹HotSpot虛擬機,第四部分和第五部分分別介紹自動內存回收和自動內存分配的原理實現。
“JVM內存回收和內存分配方式”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





