溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
首先,我們要講的是JVM的垃圾回收機制,我默認準備閱讀本篇的人都知道以下兩點:
因為我們即將要講的就是發生在JVM的Java堆上的垃圾回收,為了突出核心,其他的一些與本篇不太相關的東西我就一筆略過了
眾所周知,Java堆上保存著對象的實例,而Java堆的大小是有限的,所以我們只能把一些已經用完的,無法再使用的垃圾對象從內存中釋放掉,就像JVM幫助我們手動在代碼中添加一條類似于C++的free語句的行為
然而這些垃圾對象是怎么回收的,現在不知道沒關系,我們馬上就會講到
怎么判斷對象為垃圾對象
在了解具體的GC(垃圾回收)算法之前,我們先來了解一下JVM是怎么判斷一個對象是垃圾對象的
顧名思義,垃圾對象,就是沒有價值的對象,用更嚴謹的語句來說,就是沒有被訪問的對象,也就是說沒有被其他對象引用,這就牽引出我們的第一個判斷方案:引用計數法
引用計數法
這種算法的原理是,每有一個其他對象產生對A對象的引用,則A對象的引用計數值就+1,反之,每有一個對象對A對象的引用失效的時候,A對象的引用計數值就-1,當A對象的引用計數值為0的時候,其就被標明為垃圾對象
這種算法看起來很美好,了解C++的應該知道,C++的智能指針也有類似的引用計數,但是在這種看起來“簡單”的方法,并不能用來判斷一個對象為垃圾對象,我們來看以下場景:
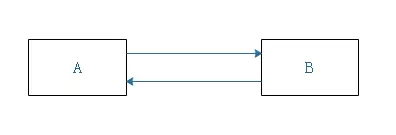
在這個場景中,A對象有B對象的引用,B對象也有A對象的引用,所以這兩個對象的引用計數值均不為0,但是,A、B兩個對象明明就沒有任何外部的對象引用,就像大海上兩個緊挨著的孤島,即使他們彼此依靠著,但仍然是孤島,其他人過不去,而且由于引用計數不為0,也無法判斷為垃圾對象,如果JVM中存在著大量的這樣的垃圾對象,最終就會頻繁拋出OOM異常,導致系統頻繁崩潰
總而言之,如果有人問你為什么JVM不采用引用計數法來判斷垃圾對象,只需要記住這一句話:引用計數法無法解決對象循環依賴的問題
可達性分析法
引用計數法已經很接近結果了,但是其問題是,為什么每有一個對象來引用就要給引用計數值+1,就好像有人來敲門就開一樣,我們應該只給那些我們認識的、重要的人開門,也就是說,只有重要的對象來引用時,才給引用計數值+1
但是這樣還不行,因為重要的對象來引用只要有一個就夠了,并不需要每有一個引用就+1,所以我們可以將引用計數法優化為以下形式:
給對象設置一個標記,每有一個“重要的對象”來引用時,就將這個標記設為true,當沒有任何“重要的對象”引用時,就將標記設為false,標記為false的對象為垃圾對象
這就是可達性分析法的雛形,我們可以繼續進行修正,我們并不需要主動標記對象,而只需要等待垃圾回收時找到這些“重要的對象”,然后從它們出發,把我們能找到的對象都標記為非垃圾對象,其余的自然就是垃圾對象
我們將上文提到的“重要的對象”命名為GC Roots,這樣就得到了最終的可達性分析算法的概念:
創建垃圾回收時的根節點,稱為GC Roots,從GC Roots出發,不能到達的對象就被標記為垃圾對象
其中,可以作為GC Roots的區域有:
換句話說,GC Roots就是方法中的局部變量、類屬性,以及常量
垃圾回收算法
終于到本文的重點了,我們剛剛分析了如何判斷一個對象屬于垃圾對象,接下來我們就要重點分析如何將這些垃圾對象回收掉
標記-清除算法
標記-清除很容易理解,該算法有兩個過程,標記過程和清除過程,標記過程中通過上文提到的可達性分析法來標記出所有的非垃圾對象,然后再通過清除過程進行清理
比方說,我們現在有下面的這樣的一個Java堆,已經通過可達性分析法來標記出所有的垃圾對象(用橙色表明,藍色的是普通對象):
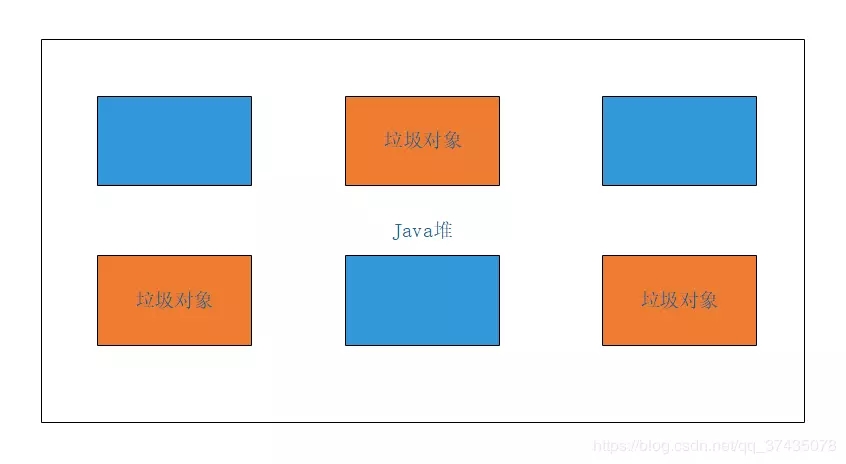
然后我們通過清除階段進行清理,結果是下圖:
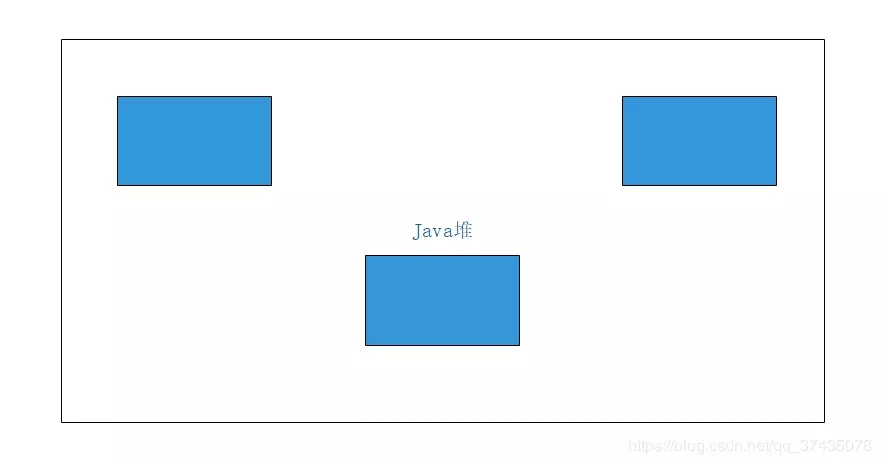
發現什么問題了嗎,沒錯,清理完后的空間是不連續的,也就是說,整個算法最大的缺點就是:
這里引出一個FGC的概念,為了避免主題跑偏,本文中暫時不進行深入,只需要知道垃圾回收分為YGC(年輕代垃圾回收)和FGC(完全垃圾回收),可以把YGC理解為掃掃地,倒倒垃圾,把FGC理解為給家里來個大掃除
復制算法
復制算法將Java堆劃分為兩塊區域,每次只使用其中的一塊區域,當垃圾回收發生時,將所有被標記的對象(GC Roots可達,為非垃圾對象)復制到另一塊區域,然后進行清理,清理完成后交換兩塊區域的可用性
這種方式因為每次只需要一整塊一起刪除即可,就不用一個個地刪除了,同時還能保證另一塊區域是連續的,也解決了空間碎片的問題
整個流程我們再來看一遍
1.首先我們有兩塊區域S1和S2,標記為灰色的區域為當前激活可用的區域:
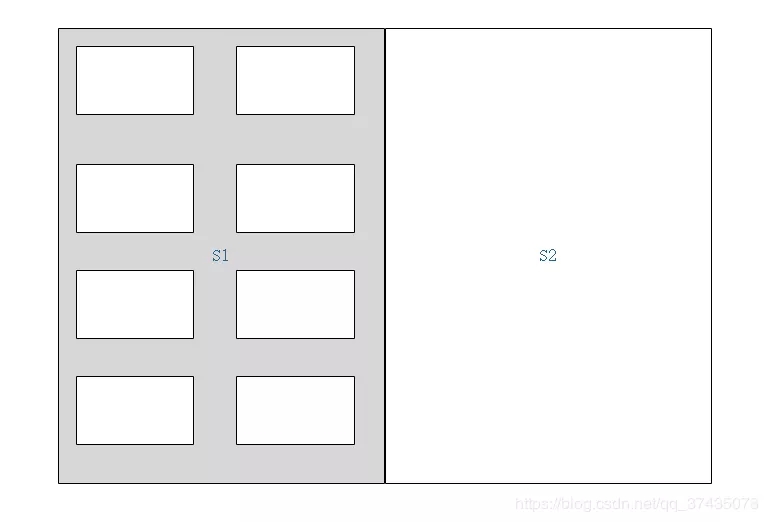
2.對Java堆上的對象進行標記,其中藍色的為GC Roots可達的對象,其余的均為垃圾對象:
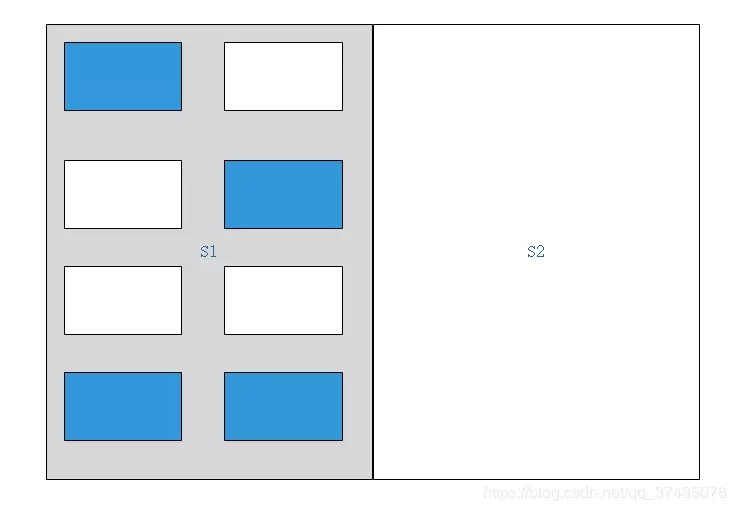
3.接下來將所有可用的對象復制到另一塊區域中:
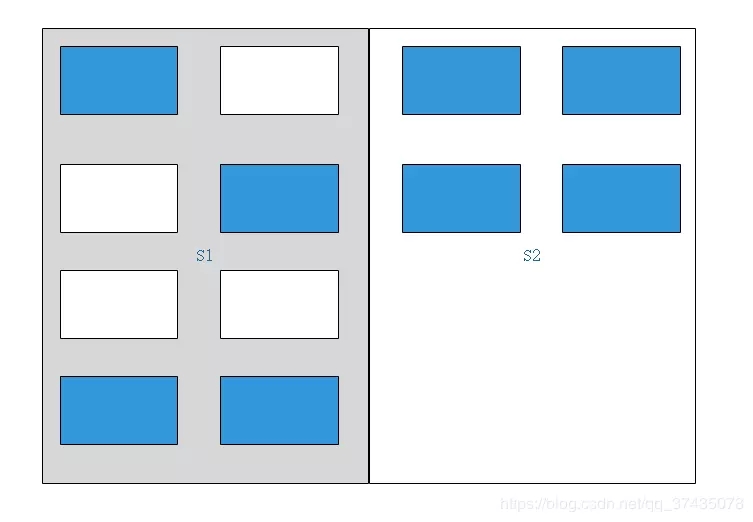
4.將原區域中所有內容刪除,并將另一塊區域激活
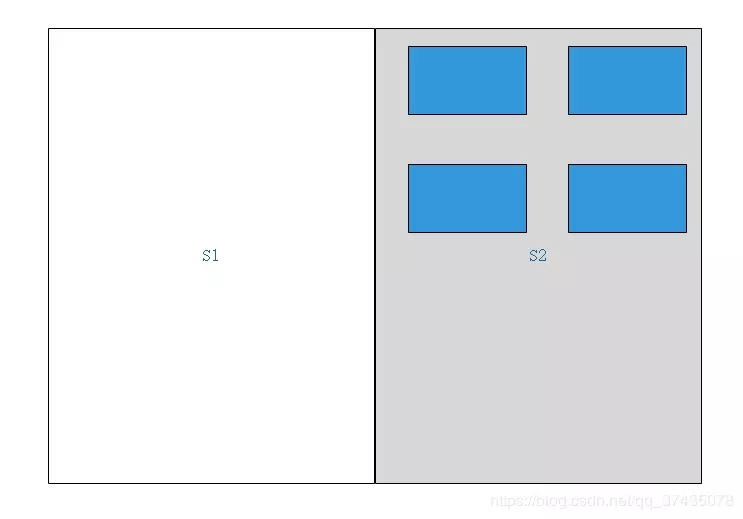
這種方法的優缺點也很明顯:
為了解決這一缺點,就引出了下面這個算法
優化的復制算法
至于為什么不另起一個名字,其實是因為這個算法也叫做復制算法,更確切的說,剛才介紹的只是優化算法的雛形,沒有虛擬機會使用上面的那種復制算法,所以接下來要講的,就是真正的復制算法
這個算法的思路和剛才講的一樣,不過這個算法將內存分為3塊區域:1塊Eden區,和2塊Survivor區,其中,Eden區要占到80%
這兩塊Survivor區就可以理解為我們剛才提到的S1和S2兩塊區域,我們每次只使用整個Eden區和其中一塊Survivor區,整個算法的流程可以簡要概括為:
1.當發生垃圾回收時,將Eden區+Survivor區中仍然存活的對象一次性復制到另一塊Survivor區上
2.清理掉Eden區和使用的Survivor區中的所有對象
3.交換兩塊Survivor的激活狀態
光看文字描述比較抽象,我們來看圖像的形式:
1.我們有以下這樣的一塊Java堆,其中灰色的Survivor區為激活狀態
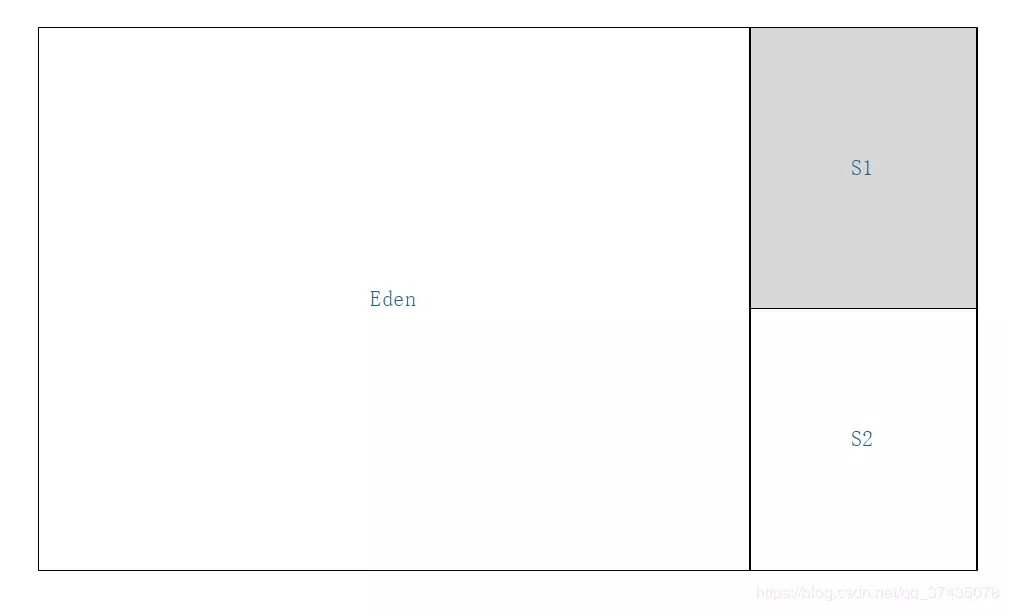
2.標記所有的GC Roots可達對象(藍色標記)
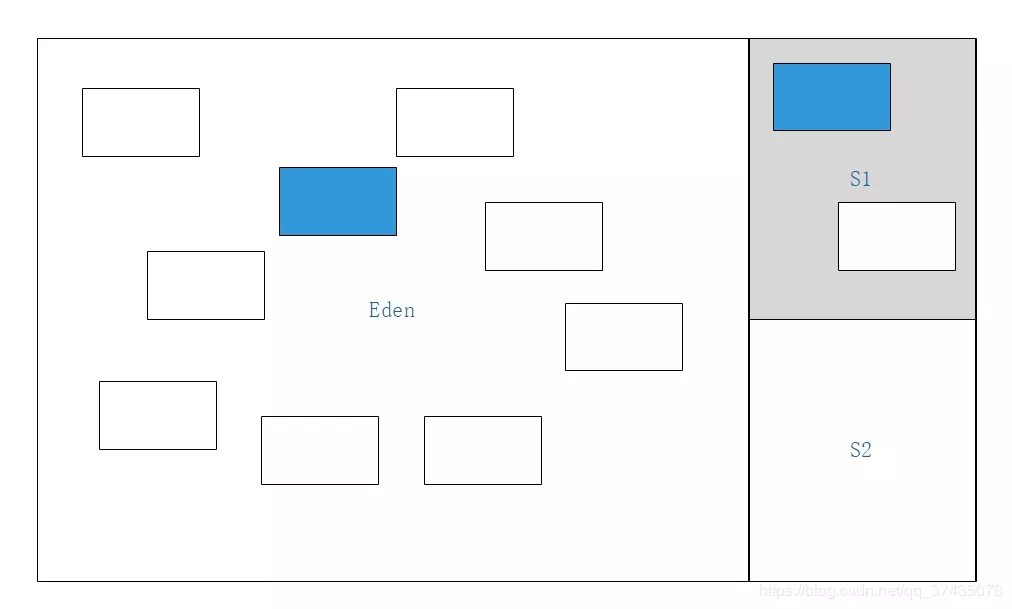
3.將標記對象全部復制到另一塊Survivor區域中
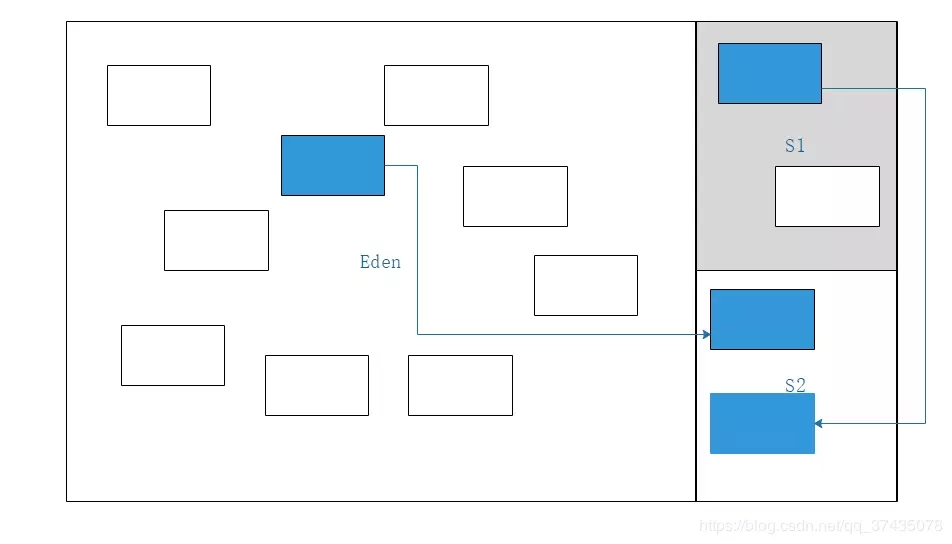
4.清理掉Eden區和激活的Survivor區中的所有對象,然后交換兩塊區域的激活狀態
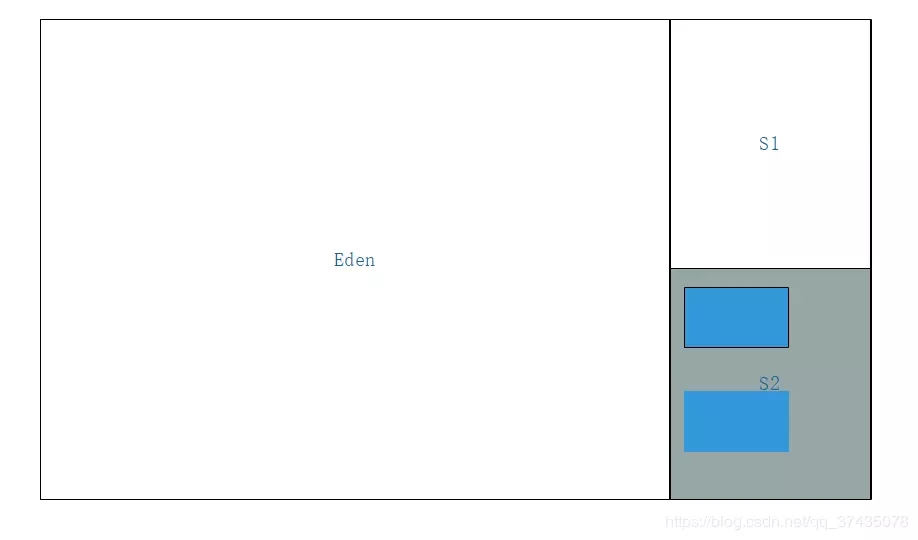
以上就是整個復制算法的全過程了,有人可能會問了,為什么Survivor區這么小,就不怕放不下嗎?其實平均來說,每次垃圾回收的時候基本都會回收98%左右的對象,也就是說,我們完全可以保證大部分情況下剩余的對象都小于10%,放在一塊Survivor區中是沒問題的。當然,也可能會發生Survivor區不夠用的問題,這時候就需要依賴其他內存給我們提供后備了
這種算法較好地解決了內存利用率低的問題,但是復制算法的兩個問題依然沒有解決:
標記-整理算法
這種算法可以說是專門針對對象存活率高的程序,具體的流程如下:
1.GC發生時,將所有被標記的存活對象移動到內存的一端
2.移動完成后,清理掉所有移動后的邊界以外的對象
我相信大家在理解了前面幾個算法之后,這個算法也能很方便地理解,我就不畫圖了,用一個例子來解釋:
問題:對于一個長度為n的數組,我們想要保留其中所有小于10的數字,其余的數字刪掉
方案:可以遍歷一遍數據,將所有小于10的數字全部放到數組的最左側,最終,數組的0~m(0<=m<=n)位置全部都是小于10的數字,然后我們只需要刪除m+1~n的所有數字即可
這種方法的優點也顯而易見:
但是依然還是有缺點的:
分代收集算法
別急,我們還沒說完,還有最后一個分代收集算法,這個算法將Java堆劃分為兩塊區域:
可以看出,分代收集算法按照對象在GC后的存活率將Java堆分為這樣兩塊區域,針對不同區域采用不同的算法,就能盡可能地做到“揚長補短”,來提高垃圾回收的效率
總結
最后,垃圾回收的幾種常見算法已經為大家介紹完畢,接下來如果有機會我會再介紹一下幾種常見的垃圾回收器
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





