溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Python中怎么實現文本數據預處理,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
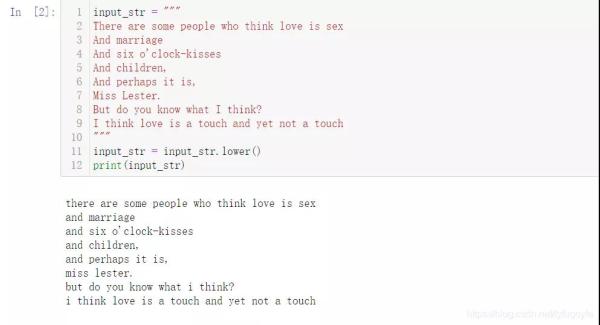
input_str = """ There are some people who think love is sex And marriage And six o'clock-kisses And children, And perhaps it is, Miss Lester. But do you know what I think? I think love is a touch and yet not a touch """ input_str = input_str.lower() print(input_str)
結果如下:
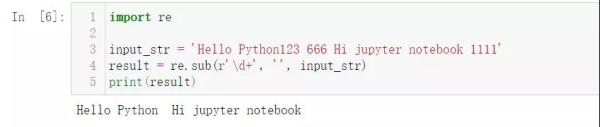
如果文本中的數字與文本分析無關的話,那就刪除這些數字。
import re input_str = 'Hello Python123 666 Hi jupyter notebook 1111' result = re.sub(r'\d+', '', input_str) print(result)
結果如下:
而在有些情況下,比如獲取的數據中,招聘崗位信息里薪資是 15K 這樣的,商品購買信息里商品購買人數是 8500+ 人購買了此商品,這時我們需要從中提取出數字。
input_str = '薪資:15K 8500+人付款 3.0萬+人付款' result = re.findall("-?\d+\.?\d*e?-?\d*?", input_str) print(result)結果如下:

import re input_str = """This &is [an] example? \葉庭云<< 1""!。。;11???【】>>1 *yetingyun/p:?| {of} string. with.? punctuation!!!!""" s = re.sub(r'[^\w\s]', '', input_str) print(s)結果如下:

可以看到文本中亂七八糟的符號都被濾除了,用正則表達式過濾文本中的標點符號,如果空白符也需要過濾,可以使用 r'[^\w]'。原理很簡單:在正則表達式中,\w 匹配字母或數字或下劃線或漢字(具體與字符集有關),^\w表示相反匹配。
input_str = " \t yetingyun \t " input_str = input_str.strip() input_str
結果如下:

# 從Github下載停用詞數據 https://github.com/zhousishuo/stopwords import jieba import re # 讀取用于測試的文本數據 用戶評論 with open('comments.txt') as f: data = f.read() # 文本預處理 去除一些無用的字符 只提取出中文出來 new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S) new_data = "/".join(new_data) # 文本分詞 精確模式 seg_list_exact = jieba.cut(new_data, cut_all=False) # 加載停用詞數據 with open('stop_words.txt', encoding='utf-8') as f: # 獲取每一行的停用詞 添加進集合 con = f.read().split('\n') stop_words = set() for i in con: stop_words.add(i) # 列表解析式 去除停用詞和單個詞 result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1] result_list結果如下:
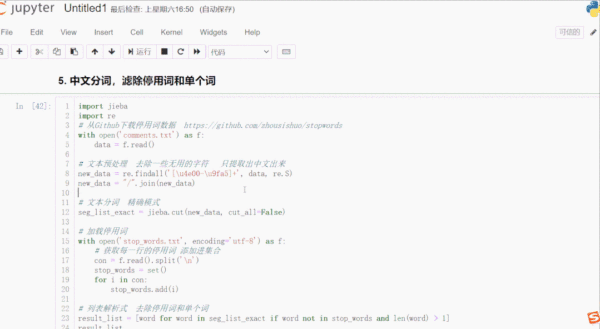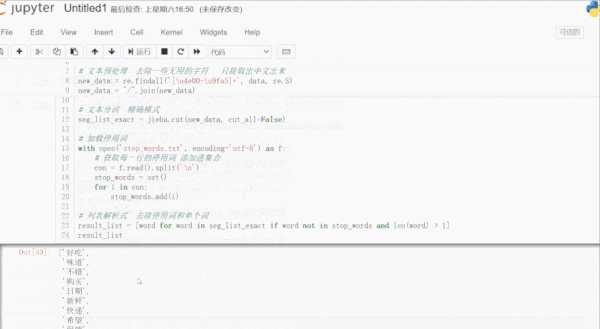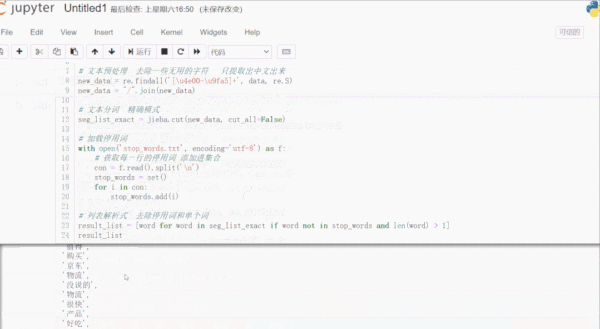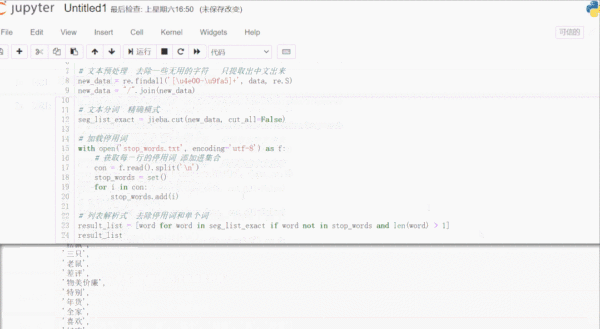
首先讀取用于測試的文本數據,該數據是爬取的商品評論,這一類數據通常有很多無意義的字詞和符號,通過正則表達式濾除掉無用的符號,只提取出中文出來。使用 jieba 庫進行文本分詞,加載停用詞數據到集合,然后一行列表解析式濾除停用詞和單個詞,這樣效率很高。停用詞數據可以下載一些公開的,再根據實際文本處理需要,添加字詞語料進去,使濾除效果更好。
Github下載停用詞數據:https://github.com/zhousishuo/stopwords
SnowNLP是一個 Python 寫的類庫,可以方便的處理中文文本內容,是受到了 TextBlob 的啟發而寫的,由于現在大部分的自然語言處理庫基本都是針對英文的,于是寫了一個方便處理中文的類庫,并且和 TextBlob 不同的是,這里沒有用NLTK,所有的算法都是自己實現的,并且自帶了一些訓練好的字典。注意本程序都是處理的 unicode 編碼,所以使用時請自行 decode 成 unicode 編碼。
使用 SnowNLP 處理中文文本數據非常方便,以詞性標注和關鍵詞提取為例:
from snownlp import SnowNLP word = u'今天天氣好 這個姑娘真好看' s = SnowNLP(word) print(s.words) # 分詞 print(list(s.tags)) # 詞性標注

from snownlp import SnowNLP text = u''' 自然語言處理是計算機科學領域與人工智能領域中的一個重要方向。 它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。 自然語言處理是一門融語言學、計算機科學、數學于一體的科學。 因此,這一領域的研究將涉及自然語言,即人們日常使用的語言, 所以它與語言學的研究有著密切的聯系,但又有重要的區別。 自然語言處理并不是一般地研究自然語言, 而在于研制能有效地實現自然語言通信的計算機系統, 特別是其中的軟件系統。因而它是計算機科學的一部分。 ''' s = SnowNLP(text) print(s.keywords(limit=6)) # 關鍵詞提取
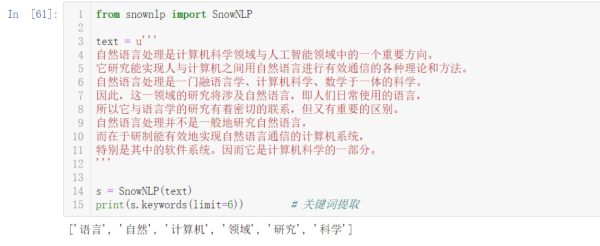
上述就是小編為大家分享的Python中怎么實現文本數據預處理了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





