溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關ThreadPoolExecutor的CallerRunsPolicy拒絕策略是什么,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
首先介紹一下ThreadPoolExecutor構造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}corePoolSize:核心線程數量,當有新任務在execute()方法提交時,會執行以下判斷:
如果運行的線程少于 corePoolSize,則創建新線程來處理任務,即使線程池中的其他線程是空閑的;
如果線程池中的線程數量大于等于 corePoolSize 且小于 maximumPoolSize,則只有當workQueue滿時才創建新的線程去處理任務;
如果設置的corePoolSize 和 maximumPoolSize相同,則創建的線程池的大小是固定的,這時如果有新任務提交,若workQueue未滿,則將請求放入workQueue中,等待有空閑的線程去從workQueue中取任務并處理;
如果運行的線程數量大于等于maximumPoolSize,這時如果workQueue已經滿了,則通過handler所指定的策略來處理任務
所以,任務提交時,判斷的順序為 corePoolSize –> workQueue –> maximumPoolSize。
maximumPoolSize:最大線程數量
workQueue:等待隊列,當任務提交時,如果線程池中的線程數量大于等于corePoolSize的時候,把該任務封裝成一個Worker對象放入等待隊列;
keepAliveTime:線程池維護線程所允許的空閑時間。當線程池中的線程數量大于corePoolSize的時候,如果這時沒有新的任務提交,核心線程外的線程不會立即銷毀,而是會等待,直到等待的時間超過了keepAliveTime;
threadFactory:它是ThreadFactory類型的變量,用來創建新線程。默認使用Executors.defaultThreadFactory() 來創建線程。使用默認的ThreadFactory來創建線程時,會使新創建的線程具有相同的NORM_PRIORITY優先級并且是非守護線程,同時也設置了線程的名稱。
handler:它是RejectedExecutionHandler類型的變量,表示線程池的飽和策略。如果阻塞隊列滿了并且沒有空閑的線程,這時如果繼續提交任務,就需要采取一種策略處理該任務。線程池提供了4種策略:
AbortPolicy:直接拋出異常,這是默認策略;
CallerRunsPolicy:用調用者所在的線程來執行任務;
DiscardOldestPolicy:丟棄阻塞隊列中靠最前的任務,并執行當前任務;
DiscardPolicy:直接丟棄任務;
簡單來說,在執行execute()方法時如果狀態一直是RUNNING時,的執行過程如下:
如果workerCount < corePoolSize,則創建并啟動一個線程來執行新提交的任務;
如果workerCount >= corePoolSize,且線程池內的阻塞隊列未滿,則將任務添加到該阻塞隊列中;
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且線程池內的阻塞隊列已滿,則創建并啟動一個線程來執行新提交的任務;
如果workerCount >= maximumPoolSize,并且線程池內的阻塞隊列已滿, 則根據拒絕策略來處理該任務, 默認的處理方式是直接拋異常。
測試當拒絕策略是CallerRunsPolicy時,用調用者所在的線程來執行任務,是什么現象。
jdk 1.8
postman模擬并發
mysql5.7
intellj
springboot 2.1.4.RELEASE
本實驗代碼,在https://github.com/vincentduan/mavenProject 下的threadManagement目錄下。
1. 首先配置maven pom.xml文件內容,關鍵內容如下:
<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.1.4.RELEASE</version> <scope>import</scope> <type>pom</type> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.6</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.6</version> </dependency>
2. 配置數據庫連接池:
@SpringBootConfiguration
public class DBConfiguration {
@Autowired
private Environment environment;
@Bean
public DataSource createDataSource() {
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUrl(environment.getProperty("spring.datasource.url"));
druidDataSource.setUsername(environment.getProperty("spring.datasource.username"));
druidDataSource.setPassword(environment.getProperty("spring.datasource.password"));
druidDataSource.setDriverClassName(environment.getProperty("spring.datasource.driver-class-name"));
return druidDataSource;
}
}3. 配置線程池:
@Configuration
@EnableAsync
@Slf4j
public class ExecutorConfig {
@Autowired
VisiableThreadPoolTaskExecutor visiableThreadPoolTaskExecutor;
@Bean
public Executor asyncServiceExecutor() {
log.info("start asyncServiceExecutor");
ThreadPoolTaskExecutor executor = visiableThreadPoolTaskExecutor;
//配置核心線程數
executor.setCorePoolSize(5);
//配置最大線程數
executor.setMaxPoolSize(5);
//配置隊列大小
executor.setQueueCapacity(5);
//配置線程池中的線程的名稱前綴
executor.setThreadNamePrefix("async-service-");
// rejection-policy:當pool已經達到max size的時候,如何處理新任務
// CALLER_RUNS:不在新線程中執行任務,而是有調用者所在的線程來執行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//執行初始化
executor.initialize();
return executor;
}
}VisiableThreadPoolTaskExecutor類作為一個bean,并且繼承了ThreadPoolTaskExecutor;
4. 接下來創建一個service,為了模擬并發,我們將方法執行sleep了30秒。如下:
@Service
@Slf4j
public class UserThreadServiceImpl implements UserThreadService {
@Autowired
UserThreadDao userThreadDao;
@Override
@Async("asyncServiceExecutor")
public void serviceTest(String username) {
log.info("開啟執行一個Service, 這個Service執行時間為30s, threadId:{}",Thread.currentThread().getId());
userThreadDao.add(username, Integer.parseInt(Thread.currentThread().getId() +""), "started");
try {
Thread.sleep(30000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("執行完成一個Service, threadId:{}",Thread.currentThread().getId());
userThreadDao.update(username, Integer.parseInt(Thread.currentThread().getId() +""), "ended");
}
@Override
public void update(String username, int threadId, String status) {
userThreadDao.update(username, threadId, status);
}
}5. 其中的dao很簡單,就是往數據庫插入數據和更新數據。
6. 創建web Controller:
@RestController
@RequestMapping("/serviceTest")
public class TestController {
@Autowired
UserThreadService userThreadService;
@Autowired
private VisiableThreadPoolTaskExecutor visiableThreadPoolTaskExecutor;
@GetMapping("test/{username}")
public Object test(@PathVariable("username") String username) {
userThreadService.serviceTest(username);
JSONObject jsonObject = new JSONObject();
ThreadPoolExecutor threadPoolExecutor = visiableThreadPoolTaskExecutor.getThreadPoolExecutor();
jsonObject.put("ThreadNamePrefix", visiableThreadPoolTaskExecutor.getThreadNamePrefix());
jsonObject.put("TaskCount", threadPoolExecutor.getTaskCount());
jsonObject.put("completedTaskCount", threadPoolExecutor.getCompletedTaskCount());
jsonObject.put("activeCount", threadPoolExecutor.getActiveCount());
jsonObject.put("queueSize", threadPoolExecutor.getQueue().size());
return jsonObject;
}
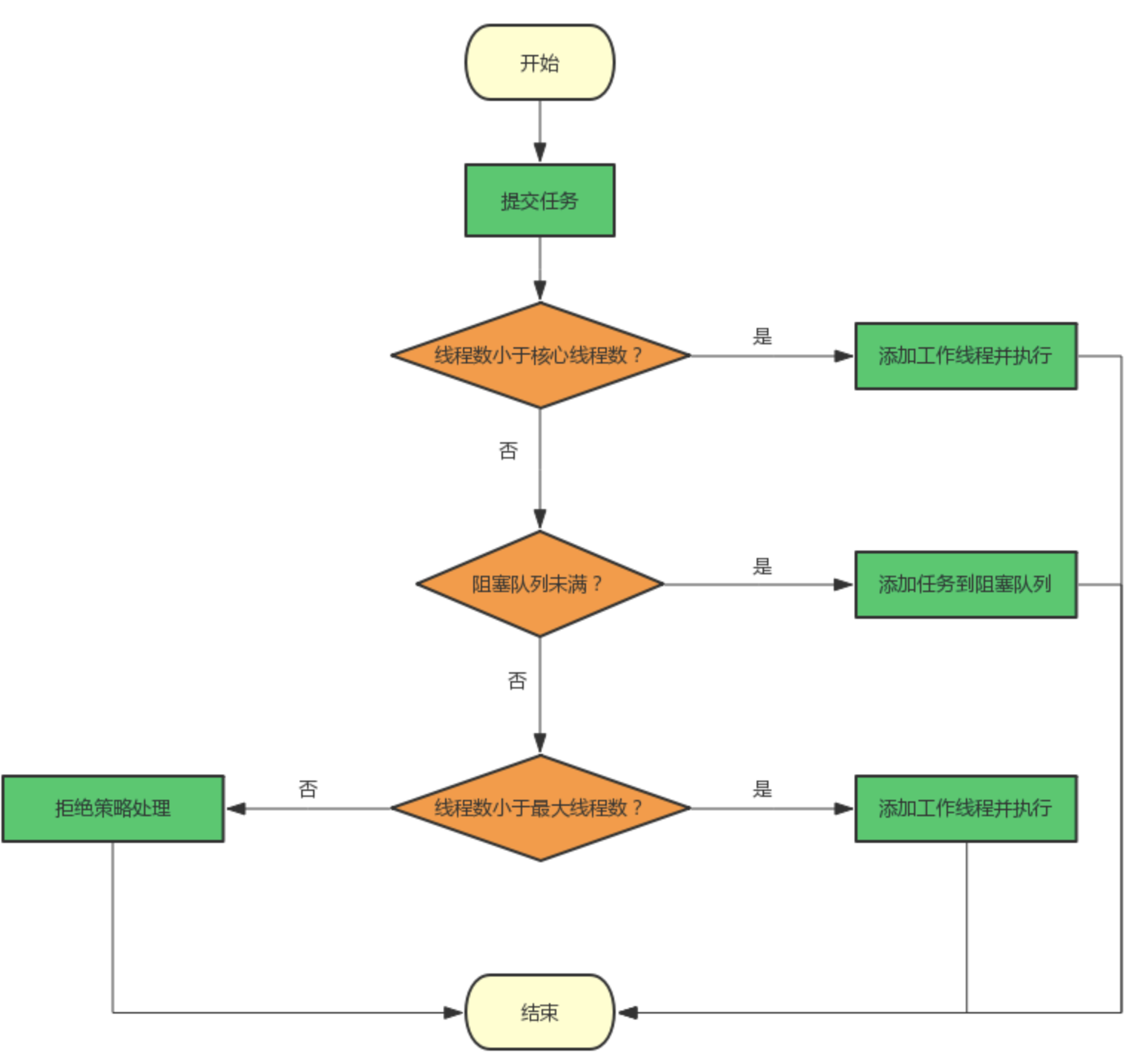
}因為CorePoolSize數量是5,MaxPoolSize也是5,因此線程池的大小是固定的。而QueueCapacity數量也是5。因此當請求前5次時,返回響應:
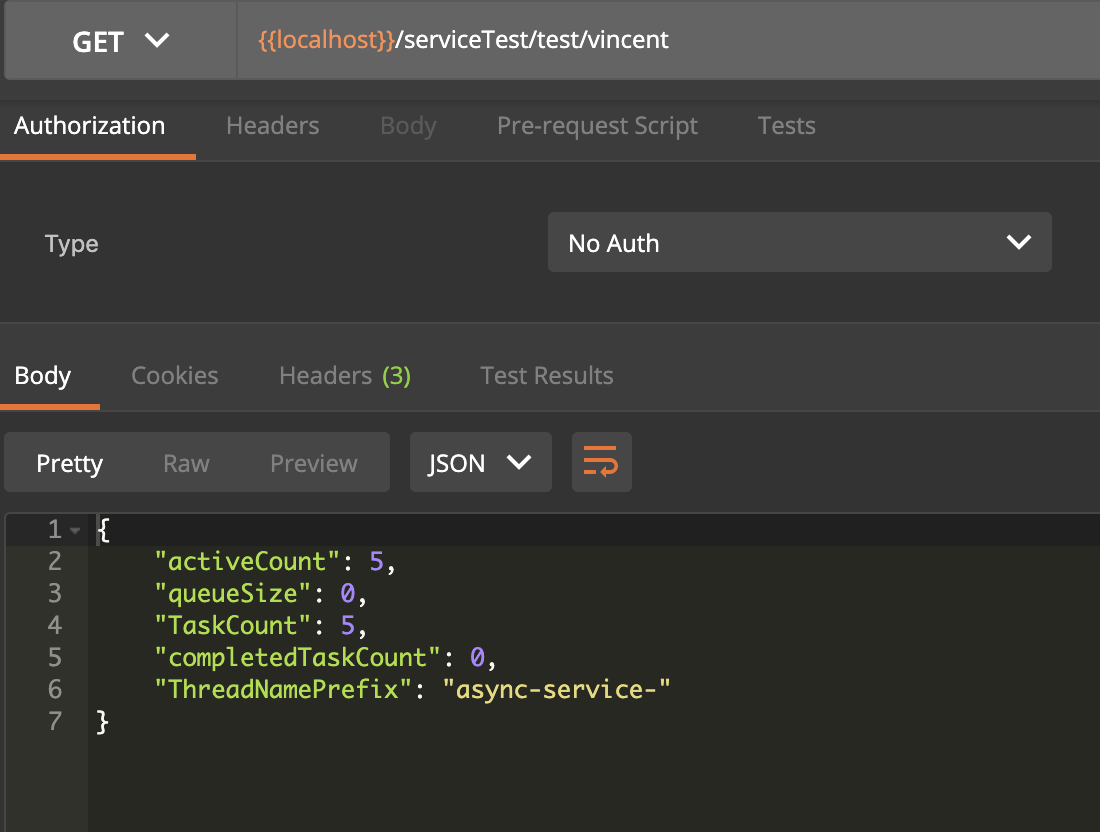
當前線程數達到CorePoolSize時,新來的請求就會進入到workQueue中,如下所示:
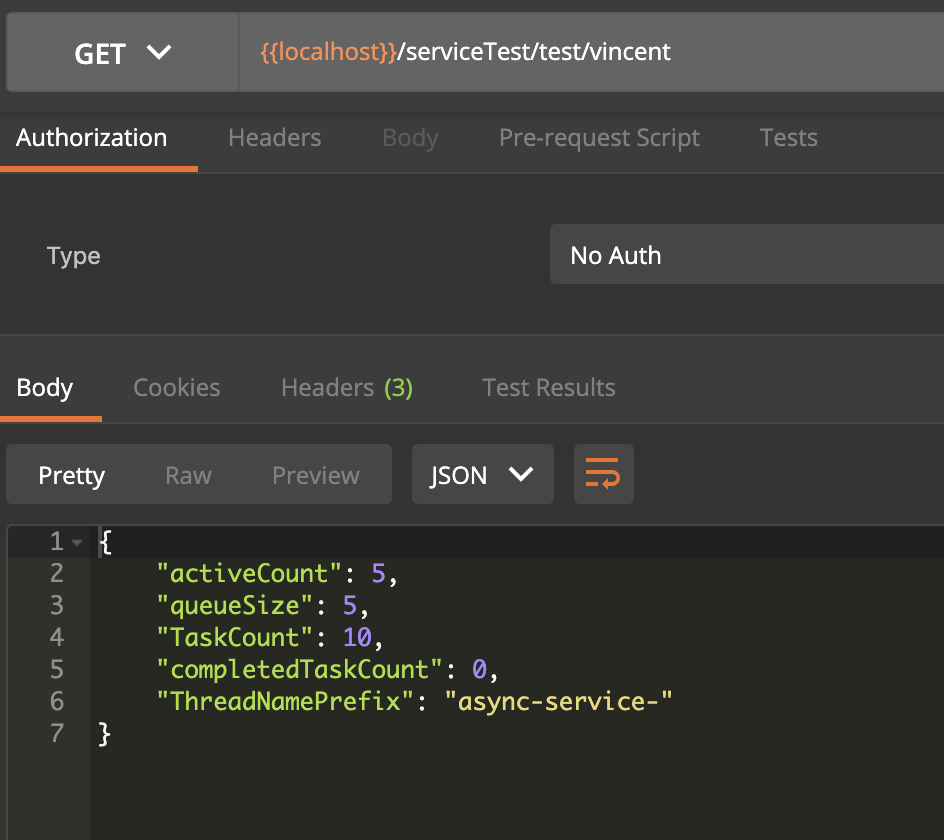
而QueueCapacity的數量也是5,因此達到QueueCapacity的最大限制后,同時也達到了MaxPoolSize的最大限制,將會根據拒絕策略來處理該任務,這里的策略是CallerRunsPolicy時,用調用者所在的線程來執行任務,表現為當前頁面被阻塞住了,直到當前調用者所在的線程執行完畢。如下所示:
從控制臺的輸出也能看出CallerRunsPolicy策略執行線程是調用者線程:
2019-08-19 21:06:50.255 INFO 1302 --- [async-service-4] c.a.i.s.impl.UserThreadServiceImpl : 開啟執行一個Service, 這個Service執行時間為30s, threadId:51 2019-08-19 21:06:50.271 INFO 1302 --- [async-service-4] cn.ac.iie.dao.UserThreadDao : threadId:51, jdbcTemplate:org.springframework.jdbc.core.JdbcTemplate@5d83694c 2019-08-19 21:06:50.751 INFO 1302 --- [async-service-5] c.a.i.s.impl.UserThreadServiceImpl : 開啟執行一個Service, 這個Service執行時間為30s, threadId:52 2019-08-19 21:06:50.771 INFO 1302 --- [async-service-5] cn.ac.iie.dao.UserThreadDao : threadId:52, jdbcTemplate:org.springframework.jdbc.core.JdbcTemplate@5d83694c 2019-08-19 21:06:55.028 INFO 1302 --- [nio-8080-exec-1] c.a.i.s.impl.UserThreadServiceImpl : 開啟執行一個Service, 這個Service執行時間為30s, threadId:24 2019-08-19 21:06:55.036 INFO 1302 --- [nio-8080-exec-1] cn.ac.iie.dao.UserThreadDao : threadId:24, jdbcTemplate:org.springframework.jdbc.core.JdbcTemplate@5d83694c
其中[nio-8080-exec-1]表示就是調用者的線程。而其他線程都是[async-service-]
關于ThreadPoolExecutor的CallerRunsPolicy拒絕策略是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





