溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了MySQL中排序速度慢如何解決,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
一、具體現象
有一個功能,按照算法得出的權重值,分頁展示一批列表數據,權重值越大越靠前。研發同學反饋查詢速度慢且排序不穩定。
排序不穩定的具體現象,有不少記錄存在相同權重值,某條記錄(假設id=100)第一頁出現了,翻到第二頁可能還有它(采用的limit控制哪一頁)。
第1頁數據
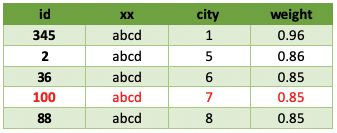
第2頁數據
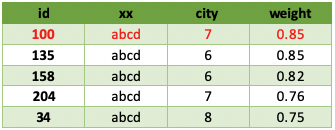
一個主表A,左連接兩個表B、C,根據C的權重字段排序。具體SQL如下

二、問題分析
查看SQL語句的執行計劃(EXPLAIN),發現有Using filesort的字樣。
趕緊搜索一下MySQL說明文檔,第一條是排序優化
文檔中有這么一句話“如果索引不能滿足ORDERBY子句,MySQL將執行文件排序(filesort)操作,讀取數據行并對其進行排序。文件排序構成查詢執行中的額外排序階段。”
顯然,利用索引實現有序,比采用filesort更高效。filesort并不一定都通過磁盤排序,數據量不大的時候是在內存里完成。速度不夠快的原因找到了。
filesort的時候可能在內存中出現堆排序列或快速排序兩種方式,具體使用哪一種排序方式是優化器決定的,基本原則如下
快速排序算法:大量排序
堆排序算法:排序量不大
快速排序和堆排序是不穩定的排序算法,對于重復值不能保證順序。Order by排序不穩定的原因也定位到了
了解一下filesort的原理
(1)根據表的索引或者全表掃描,讀取所有滿足條件的記錄。
(2)對于每一行,存儲一對值到緩沖區(排序列,行記錄指針),一個是排序的索引列的值,即order by用到的列值,和指向該行數據的行指針,緩沖區的大小為sort_buffer_size大小。
(3)當緩沖區滿后,運行一個快速排序(qsort)來將緩沖區中數據排序,并將排序完的數據存儲到一個臨時文件,并保存一個存儲塊的指針,當然如果緩沖區不滿,則不會重建臨時文件了。
(4)重復以上步驟,直到將所有行讀完,并建立相應的有序的臨時文件。
(5)對塊級進行排序,這個類似歸并排序算法,只通過兩個臨時文件的指針來不斷交換數據,最終達到兩個文件,都是有序的。
(6)重復5直到所有的數據都排序完畢。
(7)采取順序讀的方式,將每行數據讀入內存(這里讀取數據時并不是一行一行讀),并取出數據傳到客戶端,讀取緩存大小由read_rnd_buffer_size來指定。
三、怎么優化
1、利用索引達到排序目的(針對例子的優化)
針對文章開始的例子,優化原則是Use of Indexes to Satisfy ORDER BY(讓ORDER BY用上索引),即提升查詢效率,又保證穩定性(索引B+樹葉子結點的順序是唯一且一定的)
MySQL的文檔列出若干具體的case,把最主要整理出來如下。

MySQL文檔中有這么一句話 “該查詢連接了許多表,并且ORDER BY中的列并非全部來自用于檢索行的第一個非恒定表。”,滿足這類型的SQL也不能利用索引排序。這就是文章開頭的例子。另外,使用別名,如果跟表的列名沖突可能導致索引排序失效。
看到有些文章寫到下面這條語句ORDER BY不能利用索引

這個說法顯然與MySQL官方文檔不一致。我覺得,這個語句能不能使用索引,跟數據庫引擎根據開銷決定是否檢索的階段使用索引有關。
2、優化filesort
如果確實沒辦法利用索引,可以想辦法優化filesort排序。
如果結果集太大內存裝不下,filesort將根據需要使用臨時磁盤文件。磁盤io速度你懂的!MySQL官方建議可以調大排序緩存參數sort_buffer_size,MySQL 8.0還對緩存利用率做了優化,調大一點也不浪費。以前版本的MySQL可以求助DBA。
可以這樣優化的典型SQL 語句如下


上述內容就是MySQL中排序速度慢如何解決,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





