從排序原理到MYSQL中的排序方式
本文參考
MYSQL官方文檔,算法書籍,部分為自己觀點可能有誤,如果有誤請指出共同討論
轉載請說明出處,謝謝!
一、MYSQL排序可能用到的排序算法
從MYSQL官方文檔和源碼的接口來看MYSQL使用BUFFER內部快速排序算法,外部多路歸并排序算法,相應的接口函數為
filesort()函數,注意filesort()是一個總的接口,內部排序實際調用save_index()下的
std::stable_sort\std::sort、歸并排序
也包含在下面接口可能為merge_many_buff(),也就像執行計劃中
using filesort的含義,他只能代表使用了排序,但是
是否使用到tempfile排序是看不出來的,但是這個可以再trace看到但是線上是不可以trace的研究是可以的,隨后我會演示。
還要注意
using temporary只是說明使用了臨時表存儲中間結果,這里先不討論,只看排序。
下面簡要介紹兩種算法原理
1、buffer內部 快速排序算法
快速排序是交換排序類算法,是冒泡排序的升級版,其原理是采用分而治之的思想,在于每趟交換設置一個基準點,
將大于這個基準點的數據放到一邊,大于的放到另一邊,不斷的進行遞歸完成,對于大數據量的排序快速排序一般
效率優秀,在文章的最后是一個簡單的快速排序的實現,如果對算法感興趣的可以參考一下。但是至少還能進
行3種優化
--小數據優化,因為快速排序對數據量小的時候并不是最優,可以使用其他排序算法如插入排序。
--尾遞歸優化,減少棧的使用
--基準點優化,盡量取到數據中的中間值作為基準點,這樣能夠讓快速排序更加優化。
2、外部磁盤多路歸并排序
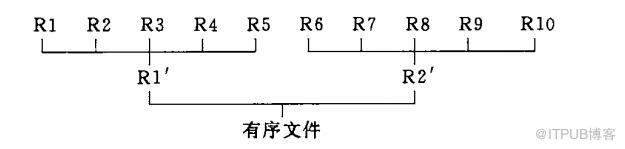
將內部快速排序后有序的數據文件進行不斷的比較得到有序的文件,每次歸并多少個文件就是歸并的路數
圖中每一個R當然代表的一個有序的磁盤文件
下圖2路歸并排序(截取數據結構C語言版)
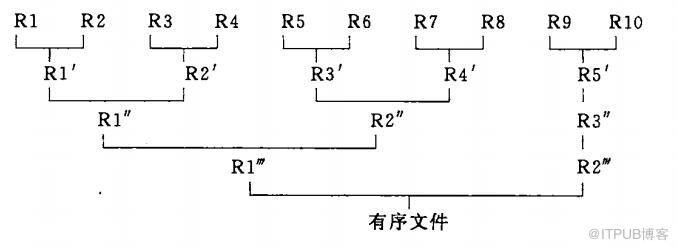
下圖5路歸并排序(
截取數據結構C語言版)
二、MYSQL相關參數
sort_buffer_size:
當然也就是每次排序的buffer,用作內部快速排序用,如果buffer越大當然產生的物理文件也就越少,但是這個
參數是會話級別的,過分加大會造成內存不足,默認256K。注意:
On Linux, there are thresholds of 256KB and
2MB where larger values may significantly slow down memory allocation, so you should consider staying
below one of those values
read_rnd_buffer_size:
除了MRR用到,這里也用到了用于 二次排序的時候對排序好的數據按照primary key(ROW_ID)按照分塊的方式再次排序,
意義同樣在回表取數據可以盡量順序化
max_length_for_sort_data:
單位為字節(bytes),如果排序返回行的字段長度綜合大約這個值,使用二次排序而不是一次排序,默認1024,最小
值為4,如果加大這個值可能過多的使用一次排序造成高TEMPFILE空間使用而CPU不高,為什么如此后面解釋。
max_sort_length:
單位為字節(bytes),如果排序字段的長度超過這個值,只是用這個參數設置的長度,默認1024,比如text這種字段
經常會大于這個值,如果加大這個值明顯會提高排序的準確性,但是也意味著更高的BUFFER使用和TEMPFILE使用
三、監控磁盤排序
Sort_merge_passes:磁盤排序歸并次數,減少sort_buffer_size大小會顯著減少Sort_merge_passes值,并且臨時文件也
會變少,第五部分證明
sys.statements_with_sorting視圖
四、MYSQL二次訪問排序(original method)和一次訪問排序(modified method)
1、二次訪問排序
--讀取數據只包含排序鍵值和rowid(primary key)放到sort buffer
--在buffer中進行快速排序,如果buffer 滿則把內存中的排序數據寫入tempfile
--重復上面的過程直到內部快速排序完成,并且生成多個tmepfile文件
--進行多路歸并排序源碼接口在merge_many_buff(),其中定義了MERGEBUFF,MERGEBUFF2 2個宏
這個在官方文檔上有出現所以提出來說明一下
/* Defines used by filesort and uniques */
#define MERGEBUFF 7
#define MERGEBUFF2 15
如果有興趣的可以仔細看看源碼..
--最后一次歸并的時候,只有rowid(priamry key)到最后的文件中
--對最后的文件根據rowid(primary key)訪問表數據,這樣就可以得到排序好的數據
這里有一個類似MRR的優化,將數據進行分塊讀入read_rnd_buffer_size進行
按照rowid(primary key)排序在去訪問表的數據,目的在于減少隨機讀取造成的影響
但是這是分塊的,只能減少不能杜絕,特別是數據量特別大的情況下,因為
read_rnd_buffer_size只有默認256K.
問題在于對表數據的二次訪問,一次在讀取數據的時候,后一次在通過排序好的
rowid(primary key)進行數據的訪問,并且會出現大量隨機訪問。
2、一次訪問排序
這個就簡單了,二次訪問排序是把排序鍵值和rowid(primary key)放到sort buffer,
這個就是關于需要的數據字段全部放到sort buffer比如:
select id,name1,name2 from test order by id;
這里id,name1,name2都會存放到sort buffer中。這樣排序好就好了,不需要回表取
數據了,當然這樣做的劣勢就是更大的sort buffer占用,更大tempfile占用。所以
mysql使用max_length_for_sort_data來限制默認1024,這是指id,name1,name2字段
的bytes長度。
因為不需要回表,所以只要一次訪問數據
3、5.7.3后一次訪問排序算法的優化
使用一個叫做pack優化的方法,目的在于壓縮NULL減少一次訪問排序算法對sort buffer和tempfile的過多使用
原文:
without packing, a VARCHAR(255)
column value containing only 3 characters takes 255 characters in the sort buffer. With packing,
the value requires only 3 characters plus a two-byte length indicator. NULL values require only
a bitmask.
但是我在做MYSQL TRACE的時候發現這還有一個unpack的過程,并且每一行每一個字段都需要pack unpack
隨后證明
關于使用了的那種排序方式在執行計劃中都體現為filesort不好弄清楚,但是我們可以通過trace的方式,
在官方文檔也說了,但是我使用了對MYSQLD的trace方式來做,效果一致,詳細參考第五部分
五、證明觀點
1、首先需要證明是使用的是二次訪問排序還是一次訪問排序,是否啟用了pack
官方文檔說明
"filesort_summary": {
"rows": 100,
"examined_rows": 100,
"number_of_tmp_files": 0,
"sort_buffer_size": 25192,
"sort_mode": ""
}
sort_mode:
: This indicates use of the original algorithm.
: This indicates use of the modified algorithm.
: This indicates use of the modified algorithm. Sort
buffer tuples contain the sort key value and packed columns referenced by the query.
也就是說
sort_key, rowid是二次訪問排序
sort_key, additional_fields是一次訪問排序
sort_key, packed_additional_fields是一次訪問排序+pack方式
好了我們來證明,使用測試表
mysql> show create table testmer \G;
*************************** 1. row ***************************
Table: testmer
Create Table: CREATE TABLE `testmer` (
`seq` int(11) NOT NULL,
`id1` int(11) DEFAULT NULL,
`id2` int(11) DEFAULT NULL,
`id3` int(11) DEFAULT NULL,
`id4` int(11) DEFAULT NULL,
PRIMARY KEY (`seq`),
KEY `id1` (`id1`,`id2`),
KEY `id3` (`id3`,`id4`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.01 sec)
mysql> select * from testmer ;
+-----+------+------+------+------+
| seq | id1 | id2 | id3 | id4 |
+-----+------+------+------+------+
| 1 | 1 | 2 | 4 | 4 |
| 2 | 1 | 3 | 4 | 5 |
| 3 | 1 | 2 | 4 | 4 |
| 4 | 2 | 4 | 5 | 6 |
| 5 | 2 | 6 | 5 | 8 |
| 6 | 2 | 10 | 5 | 3 |
| 7 | 4 | 5 | 8 | 10 |
| 8 | 0 | 1 | 3 | 4 |
+-----+------+------+------+------+
8 rows in set (0.01 sec)
分別在max_length_for_sort_data為1024和max_length_for_sort_data為4對
select * from testmer order by id1;
生成trace文件
意義也就是使用一次訪問排序和二次訪問排序,因為數據量少也就在sort_buffer
排序就好了。
一次訪問排序:
opt: filesort_execution: ending struct
opt: filesort_summary: starting struct
opt: rows: 8
opt: examined_rows: 8
opt: number_of_tmp_files: 0
opt: sort_buffer_size: 34440
opt: sort_mode: ""
opt: filesort_summary: ending struct
為 一次訪問排序+pack方式
二次訪問排序:
opt: filesort_execution: ending struct
opt: filesort_summary: starting struct
opt: rows: 8
opt: examined_rows: 8
opt: number_of_tmp_files: 0
opt: sort_buffer_size: 18480
opt: sort_mode: ""
opt: filesort_summary: ending struct
為是二次訪問排序
可以看到不同,證明了max_length_for_sort_data的作用
其實這個是filesort()函數中的一個調用而已,其實gdb也可以打上斷點也能看到
Opt_trace_object(trace, "filesort_summary")
.add("rows", num_rows)
.add("examined_rows", param.examined_rows)
.add("number_of_tmp_files", num_chunks)
.add("sort_buffer_size", table_sort.sort_buffer_size())
.add_alnum("sort_mode",
param.using_packed_addons() ?
"" :
param.using_addon_fields() ?
"" : "");
2、證明減少sort_buffer_size大小會顯著減少Sort_merge_passes值,并且臨時文件也
會變少
為了完成這個證明我建立了一個大表,降低先sort_buffer為使用如下的語句使用更多的
tempfile進行排序
mysql> select count(*) from testshared3;
+----------+
| count(*) |
+----------+
| 1048576 |
+----------+
1 row in set (28.31 sec)
mysql> set sort_buffer_size=50000;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%sort_buffer_size%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| sort_buffer_size | 50000 |
+-------------------------+---------+
mysql> show status like '%Sort_merge%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
+-------------------+-------+
1 row in set (0.00 sec)
mysql> explain select * from testshared3 order by id limit 1048570,1;
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| 1 | SIMPLE | testshared3 | NULL | ALL | NULL | NULL | NULL | NULL | 1023820 | 100.00 | Using filesort |
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
mysql> select * from testshared3 order by id limit 1048570,1;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (5 min 4.76 sec)
完成后
mysql> show status like '%Sort_merge%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 63 |
+-------------------+-------+
1 row in set (0.21 sec)
opt: number_of_tmp_files: 378
臨時文件數量378
然后加大sort_buffer_size
mysql> show variables like '%sort_buffer_size%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| sort_buffer_size | 262144 |
+-------------------------+---------+
mysql> show status like '%Sort_merge%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
+-------------------+-------+
1 row in set (0.04 sec)
還是同樣的語句
mysql> select * from testshared3 order by id limit 1048570,1;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (5 min 4.76 sec)
mysql> show status like '%Sort_merge%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 11 |
+-------------------+-------+
opt: number_of_tmp_files: 73
臨時文件數量73
得到證明
3、證明有pack和unpack操作,并且每一行每一個字段都需要pack unpack
這個直接查看trace文件是否有接口就好了
實際上可以看到8段如下的操作
>Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack"|wc -l
40
[root@testmy tmp]# cat sortys2.trace|grep ">Field::pack"|wc -l
40
剛好是5(字段)*8(行)
當然我隨后對一個大表只有一個字段的表進行一樣的測試,既然是一個字段使用
一次訪問排序的時候排序的全部字段就是這個字段而已,所以pack和unpack的次數應該
和行數差不多
mysql> select count(*) from testshared3;
+----------+
| count(*) |
+----------+
| 1048576 |
+----------+
1 row in set (28.31 sec)
mysql> desc testshared3;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.26 sec)
[root@testmy tmp]# cat mysqld11.trace|grep ">Field::unpack"|wc -l
1048571
也得到同樣基本相同的結構,證明了一次訪問排序中每一行每一個字段都需
要pack、unpack操作,其實在整個trace中還能看到很多類容比如列取出了
一次訪問排序的全部字段,這里就不在詳解了
六、源碼GDB發現內部排序調用STD容器的std::stable_sort std::sort 進行排序
(gdb) n
250 if (param->sort_length < 10)
(gdb) list
245 than quicksort seems to be somewhere around 10 to 40 records.
246 So we're a bit conservative, and stay with quicksort up to 100 records.
247 */
248 if (count <= 100)
249 {
250 if (param->sort_length < 10)
251 {
252 std::sort(m_sort_keys, m_sort_keys + count,
253 Mem_compare(param->sort_length));
254 return;
這部分mysql上的源碼
-
/*
-
std::stable_sort has some extra overhead in allocating the temp buffer,
-
which takes some time. The cutover point where it starts to get faster
-
than quicksort seems to be somewhere around 10 to 40 records.
-
So we're a bit conservative, and stay with quicksort up to 100 records.
-
*/
-
if (count <= 100)
-
{
-
if (param->sort_length < 10)
-
{
-
std::sort(m_sort_keys, m_sort_keys + count,
-
Mem_compare(param->sort_length));
-
return;
-
}
-
std::sort(m_sort_keys, m_sort_keys + count,
-
Mem_compare_longkey(param->sort_length));
-
return;
-
}
-
// Heuristics here: avoid function overhead call for short keys.
-
if (param->sort_length < 10)
-
{
-
std::stable_sort(m_sort_keys, m_sort_keys + count,
-
Mem_compare(param->sort_length));
-
return;
-
}
-
std::stable_sort(m_sort_keys, m_sort_keys + count,
-
Mem_compare_longkey(param->sort_length));
最后附上快速排序的代碼
帶排序數據是13,3,2,9,34,5,102,90,20,2
排序完成后如下:
gaopeng@bogon:~/datas$ ./a.out
sort result:2 2 3 5 9 13 20 34 90 102
-
/*************************************************************************
-
> File Name: qsort.c
-
> Author: gaopeng QQ:22389860
-
> Mail: gaopp_200217@163.com
-
> Created Time: Fri 06 Jan 2017 03:04:08 AM CST
-
************************************************************************/
-
-
-
#include<stdio.h>
-
#include<stdlib.h>
-
-
-
int partition(int *k,int low,int high)
-
{
-
-
int point;
-
point = k[low]; //基準點,采用數組的第一個值,這里實際可以優化
-
while(low<high) //等待low=high一趟交換完成
-
{
-
-
while(low<high && k[high] >=point) //過濾掉尾部大于基準點的值,不需要交換
-
{
-
high--;
-
}
-
k[low] = k[high]; //基準點多次交換為無謂交換直接賦值即可
-
while(low<high && k[low] <=point) //過濾掉頭部小于基準點的值,不需要交換
-
{
-
-
low++;
-
}
-
k[high] = k[low]; //基準點多次交換為無謂交換直接賦值即可
-
}
-
k[low] = point;
-
return low;
-
}
-
-
int q_sort(int *k,int low,int high)
-
{
-
-
int point;
-
if(low<high)
-
{
-
-
point = partition(k,low,high);
-
q_sort(k,low,point-1); //實現遞歸前半部分
-
q_sort(k,point+1,high); //實現遞歸后半部分
-
}
-
return 0;
-
}
-
-
int main()
-
{
-
-
int i,a[10]={13,3,2,9,34,5,102,90,20,2}; //測試數據
-
q_sort(a,0,9); //數組下標0 9
-
-
printf("sort result:");
-
for(i=0;i<10;i++)
-
{
-
printf("%d ",a[i]);
-
}
-
printf("\n");
-
}





