溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Flink的常見問題診斷思路是什么,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
1.常見運維問題
文中介紹的作業運行環境主要是在阿里巴巴集團內,構建在 Hadoop 生態之上的 Flink 集群,包含 Yarn、HDFS、ZK 等組件;作業提交模式采用 yarn per-job Detached 模式。
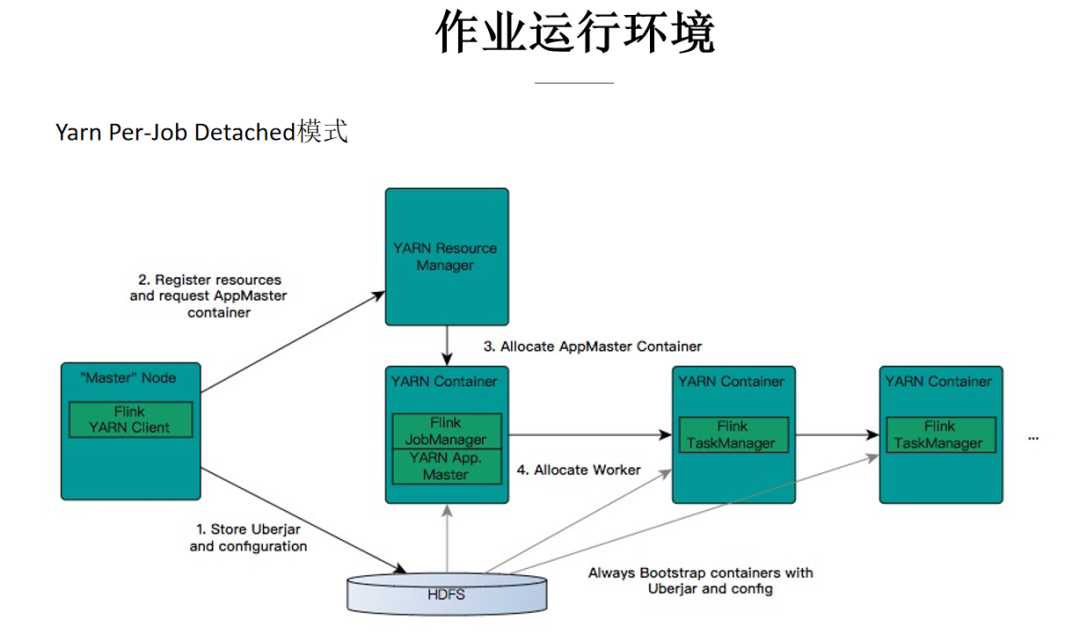
第1步,作業提交是通過 Flink Yarn Client,將用戶所寫的作業代碼以及編譯好的 jar 包上傳到 HDFS 上;
第2步 Flink Client 與 Yarn ResourceManager 進行通信,申請所需要的的 Container 資源;
第3步,ResourceManager 收到請求后會在集群中的 NodeManager 分配啟動 AppMaster 的 Container 進程,AppMaster 中包含 Flink JobManager 模塊和 Yarn 通信的 ResourceManager 模塊;
第4步,在 JobManager 中根據作業的 JobGraph 生成 Execution Graph,ResourceManager 模塊向 Yarn 的 ResourceManager 通信,申請 TaskManager 需要的 container 資源,這些 container 由 Yarn 的 NodeManger 負責拉起。每個 NodeManager 從 HDFS 上下載資源,啟動 Container(TaskManager),并向 JobManager 注冊;JobManger 會部署不同的 task 任務到各個 TaskManager 中執行。
指定資源大小
提交時,指定每個 TaskManager、JobManager 使用多少內存,CPU 資源。
細粒度資源控制
阿里巴巴集團內主要采用 ResourceSpec 方式指定每個 Operator 所需的資源大小,依據 task 的并發聚合成 container 資源向 Yarn 申請。
JM 高可用,AppMaster(JobManager) 異常后,可以通過 Yarn 的 APP attempt 與 ZooKeeper 機制來保證高可用;
數據高可用,作業做 checkpoint 時,TaskManager 優先寫本地磁盤,同時異步寫到 HDFS;當作業再次啟動時可以從 HDFS 上恢復到上次 checkpoint 的點位繼續作業流程。
Processing time
Processing time 是指 task 處理數據時所在機器的系統時間
Event time
Event time 是指數據當中某一數據列的時間
Ingestion time
Ingestion time 是指在 flink source 節點收到這條數據時的系統系統時間
自定義 Source 源解析中加入 Gauge 類型指標埋點,匯報如下指標:
記錄最新的一條數據中的 event time,在匯報指標時使用當前系統時間 - event time。
記錄讀取到數據的系統時間-數據中的 event time,直接匯報差值。
delay = 當前系統時間 – 數據事件時間(event time)
說明:反應處理數據的進度情況。
fetch_delay = 讀取到數據的系統時間- 數據事件時間(event time)
說明:反應實時計算的實際處理能力。
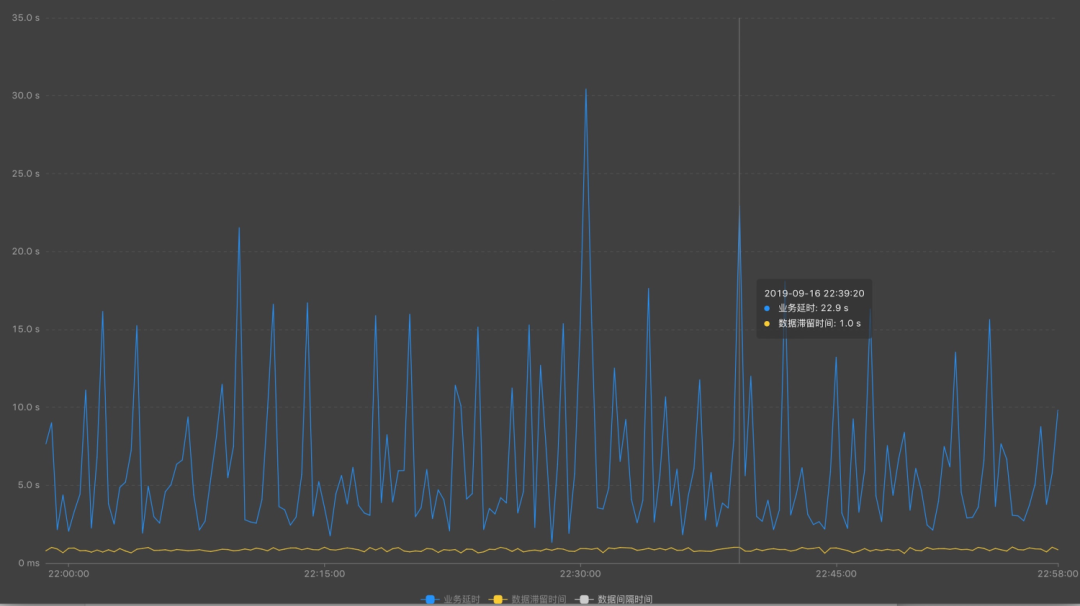
從上游源頭,查看每個源頭并發情況
是否上游數據稀疏導致
作業性能問題

Flink Failover 主要有兩類,一類是 Job Manager 的 Failover,還有一類是 Task Manager 的 Failover。
Yarn 問題 – 資源限制
HDFS 問題 - Jar 包過大,HDFS 異常
JobManager 資源不足,無法響應 TM 注冊
TaskManager 啟動過程中異常
重啟策略配置錯誤
重啟次數達到上限
2.處理方式
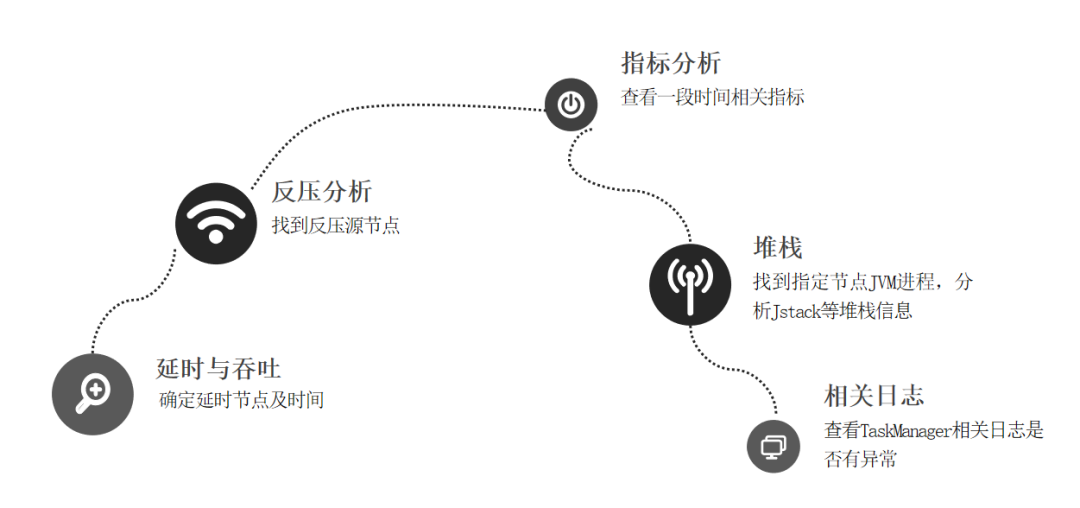
通過 delay、fetch_delay 判斷是否上游稀疏導致延時或者作業性能不足導致延時
確定延時后,通過反壓分析,找到反壓節點
分析反壓節點指標參數
通過分析 JVM 進程或者堆棧信息
通過查看 TaskManager 等日志
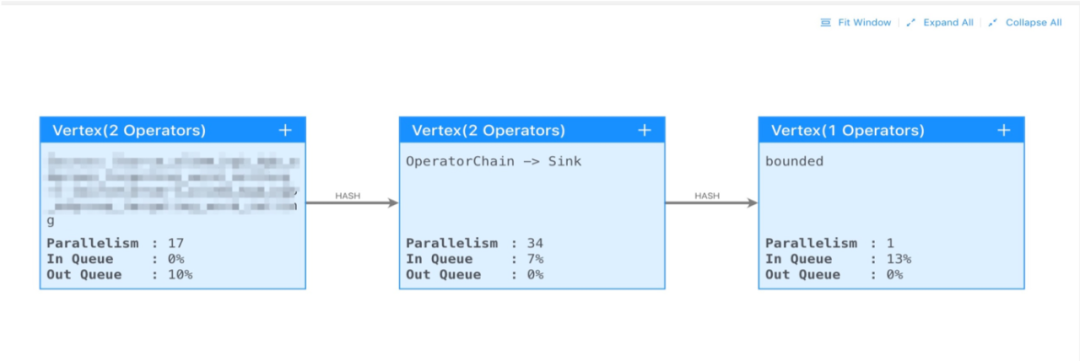
觀察延時與 tps 指標之間關聯,是否由于 tps 的異常增高,導致作業性能不足延時
找到反壓的源頭。
節點之間的數據傳輸方式 shuffle/rebalance/hash。
節點各并發的吞吐情況,反壓是不是由于數據傾斜導致。
業務邏輯,是否有正則,外部系統訪問等。IO/CPU 瓶頸,導致節點的性能不足。
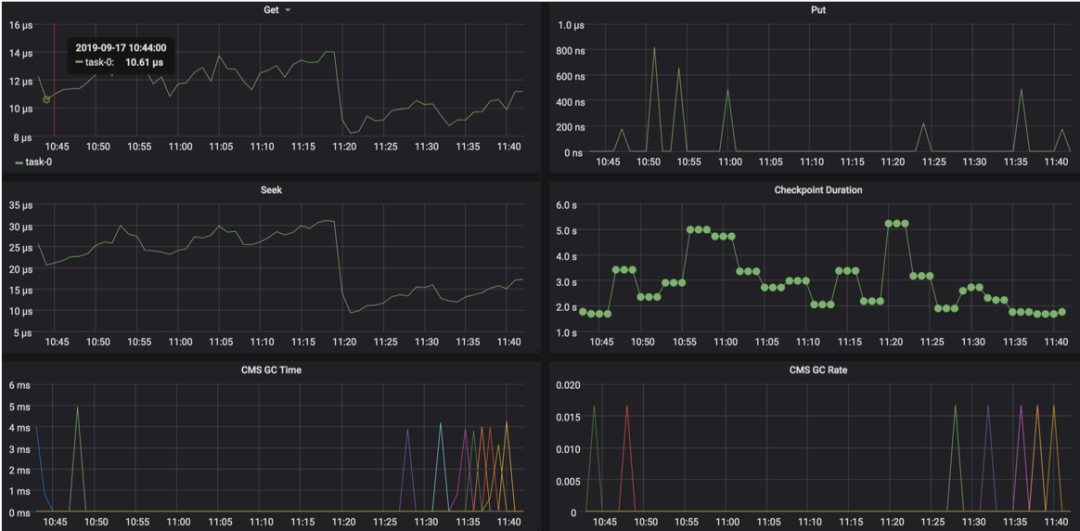
GC 耗時多長
短時間內多次 GC
state 本地磁盤的 IO 情況
外部系統訪問延時等等
在 TaskManager 所在節點,查看線程 TID、CPU 使用情況,確定是 CPU,還是 IO 問題。
ps H -p ${javapid} -o user,pid,ppid,tid,time,%cpu,cmd#轉換為16進制后查看tid具體堆棧jstack ${javapid} > jstack.log

增加反壓節點的并發數。
調整節點資源,增加 CPU,內存。
拆分節點,將 chain 起來的消耗資源較多的 operator 拆分。
作業或集群優化,通過主鍵打散,數據去重,數據傾斜,GC 參數,Jobmanager 參數等方式調優。
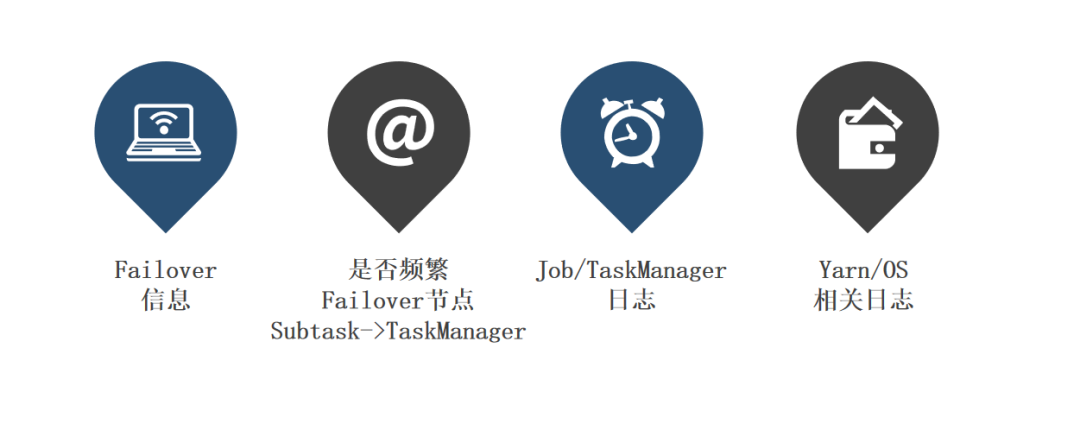
查看作業 failover 時打印的一些日志信息
查看 failover 的 Subtask 找到所在 Taskmanager 節點
結合 Job/Taskmanager 等日志信息
結合 Yarn 和 OS 等相關日志
3.作業生命周期
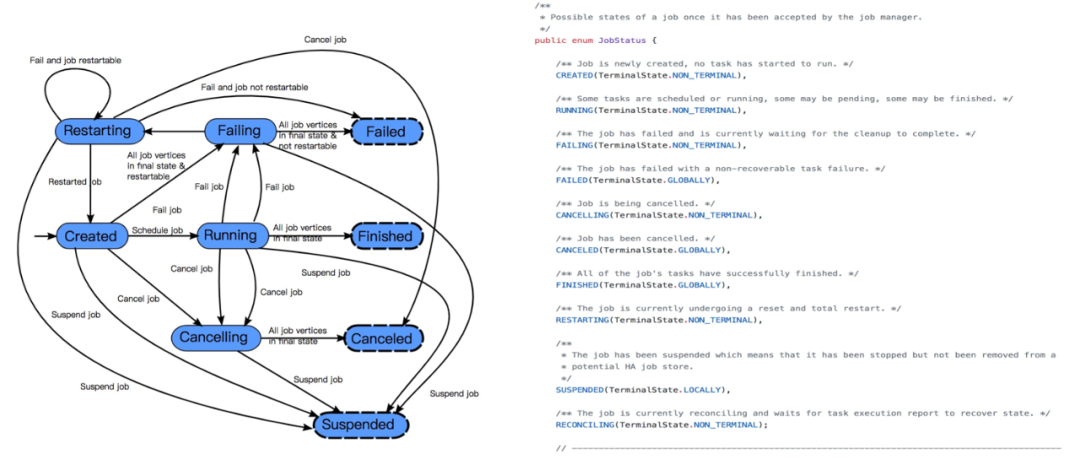
上圖中可以看到作業的整個狀態轉換。從作業創建、到運行、失敗,重啟,成功等整個生命周期。
這里需要注意的是 reconciling 的狀態,這個狀態表示 yarn 中 AppMaster 重新啟動,恢復其中的 JobManager 模塊,這個作業會從 created 進入到 reconciling 的狀態,等待其他 Taskmanager 匯報,恢復 JobManager 的 failover,然后從 reconciling 再到正常 running。
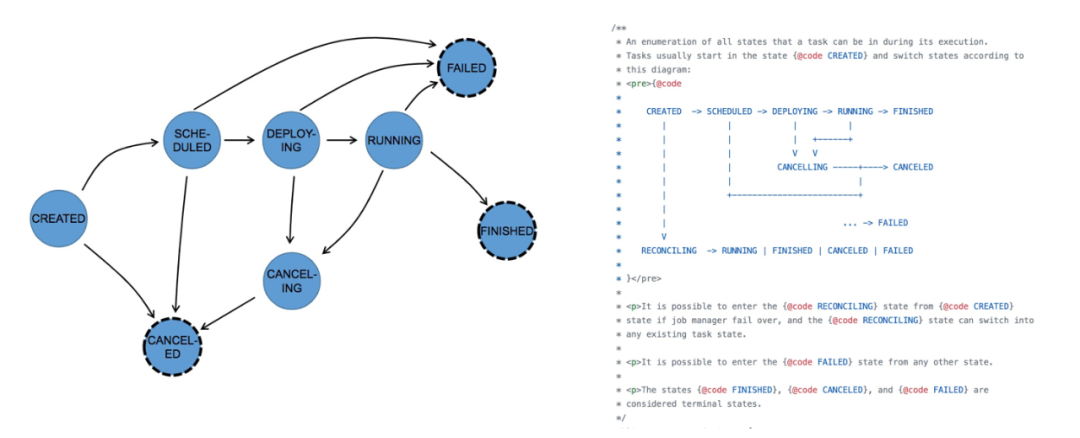
上圖是作業的 Task 狀態轉換,需要注意的是,作業狀態處于 running 狀態時,并不意味著作業一定在運行消費信息。在流式計算中只有等所有的 task 都在 running 時,作業才算真正運行。
通過記錄作業各個階段的狀態變化,形成生命周期,我們能很清楚地展示作業是什么時候開始運行、什么時候失敗,以及 taskmanager failover 等關鍵事件,進一步能分析出集群中有多少個作業正在運行,形成 SLA 標準。
4.工具化經驗
如何去衡量一個作業是否正常?
延時與吞吐
對于 Flink 作業來說,最關鍵的指標就是延時和吞吐。在多少 TPS 水位的情況下,作業才會開始延時.
外部系統調用
從指標上還可以建立對外部系統調用的耗時統計,比如說維表 join,sink 寫入到外部系統需要消耗多少時間,有助于我們排除外部的一些系統異常的一些因素。
基線管理
建立指標基線管理。比如說 state 訪問耗時,平時沒有延時的時候,state 訪問耗時是多少?每個 checkpoint 的數據量大概是多少?在異常情況下,這些都有助于我們對 Flink 的作業的問題進行排查。
錯誤日志
JobManager 或者 TaskManager 的關鍵字及錯誤日志報警。
事件日志
JobManager 或者 TaskManager 的狀態變化形成關鍵事件記錄。
歷史日志收集
當作業結束后,想要分析問題,需要從 Yarn 的 History Server 或已經采集的日志系統中找歷史信息。
日志分析
有了 JobManager,TaskManager 的日志之后,可以對常見的 failover 類型進行聚類,標注出一些常見的 failover,比如說 OOM 或者一些常見的上下游訪問的錯誤等等。
作業指標/事件 - Taskmanager,JobManager
Yarn 事件 - 資源搶占,NodeManager Decommission
機器異常 - 宕機、替換
Failover 日志聚類
在做了這些指標和日志的處理之后,可以對各組件的事件進行關聯,比如說當 TaskManager failover 時,有可能是因為機器的異常。也可以通過 Flink 作業解析 Yarn 的事件,關聯作業與 Container 資源搶占,NodeManager 下線的事件等。
關于Flink的常見問題診斷思路是什么問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





