溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python Spark的實現原理是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
Spark主要是由Scala語言開發,為了方便和其他系統集成而不引入scala相關依賴,部分實現使用Java語言開發,例如External Shuffle Service等。總體來說,Spark是由JVM語言實現,會運行在JVM中。然而,Spark除了提供Scala/Java開發接口外,還提供了Python、R等語言的開發接口,為了保證Spark核心實現的獨立性,Spark僅在外圍做包裝,實現對不同語言的開發支持,下面主要介紹Python Spark的實現原理,剖析pyspark應用程序是如何運行起來的。
首先我們先回顧下Spark的基本運行時架構,如下圖所示,其中橙色部分表示為JVM,Spark應用程序運行時主要分為Driver和Executor,Driver負載總體調度及UI展示,Executor負責Task運行,Spark可以部署在多種資源管理系統中,例如Yarn、Mesos等,同時Spark自身也實現了一種簡單的Standalone(獨立部署)資源管理系統,可以不用借助其他資源管理系統即可運行。
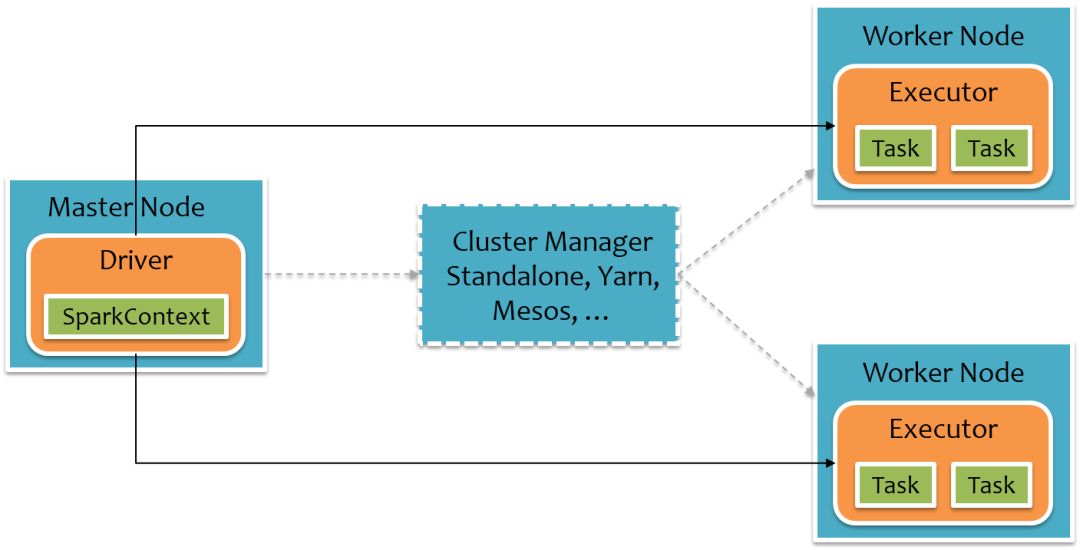
用戶的Spark應用程序運行在Driver上(某種程度上說,用戶的程序就是Spark Driver程序),經過Spark調度封裝成一個個Task,再將這些Task信息發給Executor執行,Task信息包括代碼邏輯以及數據信息,Executor不直接運行用戶的代碼。
為了不破壞Spark已有的運行時架構,Spark在外圍包裝一層Python API,借助Py4j實現Python和Java的交互,進而實現通過Python編寫Spark應用程序,其運行時架構如下圖所示。
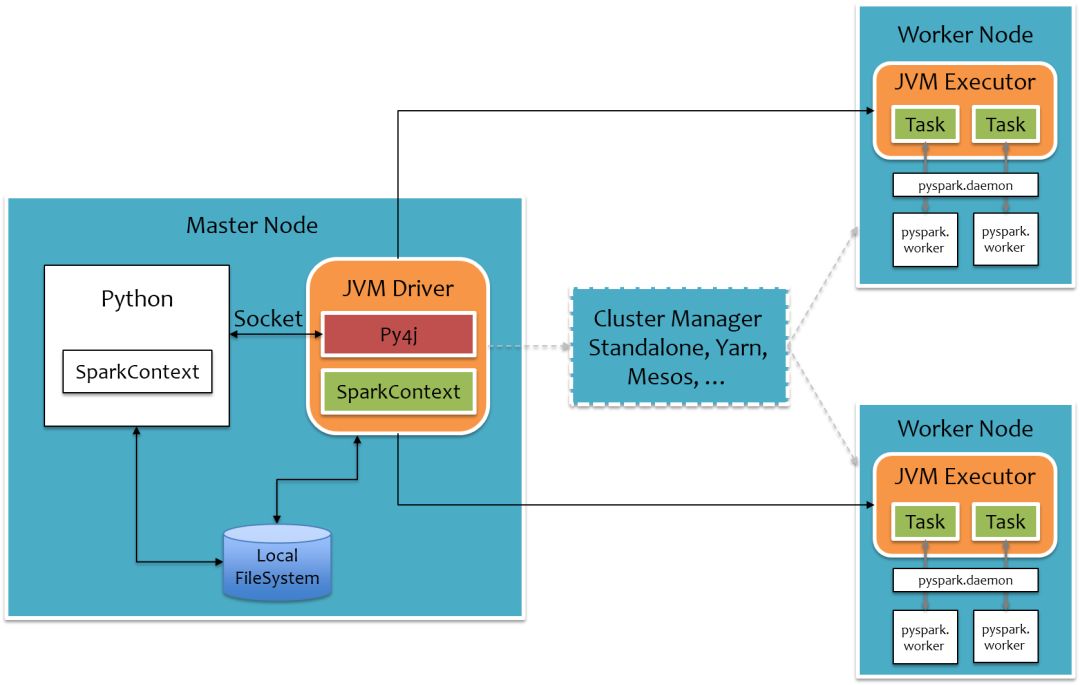
其中白色部分是新增的Python進程,在Driver端,通過Py4j實現在Python中調用Java的方法,即將用戶寫的PySpark程序”映射”到JVM中,例如,用戶在PySpark中實例化一個Python的SparkContext對象,最終會在JVM中實例化Scala的SparkContext對象;在Executor端,則不需要借助Py4j,因為Executor端運行的Task邏輯是由Driver發過來的,那是序列化后的字節碼,雖然里面可能包含有用戶定義的Python函數或Lambda表達式,Py4j并不能實現在Java里調用Python的方法,為了能在Executor端運行用戶定義的Python函數或Lambda表達式,則需要為每個Task單獨啟一個Python進程,通過socket通信方式將Python函數或Lambda表達式發給Python進程執行。語言層面的交互總體流程如下圖所示,實線表示方法調用,虛線表示結果返回。

下面分別詳細剖析PySpark的Driver是如何運行起來的以及Executor是如何運行Task的。
當我們通過spark-submmit提交pyspark程序,首先會上傳python腳本及依賴,并申請Driver資源,當申請到Driver資源后,會通過PythonRunner(其中有main方法)拉起JVM,如下圖所示。
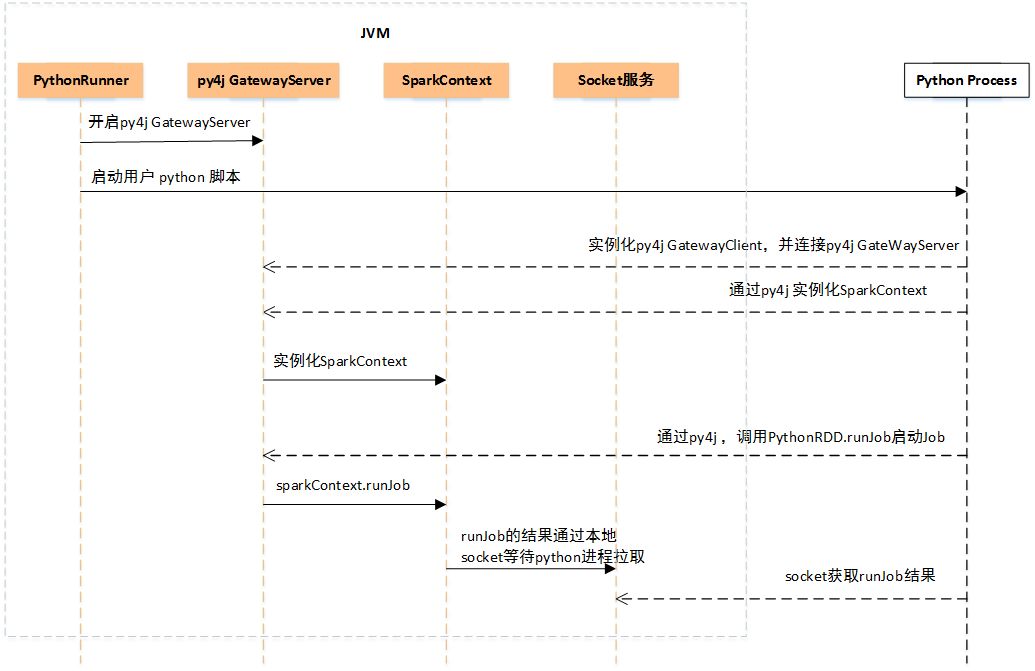
PythonRunner入口main函數里主要做兩件事:
開啟Py4j GatewayServer
通過Java Process方式運行用戶上傳的Python腳本
用戶Python腳本起來后,首先會實例化Python版的SparkContext對象,在實例化過程中會做兩件事:
實例化Py4j GatewayClient,連接JVM中的Py4j GatewayServer,后續在Python中調用Java的方法都是借助這個Py4j Gateway
通過Py4j Gateway在JVM中實例化SparkContext對象
經過上面兩步后,SparkContext對象初始化完畢,Driver已經起來了,開始申請Executor資源,同時開始調度任務。用戶Python腳本中定義的一系列處理邏輯最終遇到action方法后會觸發Job的提交,提交Job時是直接通過Py4j調用Java的PythonRDD.runJob方法完成,映射到JVM中,會轉給sparkContext.runJob方法,Job運行完成后,JVM中會開啟一個本地Socket等待Python進程拉取,對應地,Python進程在調用PythonRDD.runJob后就會通過Socket去拉取結果。
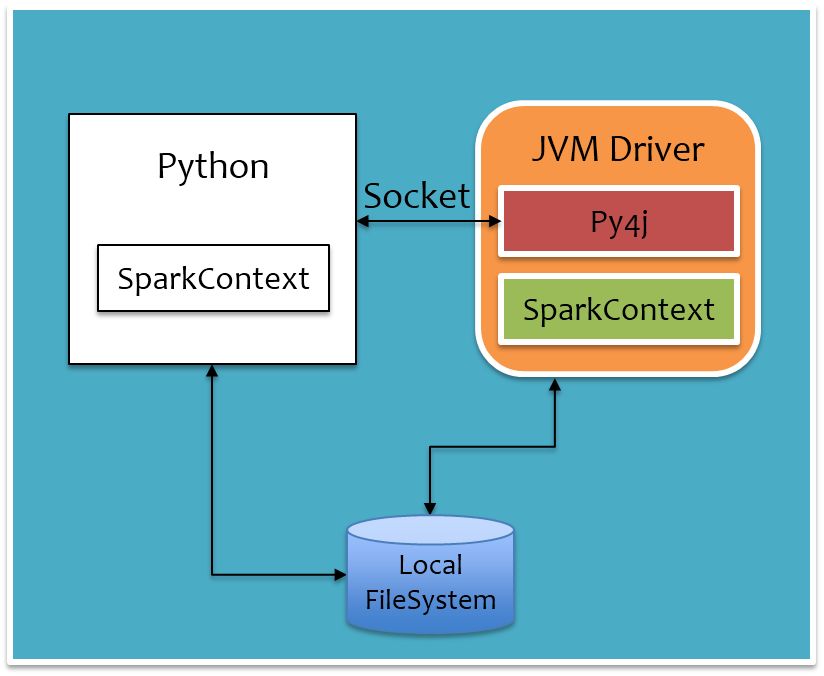
把前面運行時架構圖中Driver部分單獨拉出來,如下圖所示,通過PythonRunner入口main函數拉起JVM和Python進程,JVM進程對應下圖橙色部分,Python進程對應下圖白色部分。Python進程通過Py4j調用Java方法提交Job,Job運行結果通過本地Socket被拉取到Python進程。還有一點是,對于大數據量,例如廣播變量等,Python進程和JVM進程是通過本地文件系統來交互,以減少進程間的數據傳輸。
為了方便闡述,以Spark On Yarn為例,當Driver申請到Executor資源時,會通過CoarseGrainedExecutorBackend(其中有main方法)拉起JVM,啟動一些必要的服務后等待Driver的Task下發,在還沒有Task下發過來時,Executor端是沒有Python進程的。當收到Driver下發過來的Task后,Executor的內部運行過程如下圖所示。
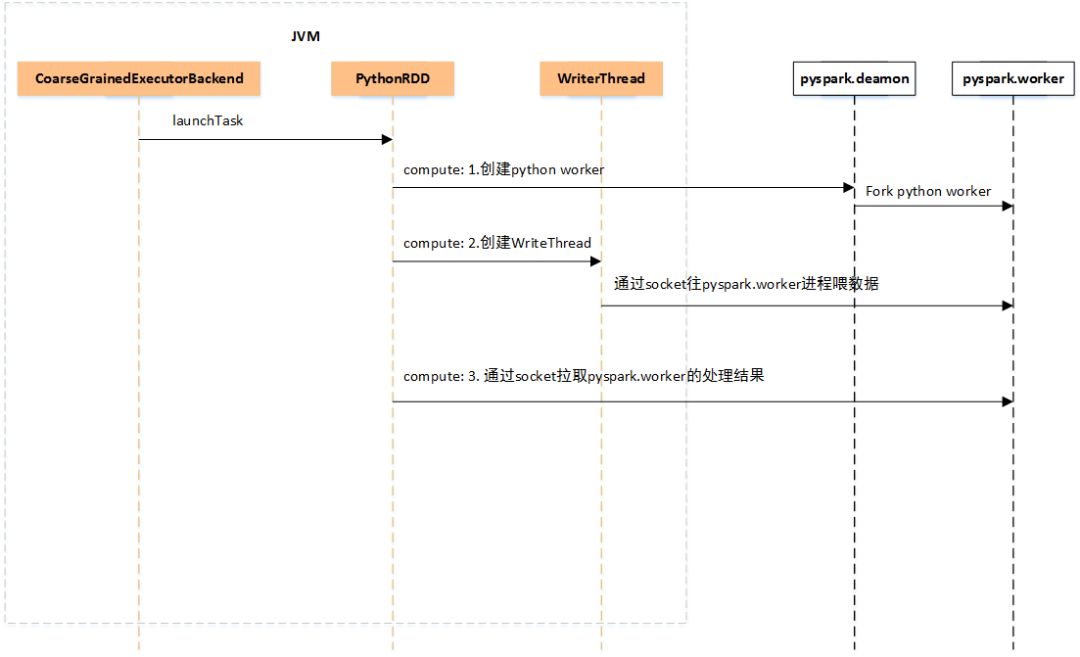
Executor端收到Task后,會通過launchTask運行Task,最后會調用到PythonRDD的compute方法,來處理一個分區的數據,PythonRDD的compute方法的計算流程大致分三步走:
如果不存在pyspark.deamon后臺Python進程,那么通過Java Process的方式啟動pyspark.deamon后臺進程,注意每個Executor上只會有一個pyspark.deamon后臺進程,否則,直接通過Socket連接pyspark.deamon,請求開啟一個pyspark.worker進程運行用戶定義的Python函數或Lambda表達式。pyspark.deamon是一個典型的多進程服務器,來一個Socket請求,fork一個pyspark.worker進程處理,一個Executor上同時運行多少個Task,就會有多少個對應的pyspark.worker進程。
緊接著會單獨開一個線程,給pyspark.worker進程喂數據,pyspark.worker則會調用用戶定義的Python函數或Lambda表達式處理計算。
在一邊喂數據的過程中,另一邊則通過Socket去拉取pyspark.worker的計算結果。
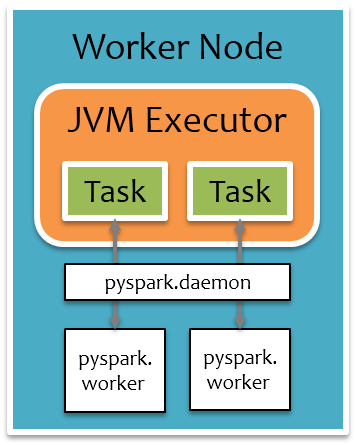
把前面運行時架構圖中Executor部分單獨拉出來,如下圖所示,橙色部分為JVM進程,白色部分為Python進程,每個Executor上有一個公共的pyspark.deamon進程,負責接收Task請求,并fork pyspark.worker進程單獨處理每個Task,實際數據處理過程中,pyspark.worker進程和JVM Task會較頻繁地進行本地Socket數據通信。
總體上來說,PySpark是借助Py4j實現Python調用Java,來驅動Spark應用程序,本質上主要還是JVM runtime,Java到Python的結果返回是通過本地Socket完成。雖然這種架構保證了Spark核心代碼的獨立性,但是在大數據場景下,JVM和Python進程間頻繁的數據通信導致其性能損耗較多,惡劣時還可能會直接卡死,所以建議對于大規模機器學習或者Streaming應用場景還是慎用PySpark,盡量使用原生的Scala/Java編寫應用程序,對于中小規模數據量下的簡單離線任務,可以使用PySpark快速部署提交。
看完上述內容,你們掌握Python Spark的實現原理是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





