溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何進行損失函數losses分析,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
一般來說,監督學習的目標函數由損失函數和正則化項組成。(Objective = Loss + Regularization)
對于keras模型,目標函數中的正則化項一般在各層中指定,例如使用Dense的 kernel_regularizer 和 bias_regularizer等參數指定權重使用l1或者l2正則化項,此外還可以用kernel_constraint 和 bias_constraint等參數約束權重的取值范圍,這也是一種正則化手段。
損失函數在模型編譯時候指定。對于回歸模型,通常使用的損失函數是平方損失函數 mean_squared_error。
對于二分類模型,通常使用的是二元交叉熵損失函數 binary_crossentropy。
對于多分類模型,如果label是類別序號編碼的,則使用類別交叉熵損失函數 categorical_crossentropy。如果label進行了one-hot編碼,則需要使用稀疏類別交叉熵損失函數 sparse_categorical_crossentropy。
如果有需要,也可以自定義損失函數,自定義損失函數需要接收兩個張量y_true,y_pred作為輸入參數,并輸出一個標量作為損失函數值。
對于keras模型,目標函數中的正則化項一般在各層中指定,損失函數在模型編譯時候指定。
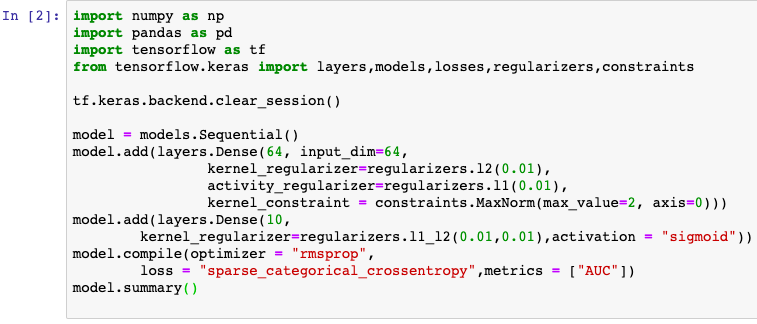

內置的損失函數一般有類的實現和函數的實現兩種形式。
如:CategoricalCrossentropy 和 categorical_crossentropy 都是類別交叉熵損失函數,前者是類的實現形式,后者是函數的實現形式。
常用的一些內置損失函數說明如下。
mean_squared_error(平方差誤差損失,用于回歸,簡寫為 mse, 類實現形式為 MeanSquaredError 和 MSE)
mean_absolute_error (絕對值誤差損失,用于回歸,簡寫為 mae, 類實現形式為 MeanAbsoluteError 和 MAE)
mean_absolute_percentage_error (平均百分比誤差損失,用于回歸,簡寫為 mape, 類實現形式為 MeanAbsolutePercentageError 和 MAPE)
Huber(Huber損失,只有類實現形式,用于回歸,介于mse和mae之間,對異常值比較魯棒,相對mse有一定的優勢)
binary_crossentropy(二元交叉熵,用于二分類,類實現形式為 BinaryCrossentropy)
categorical_crossentropy(類別交叉熵,用于多分類,要求label為onehot編碼,類實現形式為 CategoricalCrossentropy)
sparse_categorical_crossentropy(稀疏類別交叉熵,用于多分類,要求label為序號編碼形式,類實現形式為 SparseCategoricalCrossentropy)
hinge(合頁損失函數,用于二分類,最著名的應用是作為支持向量機SVM的損失函數,類實現形式為 Hinge)
kld(相對熵損失,也叫KL散度,常用于最大期望算法EM的損失函數,兩個概率分布差異的一種信息度量。類實現形式為 KLDivergence 或 KLD)
cosine_similarity(余弦相似度,可用于多分類,類實現形式為 CosineSimilarity)
自定義損失函數接收兩個張量y_true,y_pred作為輸入參數,并輸出一個標量作為損失函數值。
也可以對tf.keras.losses.Loss進行子類化,重寫call方法實現損失的計算邏輯,從而得到損失函數的類的實現。
下面是一個Focal Loss的自定義實現示范。Focal Loss是一種對binary_crossentropy的改進損失函數形式。
在類別不平衡和存在難以訓練樣本的情形下相對于二元交叉熵能夠取得更好的效果。
詳見《如何評價Kaiming的Focal Loss for Dense Object Detection?》
https://www.zhihu.com/question/63581984

關于如何進行損失函數losses分析就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





