溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“r語言怎么進行單因素方差分析”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“r語言怎么進行單因素方差分析”文章能幫助大家解決問題。
library(agricolae)
data(sweetpotato)可以看到, 數據為兩列, 第一列為不同病毒的類型, 第二列為產量, 為了研究不同病毒感染對產量的影響.
> head(sweetpotato)
virus yield
1 cc 28.5
2 cc 21.7
3 cc 23.0
4 fc 14.9
5 fc 10.6
6 fc 13.1因素: virus
變量: yield
model<-aov(yield~virus, data=sweetpotato)
summary(model)可以看到不同病毒達到顯著性水平.
> summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
virus 3 1170.2 390.1 17.34 0.000733 ***
Residuals 8 179.9 22.5
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1這里多重比較采用LSD方法.
out <- LSD.test(model,"virus", p.adj="bonferroni")
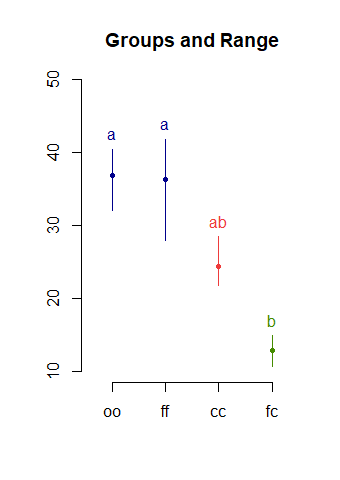
out$groups結果可以看到, oo, ff,cc之間不顯著(都有a), oo,ff與fc之間顯著(字母沒有交集).
> out$groups
yield groups
oo 36.90000 a
ff 36.33333 a
cc 24.40000 ab
fc 12.86667 bplot(out)
關于“r語言怎么進行單因素方差分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





