溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark2.x中Shuffle演進歷程及Shuffle兩階段劃分是這樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一、概述
我自己也去看了Spark2.2.0的源碼,在Spark-env初始化中只保留了兩種Shuffle:Sort、Tungsten-Sort,下面是源碼截圖:
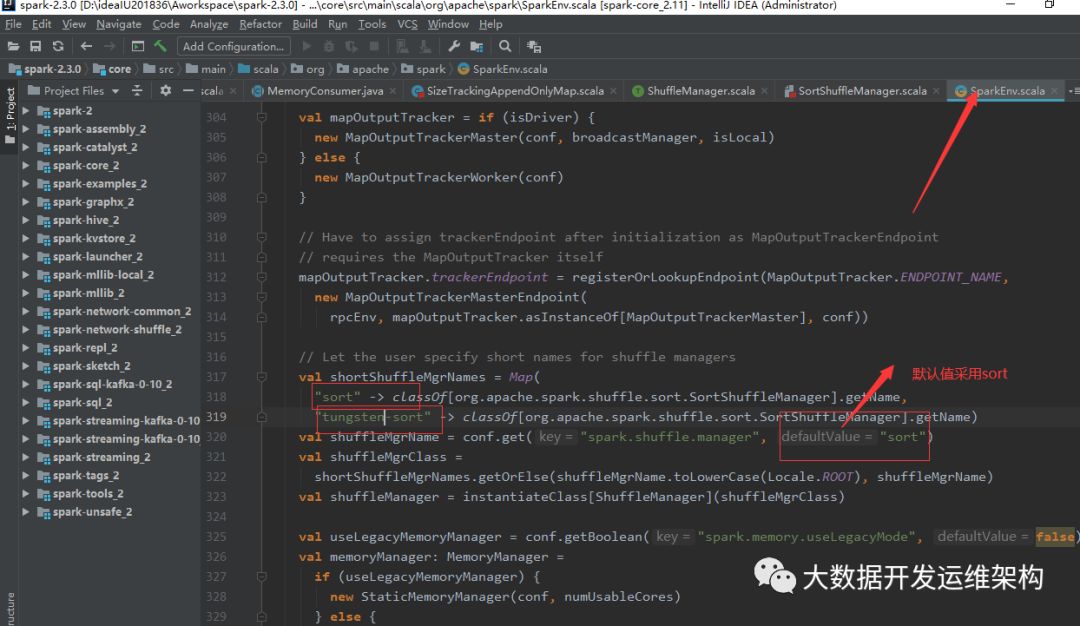
由于Spark Shuffle是Spark的核心之核心,為了對Spark Shuffle有更全面的認識,這里先來講解一下Spark的技術演進歷程及Shuffle階段換分。
二、Spark Shuffle技術演進歷程
1.Spark0.8以前,都是采用的HashShuffle,這是最開始的Shuffle,會存在生成很多小文件的問題,文件數M*R,其中M表示ShuffleMapTask個數,R表示Result個數;
2.Spark0.8.1中,引入了Consolidation優化機制,減少了小文件的生產,文件數變成了E*(C/T)*R,其中E表示Executor個數,C表示每個Executor中可用Core的個數,T表示Task所分配的Core的個數(默認值為1)。
3.Spark 0.9 中,引入ExternalAppendOnlyMap,combine的時候,可以將數據spill到磁盤,然后通過堆排序merge;
4.Spark 1.1 引入Sort Based Shuffle,但默認仍為Hash Based Shuffle,稍后會詳解這種機制;
5.Spark 1.2 默認的Shuffle方式改為Sort Based Shuffle;
6.Spark 1.4 引入Tungsten-Sort Based Shuffle,將數據記錄用序列化的二進制方式存儲,把排序轉化成指針數組的排序,引入堆外內存空間和新的內存管理模型,這些技術決定了使用Tungsten-Sort要符合一些嚴格的限制,比如Shuffle dependency不能帶有aggregation、輸出不能排序等。由于堆外內存的管理基于JDK Sun Unsafe API,故Tungsten-Sort Based Shuffle也被稱為Unsafe Shuffle;
7.Spark 1.6 Tungsten-sort并入Sort Based Shuffle;
8.Spark 2.0 Hash Based Shuffle被啟用,Sort Based Shuffle成為默認Shuffle機制。
三、Spark Shuffle的兩階段
Spark中有寬依賴、窄依賴兩種,寬依賴會觸發Stage的劃分,這時候需要進行Shuffle,需要對RDD中的每個Paritioon數據進行重新分區,Spark Shuffle主要分成了兩個階段:Shuffle Write、Shuffle Read,兩個階段分屬兩個人Stage,前者屬于父Stage,后者屬于子Stage。
結合上篇文章的圖我這里給他用不同顏色進行了標識,上面的部分是stage1中的ShuffleWrite負責Shuffle階段數據寫,下面就是stage0的中的ShuffleWrite負責Shuffle階段數據讀,如圖所示:
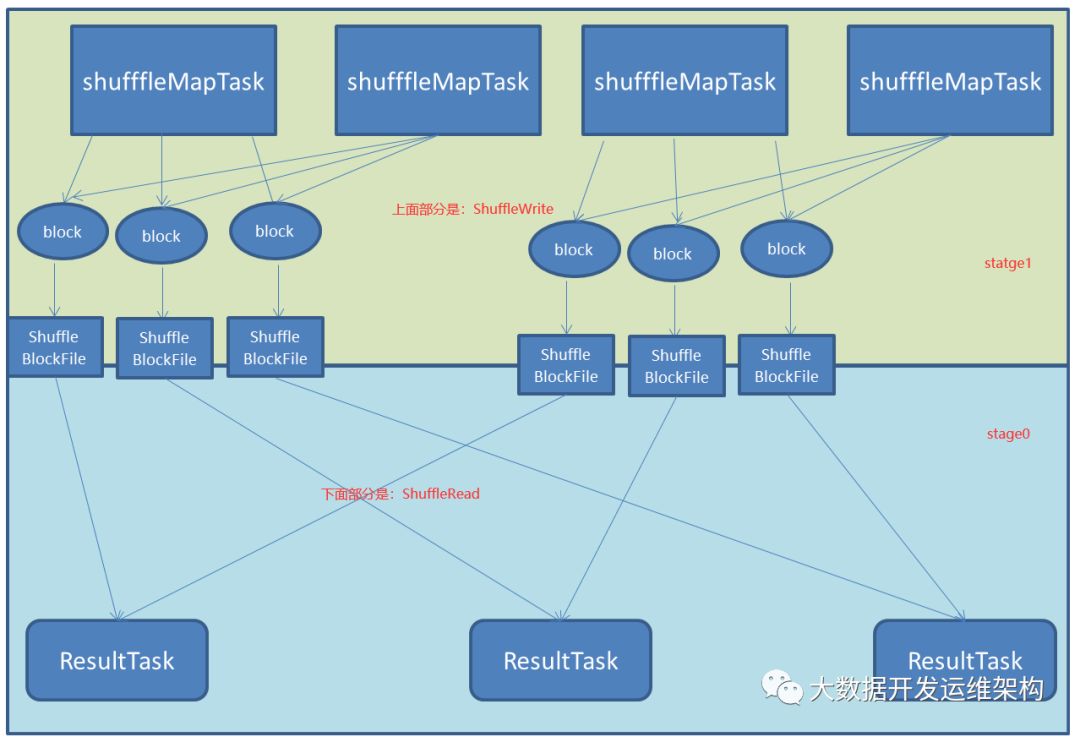
這里有一點需要說明一下:如果要按照map端和reduce端來分析的話,ShuffleMapTask可以即是map端任務,又是reduce端任務,因為Spark中的Shuffle是可以串行的;ResultTask則只能充當reduce端任務的角色。
Shuffle Write階段
shuffle write階段,主要就是在一個stage結束計算之后,為了下一個stage可以執行shuffle類的算子(比如reduceByKey),而將每個task處理的數據按key進行“分類”。所謂“分類”,就是對相同的key執行hash算法,從而將相同key都寫入同一個磁盤文件中,而每一個磁盤文件都只屬于下游stage的一個task。在將數據寫入磁盤之前,會先將數據寫入內存緩沖中,當內存緩沖填滿之后,才會溢寫到磁盤文件中去。
Shuffle Read階段
shuffle read,通常就是一個stage剛開始時要做的事情。此時該stage的每一個task就需要將上一個stage的計算結果中的所有相同key,從各個節點上通過網絡都拉取到自己所在的節點上,然后進行key的聚合或連接等操作。由于shuffle write的過程中,task為下游stage的每個task都創建了一個磁盤文件,因此shuffle read的過程中,每個task只要從上游stage的所有task所在節點上,拉取屬于自己的那一個磁盤文件即可。
shuffle read的拉取過程是一邊拉取一邊進行聚合的。每個shuffle read task都會有一個自己的buffer緩沖,每次都只能拉取與buffer緩沖相同大小的數據,然后通過內存中的一個Map進行聚合等操作。聚合完一批數據后,再拉取下一批數據,并放到buffer緩沖中進行聚合操作。以此類推,直到最后將所有數據到拉取完,并得到最終的結果。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





