溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
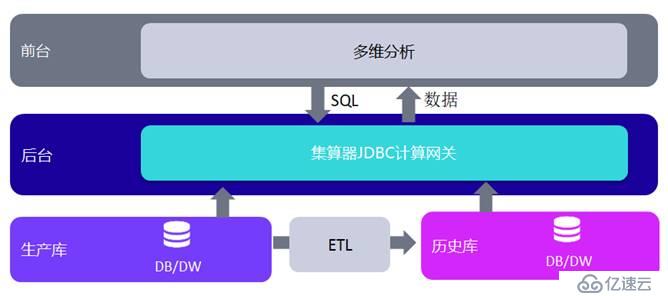
多維分析(BI)系統后臺數據常常可能來自多個數據庫,這時就會出現跨庫取數計算的問題。
例如:從性能和成本考慮,往往會限制生產庫的容量,同時將歷史數據分庫存放,由ETL定期把生產庫中新產生的數據同步到歷史庫中,同步周期根據數據的生成量,可能是1天、一周或者一個月。如果多維分析系統僅僅連上歷史庫取數,那么用戶就只能對歷史數據做分析,也就是實現T+1、T+7、T+30的多維分析。如果想要實現T+0的實時分析,就要從生產庫和歷史庫分別取得數據進行計算并最終合并結果。很多時候,生產庫和歷史庫還是異構的數據庫,很難直接做跨庫混合運算。
即使不是T+0場景,歷史數據量很大時也可能分成多個數據庫存儲,而且也會是是異構數據庫的情況。這時,多維分析系統也需要從多個不同數據倉庫中取數、計算、合并結果展現。
作為數據計算中間件(DCM),構建數據前置層是集算器的重要應用模式。集算器具備可編程網關機制,可以同時連上多個數據庫取數,并將結果合并提交給前臺展現。
在下面的案例中,多維分析系統要針對訂單數據做自助分析。為了簡化起見,我們采用了以下模擬環境:
l 多維分析系統前臺用tomcat服務器中的jdbc.jsp進行模擬。Tomcat安裝在windows操作系統的C:\tomcat6。
l 集算器JDBC集成在多維分析應用中。jdbc.jsp模仿多維分析應用系統,產生符合集算器規范的SQL,通過集算器JDBC提交給集算器SPL腳本處理。
l 多維分析系統的數據一部分來自于生產數據庫(Oracle數據庫) demo中的ORDERS表,另一部分來自歷史庫(Mysql數據庫)test。當天數據連接生產庫取數,實現實時分析。
l ETL過程每天將當天的最新數據同步到歷史庫中。日期以訂購日期ORDERDATE為準,假設當前的日期是2015-07-18。ORDERDATE的開始和結束日期是多方位分析的必選條件。
案例中包含生產庫和1個歷史庫,實際上集算器也支持一個生產庫和同時多個歷史庫,或者沒有生產庫但有多個歷史庫的情況。
用下面的sql文件在ORACLE數據庫中完成ORDERS表的建表和數據初始化。
配置文件在 classes 中,在官網上獲取的授權文件也要放在 classes 目錄中。集算器的 Jar 包要放在 lib 目錄中(需要哪些 jar 請參照集算器教程)。
修改 raqsoftConfig.xml 中的主目錄配置:
<mainPath>C:\tomcat6\webapps\CrossDB\WEB-INF\dfx</mainPath>
<JDBC>
<load>Runtime,Server</load>
<gateway> CrossDB.dfx</gateway>
</JDBC>
2、 編輯 CrossDB 目錄中的 jdbc.jsp,模擬前臺界面提交 sql 展現結果。
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql =" select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100 ";
out.println("Test page v1<br><br><br><pre>");
out.println("訂單 ID"+"\t"+" 客戶 ID"+"\t"+" 雇員 ID"+"\t"+" 訂購日期 "+"\t"+" 訂單金額 "+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\t"+f2+"\t"+f3+"\t"+f4+"\t"+f5+"\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
在 jsp 中,先連接集算器的 JDBC,然后提交執行 SQL。步驟和一般的數據庫完全一樣,具有很高的兼容性和通用性。對于多維分析工具來說,雖然是界面操作來連接 JDBC 和提交 SQL,但是基本原理和 jsp 完全一樣。
3、 打開 dfx 目錄中的 CrossDB.dfx,觀察理解 SPL 代碼。
傳入參數是 sql 例如:
select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100。
SPL腳本如下:
A | B | C | |
1 | =sql.sqlparse@aw() | =A1.pselect("ORDERDATE between*") | |
2 | =substr(A1(B1),"date(") | =substr(A1(B1+1),"date(") | |
3 | =mid(A2,2,10) | =mid(B2,2,10) | |
4 | if between(date(now()),date(A3):date(B3)) | ||
5 | =connect("orcl") | =B5.cursor@dx("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders where orderdate=?",date(now())) | |
6 | =connect("mysql") | =B6.cursor@x("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") | |
7 | =mcs=[C5,C6].mcursor() | =connect().cursor@x("with orders as(mcs)"+sql) | |
8 | return C7 | ||
9 | else | =connect("mysql") | =B9.cursor@x(sql.sqltranslate("MYSQL")) |
10 | return C9 | ||
說明:
A1:解析 SQL,獲取 where 子句,并用空格來拆分成序列。
B1,A2-B3:在 A1 序列找到必選條件訂購日期,獲取開始和結束日期值。
A4:判斷查詢范圍是否包含當前日期。
B5-C6:如果包含當前日期,就連接生產庫和歷史庫,建立取數游標。
B7:用生產庫和歷史庫游標建立多路游標。
C7、B8:對多路游標進行 sql 查詢并返回結果。
A9-C10:如果不包含當前日期,就只連接歷史數據庫。將 SQL 翻譯成符合 MYSQL 數據庫規范的 SQL, 執行 SQL 得到游標并返回。
實際業務中,生產庫一般都有必要保持一些歷史數據,這樣生產庫和歷史庫會有重復數據,所以代碼中需要給生產庫再加上日期條件。如果是多個歷史庫分庫的情況,一般來講,這些庫之間就沒有重復的數據,代碼能夠簡化一些。比如,假設例中的 ORACLE 和 MYSQL 沒有重復數據,則 CrossDB.dfx 的代碼可以簡化如下:
A | B | |
1 | =connect("orcl") | =A1.cursor@dx("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") |
2 | =connect("mysql") | =A2.cursor@x("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") |
3 | =mcs=[B1,B2].mcursor() | =connect().cursor@x("with orders as(mcs)"+sql) |
4 | return B3 |
4、 啟動 tomcat,在瀏覽器中訪問http://localhost:8080/CrossDB/jdbc.jsp,查看結果。
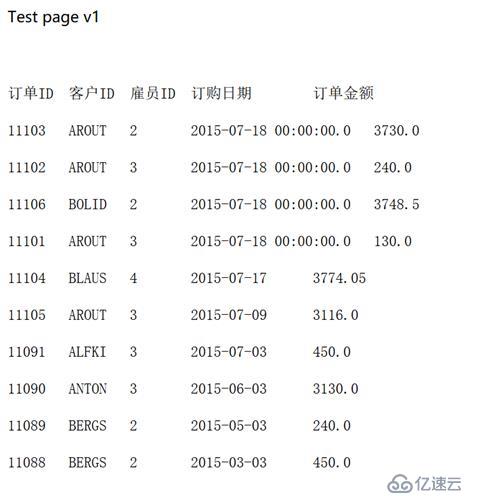
結果中訂購日期格式略有不同,這只需要在多維分析前端設置一下顯示格式即可。
我們還可以繼續測試如下情況:
1、 僅僅查詢歷史庫
sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100";
2、 分組查詢
sql ="select CUSTOMERID,EMPLOYEEID,sum(AMOUNT) S,count(1) C from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') group by CUSTOMERID,EMPLOYEEID"
在這個案例中,集算器SPL腳本還可以承擔ETL的工作。
多維分析系統上線之后,要每天晚上定時同步當天最新的數據。我們假設當天日期是2015-07-18。
SPL語言腳本etl.dfx將當天數據增量補充到歷史庫中,具體腳本如下:
A | |
1 | =connect("orcl") |
2 | =A1.cursor@xd("select ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT from ORDERS where ORDERDATE=?",etlDate) |
3 | =connect("mysql") |
4 | =A3.update@i(B2, ORDERS,ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT) |
5 | >A3.close() |
etl.dfx的輸入參數是etlDate,也就是需要新增的當天日期。
etl.dfx腳本可以用windows或者linux命令行的方式執行,結合定時任務,可以定時執行。也可以用ETL工具來定時調用。
windows命令行的調用方式是:
C:\Program Files\raqsoft\esProc\bin>esprocx.exe C: \etl.dfx 2015-07-18
linux命令是:
/raqsoft/esProc/bin/esprocx.sh /esproc/ etl.dfx 2015-07-18
作為數據計算中間件(DCM),由集算器提供的后臺數據源可以支持各種前端應用,不僅限于前端是多維分析的情況,還可以包括例如大屏展示、管理駕駛艙、實時報表、大數據量清單報表、報表批量訂閱等等場景。
另外,集算器形成的后臺數據源也可以將數據緩存計算。這時,采用集算器實現的數據計算網關和路由,就可以在集算器緩存數據和數據倉庫之間智能切換,從而解決數據倉庫無法滿足的性能要求問題,例如常見的冷熱數據分開計算的場景。(具體做法參見《集算器實現計算路由優化BI后臺性能》)。
在另一些應用中,集算器也可以完全脫離數據庫,起到輕量級多維分析后臺的作用,這時的集算器就相當于獨立的中小型數據倉庫或者數據集市了。(具體做法參見《集算器實現輕量級多維分析后臺》。)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





