溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中怎么利用Mitmproxy爬取公眾號文章,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
將手機端的代理IP設為pc端的IP地址
當我們安裝好證書后,就可以進行如下操作。首先在pc端的開始欄輸入cmd,然后輸入控制命令ipconfig,查看pc端的IP地址,如下圖;
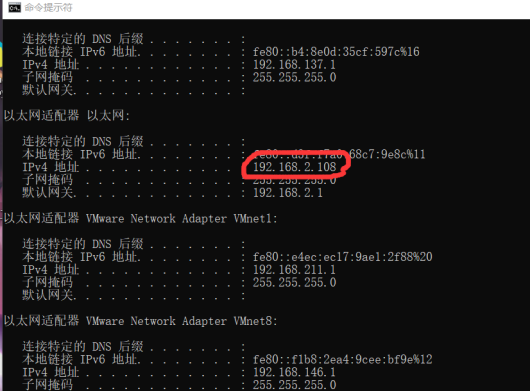
然后在手機端的所連接的wifi選項中打開代理ip手動設置,用戶名填入IPv4地址,端口一般設為8080即可。
爬取文章閱讀信息
完成上述操作后,我們就進行py代碼的如下操作。
代碼修改操作
在參考博客中我們只需要修改wxCrawler.py這個py代碼即可,其余代碼均可不必修改,因為該代碼是爬取文章的關鍵。我們將wxCrawler.py代碼的爬取鏈接改為爬取到的文章的閱讀信息即可;wxCrawler.py在for循環處導入參考博客text_01.py代碼類傳入相應的參數,(參考博客為articles.py代碼);只做這一處修改即可完成爬取公眾號文章閱讀信息。
text_01.py代碼

修改后的wxCrawler.py代碼


運行結果示例:
以該公眾號為例的測試結果圖為;
注意事項
事項1:將所有的py代碼放入同一個文件夾。
事項2:閱讀該博客前,請先閱讀參考博客和關于參考博客難點介紹的那篇博客。
事項3:盡量用pycharm打開文件夾運行py代碼。
事項4:參考博客中的代碼存在代碼縮進,符號等問題,在上一篇博客我已經將其修改完畢,只需要將wxCrawler.py代碼改為修改后的代碼然后加入text_01.py代碼即可。
關于Python中怎么利用Mitmproxy爬取公眾號文章問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





